스프링 데이터 JPA가 다음과 같은 기능들을 제공한다.
쿼리 메소드 기능 3가지
- 메소드 이름으로 쿼리 생성
- 메소드 이름으로 JPA NamedQuery 호출
- @Query 어노테이션을 사용해서 리파지토리 인터페이스에 쿼리 직접 정의
메소드 이름으로 쿼리 생성
- 스프링 데이터 JPA는 메소드 이름을 분석해서 JPQL을 생성하고 실행
이름과 나이를 기준으로 회원을 조회하려면?
순수 JPA 리포지토리
public List<Member> findByUsernameAndAgeGreaterThan(String username, int age) {
return em.createQuery("select m from Member m where m.username = :username and m.age > :age", Member.class)
.setParameter("username", username)
.setParameter("age", age)
.getResultList();
}스프링 데이터 JPA
List<Member> findByUsernameAndAgeGreaterThan(String username, int age);- 스프링 데이터 JPA는 메소드 이름을 분석해서 JPQL을 생성하고 실행
- 쿼리 메소드 필터 조건
스프링 데이터 JPA가 제공하는 쿼리 메소드 기능
- 조회: find…By ,read…By ,query…By get…By,
- https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#repositories.query-methods.query-creation
- 예:) findHelloBy 처럼 ...에 식별하기 위한 내용(설명)이 들어가도 된다.
- COUNT: count…By 반환타입 long
- EXISTS: exists…By 반환타입 boolean
- 삭제: delete…By, remove…By 반환타입 long
- DISTINCT: findDistinct, findMemberDistinctBy
- LIMIT: findFirst3, findFirst, findTop, findTop3
※ 참고
이 기능은 엔티티의 필드명이 변경되면 인터페이스에 정의한 메서드 이름도 꼭 함께 변경해야 한다. 그렇지 않으면 애플리케이션을 시작하는 시점에 오류가 발생한다.
이렇게 애플리케이션 로딩 시점에 오류를 인지할 수 있는 것이 스프링 데이터 JPA의 매우 큰 장점이다
메소드 이름으로 JPA NamedQuery 호출
JPA의 NamedQuery를 호출할 수 있음
Entity 에 @NamedQuery 어노테이션으로 Named 쿼리 정의
/* Entity Area */
@Entity
@NamedQuery(
name="Member.findByUsername",
query="select m from Member m where m.username = :username"
)
public class Member {
...
}순수 JPA를 이용한 NamedQuery 호출
public List<Member> findByUsername(String username) {
return em.createNamedQuery("Member.findByUsername", Member.class)
.setParameter("username", username)
.getResultList();
}스프링 데이터 JPA를 이용한 NamedQuery 사용
@Query(name = "Member.findByUsername")
List<Member> findByUsername(@Param("username") String username);
- @Query 를 생략하고 메서드 이름만으로 NamedQuery 호출이 가능하다.
우선 순위
- 스프링 데이터 JPA는 선언한 "도메인 클래스 + .(점) + 메서드 이름"으로 Named 쿼리를 찾아서 실행
- 만약 실행할 Named 쿼리가 없으면 메서드 이름으로 쿼리 생성 전략을 사용한다.
- 필요하면 전략을 변경할 수 있지만 권장하지 않는다.
※ 참고
스프링 데이터 JPA를 사용하면 실무에서 Named Query를 직접 등록해서 사용하는 일은 드물다.
대신 @Query 를 사용해서 레파지토리 메소드에 쿼리를 직접 정의한다.
NamedQuery의 장점
- @NamedQuery에 정의한 쿼리의 경우 정적 쿼리이기 때문에 애플리케이션 로딩 시점에 JPQL을 SQL로 미리 파싱하여 해준다.
- 이때 문법 오류가 발견되면 애플리케이션이 실행안되고 오류를 내뱁는다.
