스레드의 개념과 상태 변환
[OS] 프로세스 개념과 상태 변화 및 관리
프로세스(Process)란? 초기에 사용하던 컴퓨터는 프로그램을 한 번에 하나씩 실행했고, 실행 중인 프로그램이 컴퓨터 자원을 독점했다. 반면에 다중 프로그래밍 환경에서는 여러 프로그램을 메모
s-y-130.tistory.com
스레드의 개념
이전 포스팅에서 살펴본 프로세스는 두 가지 특성인 자원과 제어로 구분할 수 있다. 이 중 제어만 분리한 실행 단위를 스레드(thread)라고 하는데, 프로세스 하나는 스레드 한 개 이상으로 나눌 수 있다.
스레드들은 프로세스의 직접 실행 정보를 제외한 나머지 프로세스 관리 정보를 공유한다.

위 그림과 같이 프로그램 카운터(PC)와 스택 포인터(SP)등을 비롯한 스레드 '실행 환경 정보(문맥 정보), 지역 데이터, 스택'을 독립적으로 가지면서 '코드, 전역 데이터, 힙'을 다른 스레드와 공유한다.
- SP(Stack Pointer) : 스택 포인터
- SR(Sequence Register) : 순서열 레지스터
- PC(Program Counter) : 프로그램 카운터
스레드는 보통 다른 프로시저를 호출하고 다른 실행을 기록한다. 그러므로 별도의 스택이 필요하고, 프로그램 카운터가 독립적이라서 같은 프로세스의 스레드들이 동시에 코드의 동일한 부분이나 다른 부분을 실행할 수 있다.
스레드는 관련 자원과 함께 메모리를 공유할 수 있는데, 이 때문에 손상된 데이터나 스레드의 이상 동작을 고려해야 한다.
※ 참고
프로시저란?
한 프로그램은 여러개의 작은 프로그램으로 분할될 수 있는데 이떄 분할된 작은 프로그램을 의미하며, 부 프로그램이라고도 한다.
스레드 중에서 프로세스의 속성 중 일부가 들어있는 것을 경량 프로세스(LWP, Light Weight Process)라고 하며, 반대로 스레드 하나에 프로세스 하나인 전통적인 경우를 중량 프로세스(HWP, Heavy Weight Process)라고 한다.
응용 프로그램에는 적어도 프로세스가 하나 있고, 프로세스에는 스레드 한 개 이상 있다.

그리고 같은 프로세스의 스레드들은 그림과 같이 동일한 주소 공간을 공유한다.
프로세스 하나에 포함된 스레드들은 공동의 목적을 달성하려고 병렬로 수행한다. 즉, 프로세스가 하나인 서로 다른 프로세서에서 프로그램의 다른 부분을 동시에 실행할 수 있는데, 스레드를 이용하면 다음 이점이 있다.
- 사용자 응답성 증가
- 응용 프로그램의 일부분을 봉쇄하거나 긴 작업을 수행하더라도 병렬 프로그래밍으로 프로그램을 계속 실행할 수 있어 사용자 응답성이 증가한다.
- 예를 들어, 다중 스레드를 적용한 웹 브라우저는 스레드 한 개가 파일을 로딩하는 동안 다른 스레드는 사용자와 상호작용을 할 수 있다.
- 프로세스의 자원과 메모리 공유 가능
- 스레드들이 프로세스 자원 하나와 메모리를 공유하므로 응용 프로그램 하나가 동일한 주소 공간에서 스레드를 여러 개 실행하여 시스템 성능을 향상시킬 수 있다.
- 경제성이 좋음
- 프로세스를 생성하는 것보다 스레드를 생성하여 문맥 교환하면 오버헤드가 줄어든다.
- 다중 처리(멀티 프로세싱)로 성능과 효율 향상
- 각 스레드를 여러 프로세서에서 병렬로 실행하여 성능과 효율성을 높일 수 있다.
