limit
- 결과 중 처음부터 몇개만 가져오기
SELECT * FROM 테이블명 LIMIT 10; -- 처음 부터 10개만 출력하기 (1 ~ 10)
SELECT * FROM 테이블명 LIMIT 100, 10; -- 100번째부터 그 후 10개 출력하기 (101 ~ 110)
offest
- 어디서 부터 가져올지
SELECT * FROM 테이블명 ORDERS LIMIT 20 OFFSET 5; -- 5번째 행 부터 25행 까지 출력 (6 ~ 25)
-- limit 5, 20 과 같다고 보면 된다.
SELECT * FROM 테이블명 ORDERS LIMIT 5, 20
페이징 처리하기
사이트를 만들다보면 무조건 최소 한번은 Paging 을 처리해야하는 화면이 있다.
Mysql 에서는 Limit 과 offset 을 제공하여 훨씬 빠르게 원하는 위치에서 원하는 만큼의 데이터를 가져올 수 있다.
SELECT *
FROM dbtable
WHERE status = 'Y'
ORDER BY CODE
LIMIT 20 OFFSET 0- Limit 은 가져올 데이터 양
- offset 은 가져올 데이터의 초기 위치값이다.
즉, 0(처음) 에서부터 20건의 데이터를 가지고 오라는 의미이다.
Paging 을 하기위해서 0 부분을 변수로 지정하여, 페이지를 이동할때마다 해당 페이지의 offset 값을 계산하여 지정해주면 된다.
물론 위 Paging 방식에는 데이터가 많아지면 질수록 뒤에 있는 데이터를 조회할 때 Paging의 성능이 저하된다는 문제점이 있다.
상황에 따라 수십 초 ~ 수 분까지 느려질 수 있는데, 대량의 데이터를 Paging 할 때에는 단순히 인덱스만 태운다고 해서 성능 문제가 해결되진 않는다.
그 이유는 아래 그림을 보면 쉽게 이해할 수 있다.
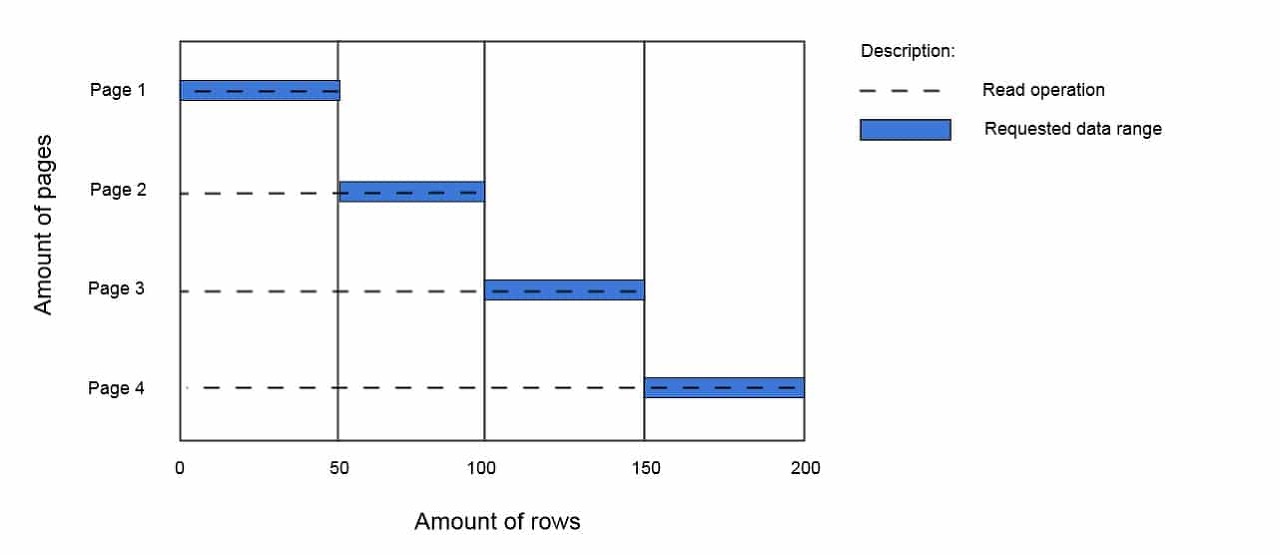
그것은 바로 오프셋 만큼 레코드를 읽어온 후에 필요한 레코드 수를 제외한 "나머지는 버리는 방식(dropped rows)"으로 동작하는 것이다.
LIMIT 50 Offest 50 인 경우 50부터 50개 데이터를 가져오라는 의미일 것이다. 하지만 이때 "나머지는 버리는 방식"으로 인해 0부터 50번 째를 읽고 난 후 버리고 (dropped rows) 그 이후의 데이터를 취한다.
극단적인 예시를 들어보자면, 100만번 째 데이터를 읽으면 어떻게 될까?
100만 건을 읽고 버린 후 그 이후의 데이터를 취하는 굉장히 비효율적인 과정을 거쳐야 한다.
물론, 조회 시간도 현저히 떨어지게 된다.
이것이 왜 위험하냐면 "레코드를 읽는다"라 함은 커버링 인덱스를 적용한 것이 아니라면 디스크 I/O가 발생한다고 볼 수 있다.
위의 예시에서는 100만건이었지만 훨씬 더 큰 5,000만 건, 1억 건을 읽을 수도 있는 것이다.
위와 같은 문제성을 개선할 방법에 대한 포스팅은 추후 다뤄보도록 하겠다.