@Query, 리포지토리 메소드에 쿼리 정의하기
메서드에 JPQL 쿼리 작성
@Query("select m from Member m where m.username = :username and m.age = :age")
List<Member> findUser(@Param("username") String username, @Param("age") int age);- @Query 어노테이션을 사용
- 실행할 메서드에 정적 쿼리를 직접 작성하기에 익명 NamedQuery라 할 수 있다.
- JPA Named 쿼리처럼 애플리케이션 실행 시점에 문법 오류를 발견할 수 있다.(매우 큰 장점!)
※ 참고
실무에서는 메소드 이름으로 쿼리 생성 기능은 파라미터가 증가하면 메서드 이름이 매우 지저분해진다.
따라서 정적 쿼리의 경우 @Query 기능을 자주 사용하게 된다.
@Query, 값, DTO조회하기
단순히 값 하나 조회
@Query("select m.username from Member m")
List<String> findUsernameList();- JPA 값 타입( @Embedded )도 이 방식으로 조회할 수 있다.
DTO로 직접 조회
@Query("select new study.datajpa.dto.MemberDto(m.id, m.username, t.name) from Member m join m.team t")
List<MemberDto> findMemberDto();- DTO에 직접 매핑 해주려면 new 명령어를 사용해야 하고, 패키지경로를 모두 작성해줘야 한다.
- DTO에 생성자 형식, 순서에 맞게 작성이 되어야 한다.
파라미터 바인딩
파라미터 바인딩은 위치기반 바인딩 과 이름 기반 바인딩 두가지가 있다.
select m from Member m where m.username = ?0 //위치 기반
select m from Member m where m.username = :name //이름 기반
이름기반 바인딩을 사용하자
- 위치 기반 파라미터 바인딩은 해당 위치에 어떤 파라미터가 매핑되는지 가독성이 떨어지고, 추후 기능변경으로 인해 중간에 다른 파라미터가 추가될 경우 에러가 날 확률이 높다.
- 코드 가독성과 유지보수를 위해서 이름 기반 파라미터 바인딩을 사용하도록 하자.
컬렉션 파라미터 바인딩
Collection 타입으로 in절 지원
@Query("select m from Member m where m.username in :names")
List<Member> findByNames(@Param("names") List<String> names);
반환 타입
스프링 데이터 JPA는 유연한 반환 타입 지원
List<Member> findListByUsername(String username); // 컬렉션
Member findMemberByUsername(String username); // 단건
Optional<Member> findOptionalByUsername(String username); // 단건 Optional스프링 데이터 JPA 공식 문서: https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#repository-query-return-types
조회 결과가 많거나 없으면?
- 컬렉션
- 결과 없음: 빈 컬렉션 반환
- 단건 조회
- 결과 없음: null 반환
- 결과가 2건 이상: javax.persistence.NonUniqueResultException 예외 발생
※ 참고
단건으로 지정한 메서드를 호출하면 스프링 데이터 JPA는 내부에서 JPQL의 Query.getSingleResult() 메서드를 호출한다. 이 메서드를 호출했을 때 조회 결과가 없으면 javax.persistence.NoResultException 예외가 발생하는데 개발자 입장에서 다루기가 상당히 불편하다.
그래서 스프링 데이터 JPA는 단건을 조회할 때 이 예외가 발생하면 예외를 무시하고 대신에 null 을 반환한다.
순수 JPA 페이징과 정렬
JPA에서 페이징을 어떻게 할까?
다음 조건으로 페이징과 정렬을 사용하는 예제 코드를 만들어보자.
- 검색 조건: 나이가 10살
- 정렬 조건: 이름으로 내림차순
- 페이징 조건: 첫 번째 페이지, 페이지당 보여줄 데이터는 3건
JPA 페이징 리포지토리
public List<Member> findByPage(int age, int offset, int limit) {
return em.createQuery("select m from Member m where m.age = :age order by m.username desc", Member.class)
.setParameter("age", age)
.setFirstResult(offset)
.setMaxResults(limit)
.getResultList();
}
public long totalCount(int age) {
return em.createQuery("select count(m) from Member m where m.age = :age", Long.class)
.setParameter("age", age)
.getSingleResult();
}- 단점 : Page 계산 공식을 직접 계산해서 사용해야함.