단일 스레드와 다중(멀티) 스레드
OS는 단일 프로세스에서 단일 스레드 실행이나 다중 스레드 실행을 지원한다.
스레드와 프로세스의 관계를 아래 그림과 같다. 왼쪽은 스레드가 하나인 단일 스레드 프로세스이고, 오른쪽은 스레드가 3개인 다중 스레드 프로세스이다.

※ 참고
여기서 단일 스레드를 지원하는 OS는 프로세스 하나에 스레드 한개를 실행하는 전통적인 방법으로 아직 스레드 용어가 탄생하기 전이라 개념이 불확실하다. 도스가 대표적인 예이다.
현대 운영체제는 대부분 다중 스레드이다. 다중 스레드는 프로그램 하나를 여러 실행 단위로 쪼개어 실행한다는 측면에서 다충 처리(멀티 프로세싱)와 의미가 비슷하다. 하지만 동일 프로세스의 스레드는 자원을 공유하므로 자원 생성과 관리의 중복성을 최소화하여 실행 능력을 향상시킬 수 있다. 그리고 각 스레드는 커널이 개입하지 않고도 독립적으로 실행할 수 있어 서버에서 많은 요청을 효과적으로 처리할 수 있다.
단일 스레드와 다중 스레드를 프로세스 관리 측면에서 살펴보면 아래와 같다.
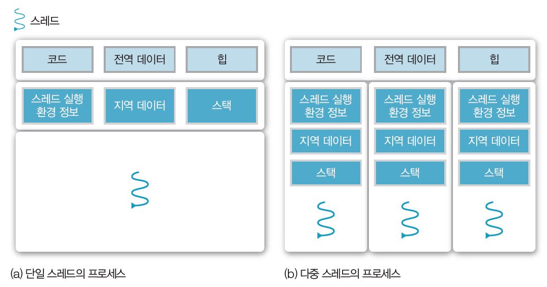
모든 스레드가 해당 프로세스의 자원을 공유하고, 같은 주소 공간에 있고, 동일한 데이터에 접근한다. 그러므로 스레드 한 개가 전역 데이터를 변경하면 다른 스레드도 이 데이터에 접근하여 변경 결과를 확인할 수 있다. 또 스레드 한 개가 읽기 권한으로 힙에 있는 파일을 열면 동일한 프로세스의 다른 스레드도 이 파일 읽을 수 있다. 이런 스레드의 특성은 프로세스의 생성과 종료 과정에 매우 유용하다.
이런 스레드의 특성 때문에 프로세스보다 스레드를 생성하는 것이 더 빠르고, 동일한 프로세스에 있는 스레드 간의 교환이나 스레드 종료도 훨씬 빠르다. 따라서 프로그램을 변경하지 않고 스레드를 병렬로 처리하여 효율을 극대화 할 수 있다.
물론 스레드별로 실행 환경 정보가 따로 있지만 서로 많이 공유하므로, 프로세스가 동일한 프로세스의 스레드에 프로세서를 할당하거나 스레드 간의 문맥 교환이 훨씬 경제적이다.
스레드의 사용 예시
현대 OS에서 수행하는 많은 프로그램은 다중 스레드를 지원하여 스레드의 개념을 사용자 수준에서 사용할 수 있다. 그리고 프로그램의 비동기적 요소를 구현하는데 사용할 수도 있다. 특히 스레드를 사용자 수준에서 적용하면 OS와 무관하므로 속도가 매우 빠르다.
예를 들어, 단일 사용자 다중 처리 시스템에서는 스레드 한 개로 사용자의 데이터를 읽어 들여 메뉴를 표시하고, 다른 스레드로는 사용자 명령을 실행하도록 하여 이전 명령이 완료되기 전에 다음 명령을 신속하게 준비해서 속도를 향상시킬 수 있다.
스레드를 이용하여 프로그램의 비동기적 요소를 구현한 예로는 워드 편집기를 예로 들 수 있다.
