삽입(Insertion) 정렬
삽입 정렬은 현재 비교하고자 하는 target(타겟)과 그 이전의 원소들과 비교하며 자리를 교환(swap)하는 정렬 방법이다.
삽입 정렬은 데이터를 '비교'하면서 찾기 때문에 '비교 정렬'이며 정렬의 대상이 되는 데이터 외에 추가적인 공간을 필요로 하지 않기 때문에 '제자리 정렬(in-place sort)'이기도 하다. 정확히는 데이터를 서로 교환하는 과정(swap)에서 임시 변수를 필요로 하나, 이는 충분히 무시할 만큼 적은 양이기 때문에 제자리 정렬로 보는 것이다. 이는 선택정렬과도 같은 부분이다.
그리고 이전에 다뤘던 선택 정렬과는 달리 삽입 정렬은 '안정 정렬'이다.
| 특성 | 설명 |
| In-place 알고리즘 | Memory 상에서 필요 시 상호 위치만 변경될 뿐 추가적인 배열 생성이 불 필요함 |
| Stable 알고리즘 | 구현하기 나름이나, 기본적으로 값이 같으면 정렬 순서를 바꾸지 않는다. |
정렬 방법
원리 자체는 간단하다. 앞에서부터 해당 원소가 위치 할 곳을 탐색하고 해당 위치에 삽입하는 것이다.
삽입 정렬의 전체적인 과정은 이렇다. (오름차순을 기준으로 설명)
- 현재 타겟이 되는 숫자와 이전 위치에 있는 원소들을 비교한다. (첫 번째 타겟은 두 번째 원소부터 시작한다.)
- 타겟이 되는 숫자가 이전 위치에 있던 원소보다 작다면 위치를 서로 교환한다.
- 그 다음 타겟을 찾아 위와 같은 방법으로 반복한다.
즉, 그림으로 보면 다음과 같은 과정을 거친다.


첫 번째 원소는 타겟이 되어도 비교 할 원소가 없기 때문에 처음 원소부터 타겟이 될 필요가 없고 두 번째 원소부터 타겟이 되면 된다.
전체적인 흐름을 보면 다음과 같다.
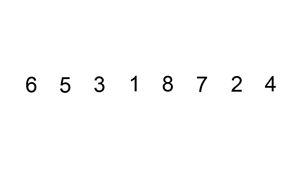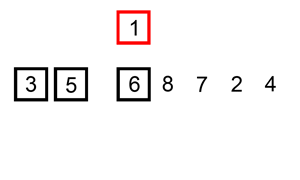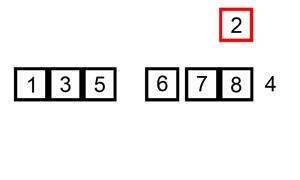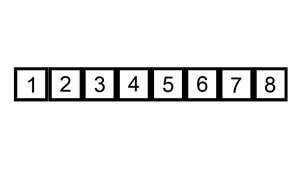

그 외에도 많은 참고 영상들이 있는데, 영상으로 보는 것이 더 쉬울 것 같아 같이 첨부하도록 하겠다.