Test 코드
@Test
public void pagin() {
//given
memberJpaRepository.save(new Member("member1", 10));
memberJpaRepository.save(new Member("member2", 10));
memberJpaRepository.save(new Member("member3", 10));
memberJpaRepository.save(new Member("member4", 10));
memberJpaRepository.save(new Member("member5", 10));
int age = 10;
int offset = 0;
int limit = 3;
//when
List<Member> members = memberJpaRepository.findByPage(age, offset, limit);
long totalCount = memberJpaRepository.totalCount(age);
//페이지 계산 공식 적용...
// totalPage = totalCount / size ...
// 마지막 페이지 ...
// 최초 페이지 ..
//then
assertThat(members.size()).isEqualTo(3);
assertThat(totalCount).isEqualTo(5);
}
스프링 데이터 JPA 페이징과 정렬
스프링 데이터 JPA에서는 페이징과 정렬을 공통화시켜놨다.
아래 패키지를 살펴보면 Jpa가 아닌 org.springframework.data.domain 인 것을 확인할 수 있다. 즉, DB 종류에 상관없이 페이징과 정렬 기능을 규격화해놓은 것이다.
- org.springframework.data.domain.Sort :정렬기능
- org.springframework.data.domain.Pageable : 페이징 기능(내부에 Sort 포함)
특별한 반환 타입
- org.springframework.data.domain.Page : 추가 count쿼리 결과를 포함하는 페이징
- org.springframework.data.domain.Slice : 추가 count 쿼리 없이 다음 페이지만 확인 가능( 내부적으로 limit + 1 조회)
- 일반적으로 모바일 환경에서 스크롤 아래 "더보기" 와 같은 기능을 구현할 때 눈속임으로 limit + 1 조회하고 사용자에게는 limit 개수 까지만 보여주는 것이다.
- 그러고 "더보기" 를 클릭하면 limit + 1 부터 추가적으로 데이터를 가져온다.
- List(자바 컬렉션): 추가 count쿼리 없이 결과만 반환
페이징과 정렬 사용 예제
Page<Member> findByUsername(String name, Pageable pageable); //count 쿼리 사용
Slice<Member> findByUsername(String name, Pageable pageable); //count 쿼리 사용 안함
List<Member> findByUsername(String name, Pageable pageable); //count 쿼리 사용 안함
List<Member> findByUsername(String name, Sort sort);
이전에 작성했던 예제 코드에 스프링 데이터 JPA 페이징과 정렬을 적용해보자.
- 검색 조건: 나이가 10살
- 정렬 조건: 이름으로 내림차순
- 페이징 조건: 첫 번째 페이지, 페이지당 보여줄 데이터는 3건
Page 인터페이스
Page 사용 예제 정의 코드
public interface MemberRepository extends Repository<Member, Long> {
Page<Member> findByAge(int age, Pageable pageable);
}Page 사용 테스트 코드
@Test
public void pagin() {
//given
memberRepository.save(new Member("member1", 10));
memberRepository.save(new Member("member2", 10));
memberRepository.save(new Member("member3", 10));
memberRepository.save(new Member("member4", 10));
memberRepository.save(new Member("member5", 10));
int age = 10;
// 스프링 데이터 JPA 의 페이지 인덱스는 0부터 시작
PageRequest pageRequest = PageRequest.of(0, 3, Sort.by(Direction.DESC, "username"));
//when
Page<Member> page = memberRepository.findByAge(age, pageRequest);
//then
List<Member> content = page.getContent(); //조회된 데이터
assertThat(content.size()).isEqualTo(3); //조회된 데이터 수
assertThat(page.getTotalElements()).isEqualTo(5); //전체 데이터 수
assertThat(page.getNumber()).isEqualTo(0); //페이지 번호
assertThat(page.getTotalPages()).isEqualTo(2); //전체 페이지 번호
assertThat(page.isFirst()).isTrue(); //첫번째 항목인가?
assertThat(page.hasNext()).isTrue(); //다음 페이지가 있는가?