아래 그림과 같이 메모리의 내용을 지정한 시간에 디스크에 백업하도록 정기적인 백업 스레드를 생성하는 경우가 이에 해당한다.

또 현재 실행 중인 스레드를 대기 상태로 바꾸고 제어를 다른 스레드로 옮기는 상태 변화를 이용하여 많은 요청을 효과적으로 처리할 수 있다.
하지만 스레드에도 단점은 있다.
사용자 수준 스레드는 커널 자체가 스레드 한개로 구성되어 스레드에서 시스템 콜을 실행하면 전체 작업이 이 시스템의 호출 결과를 바을 때까지 기다려야 한다.
스레드의 상태 변화
스레드와 프로세스는 공통점이 상당히 많다. 프로세스처럼 준비, 실행, 대기(보류), 종료 상태가 있다. 스레드는 프로세서를 함께 사용하고 항상 하나만 실행한다. 또 한 프로세스에 있는 스레드는 순차적으로 실행하고, 해당 스레드의 정보를 저장하는 레지스터와 스택이 있다.

보통 프로세스를 생성하면 해당 프로세스의 스레드도 함께 생성된다. 단, 스레드 생성에서는 OS가 부모 프로세스와 공유할 자원을 초기화할 필요가 없다. 해당 프로세스가 스택과 레지스터를 제공하기 때문이다. 그러므로 프로세스의 생성과 종료보다는 오버레드가 훨씬 적다.
여기서 스레드의 장점 하나는 스레드 한 개가 대기 상태로 변할 때 전체 프로세스를 대기 상태로 바꾸지 않는다는 것이다. 실행 상태의 스레드가 대기 상태가 되면 다른 스레드를 실행할 수 있다. 그러나 프로세스와 달리 서로 독립적이지는 않다. 프로세스 하나에 잇는 전체 스레드는 프로세스의 모든 주소에 접근할 수 있으므로 스레드 한 개가 다른 스레드의 스택을 읽거나 덮어쓸 수 있다.
따라서 보호 문제가 발생할 수 잇지만 크게 염려하지 않아도 된다. 프로세서는 여러 사용자가 생성하여 서로 경쟁적으로 자원을 요구하고 서로 다른 관계를 유지해야 하지만, 스레드는 사용자 한 명이 여러 스레드로 개인 프로세스 하나를 소유하기 때문이다.
스레드의 제어 블록
프로세스가 프로세스 제어 블록(PCB)에 정보를 저장하듯이 스레드도 스레드 제어 블록(TCB, Thread Control Block)에 정보를 저장한다. 그런데 프로세스는 스레드를 한 개 이상 가질 수 있으므로, 결국 프로세스 제어 블록은 스레드 제어 블록의 리스트를 가리킨다.

스레드 제어 블록은 프로세스 제어 블록과 같은 레지스터 값, 프로그램 카운터, 스택 포인터, 스케줄링 상태 외에도 스레드 ID와 해당 스레드를 포함하는 프로세스 포인터 같은 특정 값도 저장한다.

- 실행 상태 : 프로세서 레지스터, 프로그램 카운터, 스택 포인터
- 스케줄링 정보 : 상태(실행, 준비, 대기), 우선순위, 프로세서 시간
- 계정 정보
- 스케줄링 큐용 다양한 포인터
- 프로세스 제어 블록(PCB)을 포함하는 포인터
스레드의 구현
스레드는 OS에 따라 다양하게 구현할 수 있는데, 대부분 다음 세 가지 형태로 구현한다. 사용자 수준 스레드는 스레드 라이브러리를 이용하여 작동하는 행태이고, 커널 수준 스레드는 커널(OS)에서 지원하는 형태이다. 그리고 이 둘을 혼합한 형태가 혼합형 스레드이다.