Insertion Sort 구현하기
public class InsertionSort {
public static void sort(int[] arr) {
for (int i = 1; i < arr.length; i++) {
// 타겟 넘버
int target = arr[i];
int j = i - 1;
// 타겟이 이전 원소보다 크기 전 까지 반복
while(j >= 0 && target < arr[j]){
arr[j+1] = arr[j]; // 이전 원소를 한 칸씩 뒤로 미룬다
j--;
}
/*
* 위 반복문에서 탈출 하는 경우 앞의 원소가 타겟보다 작다는 의미이므로
* 타겟 원소는 j번째 원소 뒤에 와야한다.
* 그러므로 타겟은 j + 1 에 위치하게 된다.
*/
arr[j + 1] = target;
}
System.out.println(Arrays.toString(arr));
}
public static void main(String[] args) {
int[] arr = {3, 1, 4, 6, 8, 2};
sort(arr);
}
}결과적으로 타겟 이전 원소가 타겟 숫자보다 크기 직전까지 모든 수를 뒤로 한 칸씩 밀어내는 것이다.
장점 및 단점
[장점]
1. 추가적인 메모리 소비가 작다.
2. 거의 정렬 된 경우 매우 효율적이다. 즉, 최선의 경우 O(N)의 시간복잡도를 갖는다.
3. 안장정렬이 가능하다.
[단점]
1. 역순에 가까울 수록 매우 비효율적이다. 즉, 최악의 경우 O(N^2)의 시간 복잡도를 갖는다.
2. 데이터의 상태에 따라서 성능 편차가 매우 크다.
시간복잡도
타겟 숫자가 이전 숫자보다 크기 전까지 반복하기 때문에 이미 정렬이 되어있는 경우 항상 타겟숫자가 이전 숫자보다 크다. 즉, 값을 N번만 비교하기 때문에 최선의 경우 O(N)의 시간 복잡도를 갖게 되는 것이다.
반대로 최악의 경우는 타겟 숫자가 이전 숫자보다 항상 작기 때문에 결국 N 번째 숫자에 대하여 N-1 번을 비교해야 한다. 그렇기 때문에 최악의 경우는 O(N2)의 시간복잡도를 보인다.
그럼 평균 시간 복잡도는? 이라는 질문이라면 삽입 정렬의 평균 시간 복잡도 또한 O(N2)의 시간 복잡도를 갖는다.
공식을 유도해보자면 이렇다.
이미 최선의 경우는 O(N)인 것을 알았으니 최악의 경우를 보자.
N이 정렬해야하는 리스트의 자료 수, i가 타겟이 되는 인덱스라고 할 때 loop(반복문)을 생각해보자.
i=2 일 때, 데이터 비교 횟수는 2-1 = 1번
i=3 일 때, 데이터 비교 횟수는 3-1 = 2번
i=4 일 때, 데이터 비교 횟수는 4-1 = 3 번
⋮
i=N 일 때, 데이터 비교 횟수는 N-1 번
즉, 다음과 같이 공식화 할 수 있다.

그리고 N에 대하여 다음을 만족하기 때문에 시간복잡도 또한 도출 할 수 있다.

그럼 최악과 최선의 경우를 합쳐서 2로 나누면 평균이지 않을까? 결과적으로 시간복잡도는 상한선을 의미하기 때문에 아래와 같은 결과를 도출할 수 있다.

결과적으로 최상의 경우와 최악의 경우의 평균으로 보더라도 '상한선'이라는 개념에 의해 O(N2)이 정설로 보고 있다.
물론 다음에 다룰 Bubble Sort나 Selection Sort 와 이론상 같은 시간복잡도를 갖음에도 평균 비교 횟수에 대한 기대값이 상대적으로 적기 때문에 평균 시간복잡도가 O(N2) 인 정렬 알고리즘 중에서는 빠른편에 속하는 알고리즘이다.
| 알고리즘 | 시간복잡도(최상) | 시간복잡도(평균) | 시간복잡도(최악) | 공간복잡도 |
| 버블 정렬 | O(n) | O(n^2) | O(n^2) | O(1) |
정리
삽입 정렬의 경우 거의 정렬 된 배열에서 좋은 성능을 보이기 때문에 실제로 병합정렬과 삽입 정렬을 혼합한 Tim Sort(팀 정렬)이 있다. 또한 이 팀 정렬이 프로그래밍 언어에서도 자체 라이브러리로 정렬 알고리즘에 적용하고 있는 언어들이 있다.
그리고 삽입 정렬을 변형하여 만들어낸 정렬이 Shell Sort(셸 정렬)이다.
정렬 알고리즘들의 정렬 별 성능표는 아래와 같다..
테스트 한 결과로 Insertion sort는 2초대에 자리하고 있다. (컴퓨터의 환경 및 벤치마크 방식에 따라 달라질 수 있다)
또한 각 정렬 알고리즘 별 시간 복잡도와 평균 정렬 속도는 다음과 같다.

참고