}- 두 번째 파라미터로 받은 Pageable 은 인터페이스다.
따라서 실제 사용할 때는 해당 인터페이스를 구현한 org.springframework.data.domain.PageRequest 객체를 사용한다. - PageRequest 생성자의 첫 번째 파라미터에는 현재 페이지를, 두 번째 파라미터에는 조회할 데이터 수를 입력한다. 여기에 추가로 정렬 정보도 파라미터로 사용할 수 있다.
참고로 페이지는 0부터 시작한다.
※ 주의
Page는 1부터 시작이 아니라 0부터 시작이다.
실행되는 쿼리
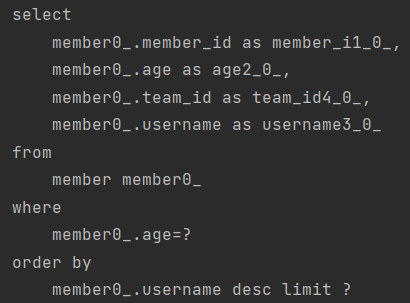
위 테스트 코드에선 따로 totalCount를 계산하는 쿼리를 실행해준 적이 없지만 스프링 데이터 JPA 가 알아서 count 쿼리는 날려 결과를 얻어오는 것을 확인할 수 있다.
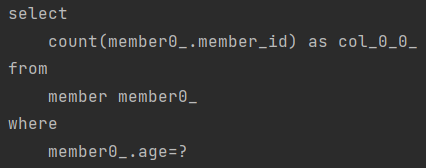
Page 인터페이스
public interface Page<T> extends Slice<T> {
int getTotalPages(); //전체 페이지 수
long getTotalElements(); //전체 데이터 수
<U> Page<U> map(Function<? super T, ? extends U> converter); //변환기
}Slice 인터페이스
Slice 사용 예제 정의 코드
public interface MemberRepository extends JpaRepository<Member, Long> {
Slice<Member> findByAge(int age, Pageable pageable);
}Slice 사용 테스트 코드
@Test
public void paging_slice() {
//given
memberRepository.save(new Member("member1", 10));
memberRepository.save(new Member("member2", 10));
memberRepository.save(new Member("member3", 10));
memberRepository.save(new Member("member4", 10));
memberRepository.save(new Member("member5", 10));
int age = 10;
// 스프링 데이터 JPA 의 페이지 인덱스는 0부터 시작
PageRequest pageRequest = PageRequest.of(0, 3, Sort.by(Direction.DESC, "username"));
//when
Slice<Member> page = memberRepository.findByAge(age, pageRequest);
//then
List<Member> content = page.getContent(); //조회된 데이터
assertThat(content.size()).isEqualTo(3); //조회된 데이터 수
// assertThat(page.getTotalElements()).isEqualTo(5); //전체 데이터 수
assertThat(page.getNumber()).isEqualTo(0); //페이지 번호
// assertThat(page.getTotalPages()).isEqualTo(2); //전체 페이지 번호
assertThat(page.isFirst()).isTrue(); //첫번째 항목인가?
assertThat(page.hasNext()).isTrue(); //다음 페이지가 있는가?
}앞서 Slice는 추가 count 쿼리 없이 다음 페이지만 확인 가능이고 내부적으로 limit + 1 조회를 한다고 했다.
위 테스트 코드에서의 분명 size를 3으로 줬는데 실행되는 쿼리는 어떻게 될까?
우선 count 관련 쿼리는 실행되지 않는다.