- 사용자 수준 스레드(user-level thread) : 다대일(n:1) 매핑
- 커널 수준 스레드(kernel-level thread) : 일대일(1:1) 매핑
- 혼합형 스레드(multiplexed thread) : 다대다(n:m) 매핑
사용자 수준 스레드(user-level thread)
스레드 라이브러리(Pthread, Win32 스레드, 자바 스레드 API 등)를 이용하여 작동하고, 사용자 영역에 있는 스레드 여러 개가 커널 영역의 스레드 한 개에 다대일(n:1)로 매핑된다. 여기서 스레드 라이브러리는 스레드의 생성과 종료, 스레드 간의 메시지 전달, 스레드의 스케줄링과 문맥 등 정보를 보관한다.
- 스레드와 관련된 모든 행위를 사용자 영역에서 하므로 커널이 스레드의 존재를 모른다.
- 스레드 교환에 커널이 개입하지 않아 커널에서 사용자 영역으로 전환할 필요가 없다.
- 커널은 스레드가 아닌 프로세스를 한 단위로 인식하고 프로세서를 할당한다(프로세스 테이블 유지) : 다대일 매핑

장점
사용자 영역에서 스레드를 구현하면 커널에서 스레드를 지원할 필요가 없어 다음 장점이 있다.
- 이식성이 높음 : 커널에 독립적으로 스케줄링을 할 수 있어 모든 운영체제에 적용할 수 있다.
- 오버헤드가 적음 : 스케줄링이나 동기화를 하려고 커널을 호출하지 않으므로 커널 영역으로 전환하는 오버헤드가 줄어든다.
- 유연한 스케줄링이 가능 : 커널이 아닌 스레드 라이브러리에서 스레드 스케줄링을 제어하므로 응용 프로그램에 맞게 스케줄링을 할 수 있다.
단점
- 시스템의 동시성을 지원하지 않음 : 스레드가 아닌 프로세스 단위로 프로세서를 할당하여 다중 처리 환경을 갖춰도 스레드 단위로 다중 처리를 하지 못한다. 동일한 프로세스의 스레드 한 개가 대기 상태가 되면 이 중 어떤 스레드도 실행하지 못한다.
- 위에서도 언급했지만 사용자 수준 스레드는 커널 자체가 스레드 한 개로 구성되어 스레드에서 시스템 호출을 실행하면 전체 작업이 이 시스템의 호출 결과를 받을 때까지 기다려야 한다는 단점이 있다.
- 확장에 제약이 따름 : 커널이 한 프로세스에 속한 여러 스레드에 프로세서를 동시에 할당할 수 없어 다중 처리 시스템에서 규모를 확장하기 어렵다.
- 스레드 간 보호 불가능 : 스레드 간 보호에 커널의 보호 방법을 사용할 수 없다. 스레드 라이브러리에서 스레드 간 보호를 제공해야 프로세스 수준에서 보호가 가능하다.
커널 수준 스레드
커널 수준 스레드는 사용자 수준 스레드의 한계를 극복하는 방법으로, 커널이 스레드와 관련된 모든 작업을 관리한다(PCB와 TCB 유지). 한 프로세스에서 다수의 스레드가 프로세서를 할당받아 병행으로 수행하고, 스레드 한 개가 대기 상태가 되면 동일한 프로세스에 속한 다른 스레드로 교환이 가능하다. 이때도 커널이 개입하므로 사용자 영역에서 커널 영역으로 전환이 필요한다.
커널 수준 스레드는 사용자 영역 스레드와 커널 영역 스레드가 일대일(1:1)로 매핑된다. 윈도우 NT, XP, 2000, 리눅스, 솔라리스 9 이상 버전의 운영체제가 커널 수준 스레드를 구현한다.

장점
- 커널 지원 부족 문제 해결 : 커널이 직접 스케줄링하고 실행하기 때문에 사용자 수준의 스레드 커널 지원이 부족한 문제를 해결 할 수 있음
- 스레드 병행 수행 가능 : 커널이 각 스레드를 개별적으로 관리할 수 있어 동일한 프로세스의 스레드를 병행으로 수행할 수 있다. 동일한 프로세스에 있는 스레드 중 한 개가 대기 상태가 되더라도 다른 스레드를 실행할 수 있다.
