![[Application & Tips] Data preprocessing](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FqlY6m%2Fbtq4jsrXSAK%2FKFTeDIsLTLAtECSAUO0oik%2Fimg.png)
[TensorFlow] Lab-05-2 Logistic Regression 모두의 딥러닝 시즌 2 정리...
목차
- Learning rate
- Gradient
- Good and Bad Learning rate
- Learning rate schedule 과 Annealing the learning rate (Decay)
- Data preprocessing
- Feature Scaling - Standardization / Normanalization
- Noisy Data
- Overfitting
- Regularization
- L2 Norm
이전 글에서 Learning rate를 이용한 학습 응용을 살펴보았다. 이젠 AI에서 제일 중요한 데이터 전처리에 대해 설명하고자 한다. 데이터 전처리는 머신러닝 과정의 70~80%를 차지하는 중요한 과정이며 얼마나 데이터 전처리가 잘된 데이터를 통해 학습하냐에 따라 Hyper parameter를 찾는 과정보다 더 효과적이라는 말을 어디선가 들었던거 같다.
해당 내용도 너무 중요해서 나중에 따로 정리할 예정이다. 우선은 모두의 딥러닝 강의에 나온 내용만 작성하겠다.
Data preprocessing

Feature Scaling
Feature Scaling이란 Feature들의 크기, 범위를 정규화시켜주는 것을 말한다.
- raw data 를 전처리하는 과정
- 키와 몸무게를 가지고 100m 달리기에 걸리는 시간을 예측한다고 하면, 키와 몸무게는 단위가 다르기 때문에, 더 큰 값을 가진 키 값이 결과값에 더 큰 영향을 미칠 수도 있다.
- 이 때문에 raw data 를 전처리하는 과정이 필요하다.
- 방법론적으로 크게 Min-Max Normalization , Standardization (Z-score Normalization) 두가지가 있다.

위의 그래프에서 왼쪽 그래프를 살펴보자. 왼쪽 그래프의 하단(b)에는 0~1000 사이의 데이터들이 중점적으로 분포되어 있고 소수의 데이터들(a)만이 아~주 큰 값에 분포되어 있다.
그렇다면 이러한 데이터를 바탕으로 머신러닝 모델을 만드는 과정에서 실제 의미가 있는 데이터는 어떤 데이터 일까?
데이터 a, b 를 토대로 학습을 진행할 때 영향을 주는 데이터는 아무래도 많이 분포되어 있는 데이터들이다.
즉 이러한 단위가 다른 데이터들이 정확한 분석을 하기 위해서는 Feature를 서로 정규화시켜 주는 작업이 필요하고 이런한 작업을 Feature Scaling이라고 한다.
오른쪽 그래프 같은 경우가 Feature Scaling을 진행했을 때 분포되는 데이터다.
1) Min-Max Normalization
- 서로 다른 Feature의 크기를 통일하기 위해 크기를 변환해주는 작업
- 데이터를 일반적으로 0~1 사이의 값으로 변환시켜준다.
- 데이터의 최소값, 최대값을 알 경우 사용한다.


2) Standardization (Mean Distance)
- 기존 변수에 범위를 정규 분포로 변환한다.
- 데이터의 최소값, 최대값을 모를 경우 사용한다.
- 평균과의 거리는 구하는 것 (Mean Distance)
- (X - X의 평균값) / (X의 표준편차)

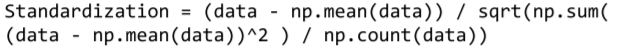
위의 코드는 Numpy를 이용해 식을 작성하였지만 sklearn에는 제공되는 라이브러리가 있다.sklearn으로 Feature Scaling하기
Noisy Data
머신러닝을 하는 것에 있어서 데이터는 너무너무~~중요하다.
그만큼 우리는 noisy data. 즉 쓸모 없는 데이터를 잘 없애주는 것이 중요하다고 할 수 있다.
여기서는 몇가지 예시를 통해 간단하게 설명만 하겠다.
Numeric

수치형 데이터의 경우 데이터의 분포가 이쁘게~잘~수집되면 좋겠지만 그럴 경우는 거의 없다고 본다.
수집되는 Feature의 종류, 단위만큼 데이터 분포가 제각각이다.
위의 데이터에서도 a 같은 경우는 머신러닝 학습에 있어서 중요하지 않고 noisy한 데이터로 취급된다. 그래서 전처리 과정을 통해 오른쪽 그래프처럼 분포하는 것이 중요하다고 볼 수 있다.
NLP
최근에 많이 쓰고 있는 챗봇에서는 자연어 처리를 많이 사용한다.

위와 같은 예시에서 실제 우리가 필요로 하는 글자는 파란색으로 표시된 글자이며 Will, a, ..?? 와 같은 조사나 특수문자는 머신러닝을 학습하는데 있어서 Noisy한 데이터이다.
이 또한 데이터 전처리를 통해 학습에 필요한 데이터만 추출하는 것이 중요하다.
Image

다른 예시로 얼굴 이미지를 이용해 분류 모델을 만든다고 했을 때 위의 사진에서 중요한 부분은 어느 곳일까?
해당 사진에서 사람을 분류하는데 가장 중요한 부분은 얼굴 부분이며 머리 스타일, 귀(귀걸이 할 수도 있잖아?), 배경과 같은 부분은 분류하는데 있어서 쓸모없는 정보이다. (물론 성형?을 할수도 있지만 일반적으로....)
그래서 이 또한 얼굴만 따로 추출하는 데이터 전처리 과정이 필요하다.
위의 예시들처럼 데이터에 따라 전처리하는 과정도 제각각이고 많은 방법이 존재한다.
정리는 와중에 조사하는 부분에 있어서도 너무 많은 방법론이 존재하고 이것들을 다 정리하는 것에는 한계가 있다는 생각을 했다.
그래서 관심있는 분야는 컴퓨터 비전 쪽이므로 해당 부분 이미지 전처리 부분만 나중에 따로 정리할 생각이다.
해당 코드는 Normalization을 적용하지 않는 데이터를 갖고 학습을 진행한 Tensorflow 코드이다.
살펴보면 학습이 제대로 진행되지 않는 모습을 확인할 수 있다.
참고