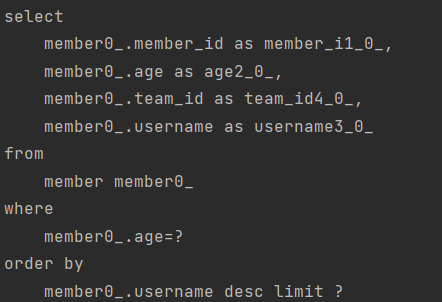
그리고 limit 부분의 실제 값을 보면 limit + 1 인 4로 할당되는 것을 확인할 수 있다.

실무 : count 쿼리를 다음과 같이 분리할 수 있다.
위에서 배운 페이징의 경우 content를 가져오는 것은 그렇게 큰 문제가 되지 않는다(어차피 limit 개수 만큼 짤라서 가져오므로).
하지만 전체 content의 개수를 가져올 수 밖에 없는 즉, 성능과 직접적으로 연관된 쿼리는 total count를 구하는 쿼리이다.
그래서 만약 (left, right) join이 복잡하게 걸린 쿼리에서 count 쿼리도 동일한 쿼리를 사용한다면 join하는 시간에 종속적일 수 밖에 없다.
아래 간단한 예시를 살펴보자.
만약 아래와 같이 left join 이 걸린 쿼리를 페이징한다면 쿼리는 어떻게 생성될까?
@Query(value = "select m from Member m left join m.team")
Page<Member> findByAge(int age, Pageable pageable);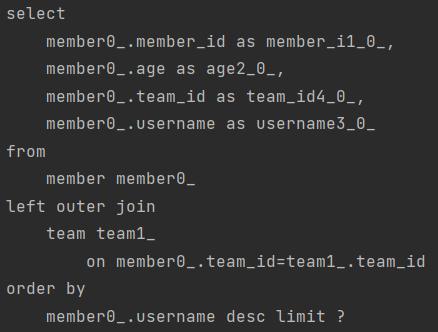
우선 jeft join 이기 때문에 결국 content 의 개수는 left 쪽과 동일할 것이다. 그런데 count 쿼리를 보면 count 쿼리에서 join이 걸리면서 의미 없는 낭비가 발생하고 있다.
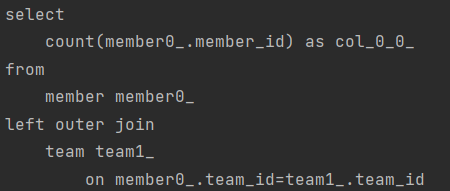
결국 left, right join 시 total count는 기준 테이블의 content 개수와 동일할 수 밖에 없으므로 이때는 count 쿼리를 분리하는 것이 성능상 이점일 것이다.
count 쿼리 분리
- 카운트 쿼리 분리(이건 복잡한 sql에서 사용, 데이터는 left join, 카운트는 left join 안해도 됨)
- 실무에서 매우 중요!!!
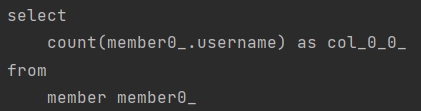
@Query(value = "select m from Member m left join m.team",
countQuery = "select count(m.username) from Member m")
Page<Member> findByAge(int age, Pageable pageable);결과를 확인해보면 확실히 쿼리가 짧아진 것을 확인할 수 있다.
※ 참고
결국 스프링 데이터 JPA에서 페이징은 Pageable 파라미터와 반환 타입(Page, Slice, List) 가 대신 처리를 해주는 것이다. 그래서 개발자는 핵심 비지니스 쿼리에만 집중할 수 있다.
추가적으로 Sort 조건이 복잡해지면 이때는 직접 쿼리를 작성하는 방법이 있다.
실무 : 페이지를 유지하며 엔티티를 DTO로 변환할 수 있다.
실무에서 엔티티를 그대로 반환하는 것은 위험하다. 그렇기 때문에 엔티티를 DTO로 변환하여 반환해야 한다.