단점
- 오버헤드가 커짐 : 커널이 전체 프로세스와 스레드 정보를 유지하기 때문에 오버헤드가 커진다.
- 많은 자원이 필요 : 스케줄링과 동기화를 위해 더 많은 자원이 필요하다.
혼합형 스레드
혼합형 스레드는 사용자 수준 스레드와 커널 수준 스레드를 혼합한 구조이다. 이는 시스템 호출을 할 때 다른 스레드를 중단하는 다대일(n:1) 매핑의 사용자 수준 스레드와 스레드 수를 제한하는 일대일(1:1) 매핑의 커널 수준 스레드 문제를 극복하는 방법이다. 즉, 사용자 수준 스레드는 커널 수준 스레드와 비슷한 경량 프로세스(LWP)에 다대다(n:m)로 매핑되고, 경량 프로세스는 커널 수준 스레드와 일대일(1:1)로 매핑된다.
결국 다수의 사용자 수준 스레드에 다수의 커널 스레드가 다대다(n:m)로 매핑된다.
※ 참고
경량 프로세스(LWP, Light Weight Process) : 프로세스의 속성 중 일부가 들어있는 스레드

커널 수준 스레드는 디스패치하고 스케줄링하여 프로세서에서 실행한다. 반면 경량 프로세스는 시스템 호출로 생성해서 커널 영역의 프로세스 문맥 안에서 실행하고, 커널로 독립적으로 스케줄링하여 다중 처리에서는 병렬로 실행한다.
프로세스 하나에는 경량 프로세스가 하나 이상 있고, 경량 프로세스에는 이에 대응하는 커널 스레드가 한 개 있다. 그리고 자원과 입출력 대기를 하려고 경량 프로세스 단위로 대기하므로 프로세스는 입출력을 완료할 때까지 대기할 필요가 없다. 어떤 경량 프로세스가 입출력 완료를 기다리더라도 동일한 프로세스에서 다른 경량 프로세스를 실행할 수 있기 때문이다.
위 그림을 보면 사용자 수준 스레드와 경량 프로세스가 다대다(n:m)으로 연결되어 있는 것을 확인할 수 있다. 이때 사용자 수준 스레드는 스레드 라이브러리가 스케줄링하고 커널 스레드는 커널이 스케줄링하여, 커널이 사용자 수준 스레드와 커널 수준 스레드의 매핑을 적절히 조절한다.
이처럼 혼합형 스레드는 스레드 라이브러리가 최적의 성능을 지원하도록 커널이 경량 프로세스 수를 동적으로 조절하여 사용자 수준 스레드와 커널 수준 스레드가 다대다(n:m)로 매핑된다. 그리고 커널 영역에서 병렬 처리 정도를 이 매핑이 결정할 수 있어 병행 실행의 의미가 없을 때는 다대일(n:1)매핑도 가능하다. 또한, 스레드 풀링을 이용하여 일대일(1:1) 매핑으로 오버헤드를 줄일 수 있다.
솔라리스 9 이전 버전과 ThreadFiber 패키지가 있는 윈도우 NT, 2000 등 운영체제가 혼합형 스레드를 구현한다.
※ 참고
스레드 풀링(thread pooling)
시스템이 관리하는 스레드 풀(pool)을 응용 프로그램에 제공하여 스레드를 효율적으로 사용할 수 있게 하는 방법
이다. 즉, 미리 생성한 스레드를 재사용하도록 하여 스레드를 생성하는 시간을 줄여서 시스템의 부담을 덜어 준다
. 또 동시에 생성할 수 있는 스레드 수를 제한하여 시스템의 자원 소비를 줄여서 응용 프로그램의 전체 성능을 일정 수중으로 유지한다.
스레드는 중량 프로세스와 특징이 동일하면서도 매우 효율적이다.