Page<Member> page = memberRepository.findByAge(10, pageRequest);
Page<MemberDto> dtoPage = page.map(m -> new MemberDto(...m.getName()));※ 추가
Page 의 경우 직접적으로 api로 반환해도 된다. 이때 json에는 위에서 살펴본 Page 인터페이스가 제공하는 모든 값들이 포함되어 있다.
스프링 부트 3 - 하이버네이트 6 left join 최적화 설명 추가
스프링 부트 3 이상을 사용하면 하이버네이트 6이 적용된다.
이 경우 하이버네이트 6에서 의미없는 left join을 최적화 해버린다. 따라서 다음을 실행하면 SQL이 LEFT JOIN을 하지 않는 것으로 보인다
@Query(value = "select m from Member m left join m.team t")
Page<Member> findByAge(int age, Pageable pageable);select
m1_0.member_id,
m1_0.age,
m1_0.team_id,
m1_0.username
from
member m1_0하이버네이트 6은 이런 경우 왜 left join을 제거하는 최적화를 할까?
실행한 JPQL을 보면 left join을 사용하고 있다.
select m from Member m left join m.team tMember 와 Team 을 조인을 하지만 사실 이 쿼리를 Team 을 전혀 사용하지 않는다. select 절이나, where 절에서 사용하지 않는 다는 뜻이다. 그렇다면 이 JPQL은 사실상 다음과 같다.
select m from Member m이는 즉, left join 이기 때문에 왼쪽에 있는 member 자체를 다 조회한다는 뜻이 된다.
그래서 JPA는 이 경우 최적화를 해서 join 없이 해당 내용만으로 SQL을 만든다.
만약 select 나, where 에 team 의 조건이 들어간다면 정상적인 join 문이 보일 것이다.
여기서 만약 Member 와 Team 을 하나의 SQL로 한번에 조회하고 싶다면 JPA가 제공하는 fetch join 을 사용해야 한다.
select m from Member m left join fetch m.team t
이 경우에도 SQL에서 join문은 정상 수행된다
벌크성 수정 쿼리
JPA를 사용한 벌크성 수정 쿼리
public int bulkAgePlus(int age) {
return em.createQuery(
"update Member m set m.age = m.age + 1"
+ " where m.age >= :age")
.setParameter("age", age)
.executeUpdate();
}
스프링 데이터 JPA를 사용한 벌크성 수정 쿼리
@Modifying
@Query("update Member m set m.age = m.age + 1 where m.age >= :age")
int bulkAgePlus(@Param("age") int age);스프링 데이터 JPA를 사용한 벌크성 수정 쿼리 테스트
@Test
public void bulkUpdate () {
//given
memberRepository.save(new Member("member1", 10));
memberRepository.save(new Member("member2", 19));
memberRepository.save(new Member("member3", 20));
memberRepository.save(new Member("member4", 21));
memberRepository.save(new Member("member5", 40));
//when
int resultCount = memberRepository.bulkAgePlus(20);
//then
assertThat(resultCount).isEqualTo(3);
}
- 벌크성 수정, 삭제 쿼리는 @Modifying 어노테이션을 사용
- 사용하지 않으면 org.hibernate.hql.internal.QueryExecutionRequestException: Not supported for DML operations 예외 발생
- 벌크성 쿼리를 실행하고 나서 영속성 컨텍스트 초기화: @Modifying(clearAutomatically = true)
(이 옵션의 기본값은 false )- 순수 JPA에서는 em.flush(), em.clear() 실행
- 이 옵션 없이 회원을 findById 로 다시 조회하면 영속성 컨텍스트에 과거 값이 남아서 문제가 될 수 있다. 만약 다시 조회해야 하면 꼭 영속성 컨텍스트를 초기화 하자.
- 비즈니스 로직에서 벌크성 수정 쿼리만 동작하고 트랜잭션 종료하는게 사실 제일 깔끔하다.
※ 참고
벌크 연산은 영속성 컨텍스트를 무시하고 실행하기 때문에, 영속성 컨텍스트에 있는 엔티티의 상태와 DB에 엔티티 상태가 달라질 수 있다.
권장하는 방안
1. 영속성 컨텍스트에 엔티티가 없는 상태에서 벌크 연산을 먼저 실행한다.
2. 부득이하게 영속성 컨텍스트에 엔티티가 있으면 벌크 연산 직후 영속성 컨텍스트를 초기화 한다.
@EntityGraph
연관된 엔티티들을 SQL 한번에 조회하는 방법
Member를 조회하면서 Team 도 같이 조회해 보자.
- 현재 member → team 은 지연로딩 관계이다.
- 따라서 다음과 같이 team의 데이터를 조회할 때 마다 쿼리가 실행된다. (N+1 문제 발생)
@Test
public void findMemberLazy() throws Exception {
//given
//member1 -> teamA
//member2 -> teamB
Team teamA = new Team("teamA");
Team teamB = new Team("teamB");
teamRepository.save(teamA);
teamRepository.save(teamB);
memberRepository.save(new Member("member1", 10, teamA));
memberRepository.save(new Member("member2", 20, teamB));
em.flush();
em.clear();
//when
List<Member> members = memberRepository.findAll();
//then
for (Member member : members) {
member.getTeam().getName();
}
}- 위 코드를 실행하면 지연로딩인 관계로 memberRepository.findAll() 으로 members를 가져왔을 당시에 team 필드는 Proxy객체로 내용은 비어있다.
- 그렇기 때문에 반복문이 돌며 member.getTeam().getName() 메서드가 수행 될 때마다 DB에서 team 정보를 가져온다. (N + 1 문제)
- 그렇다고, 로딩전략(fetch)을 즉시로딩으로 하면 최적화 및 성능부분에서 좋지 않다.
JPQL 페치 조인
- 그래서 순수 JPA에서는 fetch 를 이용해 join fetch를 해서 한 번에 연관 엔티티도 가져왔듯이 스프링 데이터 JPA에서도 페치 조인을 통해 한번에 연관엔티티를 조회한다.
@Query("select m from Member m left join fetch m.team")
List<Member> findMemberFetchJoin();
EntityGraph
스프링 데이터 JPA는 JPA가 제공하는 엔티티 그래프 기능을 편리하게 사용하게 도와준다. 이 기능을 사용 하면 JPQL 없이 페치 조인을 사용할 수 있다. (JPQL + 엔티티 그래프도 가능)
//공통 메서드 오버라이드
@Override
@EntityGraph(attributePaths = {"team"})
List<Member> findAll();
//JPQL + 엔티티 그래프
@EntityGraph(attributePaths = {"team"})
@Query("select m from Member m")
List<Member> findMemberEntityGraph();
//메서드 이름으로 쿼리에서 특히 편리하다.
@EntityGraph(attributePaths = {"team"})
List<Member> findByUsername(String username)- LEFT OUTER JOIN 이 사용되어 결과를 받아온다.
참고: JPA 표준 스팩인 NamedEntityGraph로도 EntityGraph를 사용할 수 있다
/* Entity */
@NamedEntityGraph(name = "Member.all", attributeNodes = @NamedAttributeNode("team"))
@Entity
public class Member {}
...
/* Repository */
@EntityGraph("Member.all")
@Query("select m from Member m")
List<Member> findMemberEntityGraph();
JPA Hint& Lock
JPA Hint
- JPA 쿼리 힌트(SQL 힌트가 아니라 JPA 구현체에게 제공하는 힌트)
쿼리 힌트 사용
@QueryHints(value = @QueryHint(name = "org.hibernate.readOnly", value ="true"))
Member findReadOnlyByUsername(String username);- 쿼리를 읽기전용으로 조회한다고 힌트를 주고 있다.
테스트 코드
@Test
public void queryHint() throws Exception {
//given
memberRepository.save(new Member("member1", 10));
em.flush();
em.clear();
//when
Member member = memberRepository.findReadOnlyByUsername("member1");
member.setUsername("member2");
em.flush(); //Update Query 실행X
}- 실행해보면 변경감지가 안되는 것을 확인할 수 있다.