예를 들어, 다중 스데르 시스템인 매크는 커널이 여러 개의 요청에 동시에 서비스하도록 할 수 있다. 이때 스레드 자신은 동기적이다. 현재 실행하는 스레드가 대기 상태가 되면 동일한 그룹에 있는 다른 스레드를 실행할 수 있다.
다중 스레드와 다중 프로세스 관점에서의 스레드 기능
스레드의 기능은 다중 스레드와 다중 프로세스의 제어를 비교하여 이해하면 쉽다.
다중 프로세스에서는 각 프로세스를 다른 프로세스와 독립적으로 실행하고, 각각 프로그램 카운터, 스택, 레지스터, 주소 공간을 갖는다. 그러므로 프로세서가 하나인 시스템에서는 파일 서버가 디스크 입출력을 기다리는 동안 대기 상태가 될 수 있다. 동일한 주소 공간에서 서버 하나가 대기 상태에 있는 동안 독립적인 다른 서버를 만들 수 없기 때문이다.
그러나 스레드가 여러개인 프로세스 하나는 서버 스레드 한 개가 대기 상태일 동안 동일 프로세스의 다른 스레드를 실행할 수 있다. 따라서 작업량이 증가하고 시스템 전체의 성능이 향상된다.
다중 처리, 다중 프로그래밍, 다중 작업, 다중 스레드
다중 처리(멀티 프로세싱, multi processing)
프로세서 하나 이상이 서로 협력하여 일을 처리하는 것이다. 크로 복잡한 작업으로 프로세서 하나보다는 병렬 처리 여러 개로 하는 것이 더 효율적이다. 이때 프로세서는 컴퓨터 한 대에 있을 수도 있고, 컴퓨터 여러 대에 있을 수도 있다. 따라서 다중 처리의 개념은 컴퓨터로 나누기보다는 프로세서 하나 이상이 작업을 병렬 처리하는 것으로 정의하는 것이 좀 더 정확하다.
다중 프로그래밍(멀티 프로그래밍, multi programming)
프로세서가 IO 작업의 응답을 대기할 동안 다른 프로그램을 실행할 수 있도록 하는 것이다. 요즘은 모든 OS에서 다중 프로그래밍을 지원하여 잘 사용하지는 않지만, 다중 작업과 그 개념이 비슷하여 혼동할 수 있다. 다시 말해, 다중 프로그래밍은 프로세서의 자원 낭비를 최소화하려고 낭비하는 시간을 다른 프로그램(프로세스) 실행에 사용하여 프로세서 하나에서 프로그램(프로세스) 여럿을 교대로 수행할 수 있게 하는 것이다.
다중 작업(멀티 태스킹, multi tasking)
작업(프로그램이 하나 이상일 수도 있음) 이 프로세서 하나에서 OS의 스케줄링에 따라 조금씩 번갈아 가면서 수행하는 것이다. 조금씩 아주 빠르게 동작하여 사용자는 마치 동시에 동작하는 것처럼 느낀다. 다중 프로그래밍이 자원 낭비를 최소화하려고 교대로 작업을 실행한다면, 다중 작업은 이를 좀 더 확장하여 정해진 시간 동안 교대로 작업을 수행한다. 최근에는 다중 프로그래밍보다는 다중 작업이라는 용어를 더 일반적으로 사용한다.
다중 스레드(다중 스레드, multi thread)
프로세스 하나에서 스레드 여러 개를 동시에 실행하는 것이다. 이 스레드들은 공유 메모리 하나를 가져 서로 정보를 주고받는 데 제한이 없다. 반면에 다중 작업은 OS에서 지원하므로 서로 자원을 공유하지 못해 별도의 IPC(Inter-Process Communication) 를 구현하여 자원을 전달해야 하므로 다중 스레드에 비해 OS에 부담을 줄 수 있다. 하지만 다중 작업은 메모리를 독립적으로 수행할 수 있으므로 용도에 맞춰 이 둘을 적절히 사용하는 것이 좋다.
참고