쿼리 힌트 Page 추가 예제
@QueryHints(value = {@QueryHint(name = "org.hibernate.readOnly", value = "true")},
forCounting = true)
Page<Member> findByUsername(String name, Pageable pageable);- org.springframework.data.jpa.repository.QueryHints 어노테이션을 사용
- forCounting : 반환 타입으로 Page 인터페이스를 적용하면 추가로 호출하는 페이징을 위한 count 쿼리도 쿼리 힌트 적용(기본값 true )
정리
굳이 QueryHint까지 써야할 정도의 코드 최적화와 성능튜닝이 요구되는 경우는 거의 없다.
성능이 극한으로 요구된다해도 복잡한 쿼리 자체의 문제로 느려지는 경우가 대다수이기 때문에 QueryHint를 하나하나 적어주기보다는 조회 쿼리를 수정하는 것이 맞다.
그리고, QueryHint는 운영을 하면서 조금씩 여유가 될 때 정 필요하면 넣어주는 정도로도 충분하다.
Lock
org.springframework.data.jpa.repository.Lock 어노테이션을 사용한다.
@Lock(LockModeType.PESSIMISTIC_WRITE)
List<Member> findByUsername(String name);JPA가 제공하는 락은 JPA 책 16.1 트랜잭션과 락 절을 참고
참고 : Lock종류
1. 낙관적 잠금(Optimisstic Lock)
- => 낙관적 잠금은 실무에서 실질적으로 데이터 갱신 시 경합이 발생하지 않을 것이라고 낙관적으로 판단하여 잠금을 거는 기법이다.
- 예를들어, 회원정보의 변경 요청은 보통 회원 당사자에 의해 요청이 발생하기에 동시접근이 발생 할 확률이 낮다.
- 따라서 동시 수정이 이뤄지는 경우를 감지해서 예외를 발생해도 발생 가능성이 낮다고 보는 것으로 잠금(Lock)보다는 충돌감지(Conflict detection)에 가깝다.
2. 비관적 잠금(Perssimistic Lock)
- => 동일한 데이터를 동시에 수정 할 가능성이 높다는 비관적인 전제로 잠금을 거는 방식이다.
- 예를들어, 상품의 재고의 경우 여러명이 같은 상품을 동시에 주문할 수 있기 때문에 데이터 수정에 의한 경합이 발생할 확률이 높다고 비관적으로 보는 것이다. 이럴 경우 비관적 잠금(Perssimistic Lock)을 통해 예외를 발생시키지 않고 정합성을 보장하는 것이 가능하다.
- 다만, 성능적인 측면에서 손실을 감수해야 한다.
- 데이터베이스에서 제공하는 베타잠금(Exclusive Lock)을 사용한다.
3. 암시적 잠금(Implicit Lock)
- ⇒ 프로그램 코드상에 명시적으로 지정하지 않아도 잠금이 발생하는 것을 의미한다.
- JPA에서는 엔티티에 @Version이 붙은 필드가 존재하거나 @OptimisticLocking 어노테이션이 설정되어 있을 경우 자동적으로 충돌감지를 위한 잠금이 실행된다. 그리고 데이터베이스의 경우에는 일반적으로 사용하는 대부분의 데이터베이스가 업데이트, 삭제 쿼리 발생시 암시적으로 해당 로우에 대한 행 배타잠금(Row Exclusive Lock)이 실행된다. JPA의 충돌감지가 역할을 할 수 있는 것도 데이터베이스의 암시적 잠금이 있기 때문이다.
4. 명시적 잠금(Explicit Lock)
- ⇒ 프로그램을 통해 의도적으로 잠금을 실행하는 것이 명시적 잠금이다.
- JPA에서 엔티티를 조회할 때 LockMode를 지정하거나 select for update 쿼리를 통해 직접 잠금을 지정할 수 있다.