파티션(partition)
Partition이란 논리적으로 하나의 테이블이지만 실제로는 여러 개의 테이블로 분리해서 관리하는 기법을 말한다.
마치 동일한 형식의 한 개의 테이블을 사용하고 있는 것 같지만, 실제적으로는 여러 개의 물리 파일로 데이터들을 분할하여 보관하는 방식이다.
Partition은 주로 대용량의 테이블을 물리적으로 여러 개의 소규모 테이블로 분산하는 목적으로 사용한다.
개념 정리
- 대량의 데이터를 테이블에 저장할 때, 물리적으로 별도의 테이블로 분리해서 저장시키는 기법을 말한다.
- 단, mysql은 내부적으로 분리되어 처리되기 때문에, 파티션이 얼마나 있든 사용자는 하나의 테이블로 보인다.

- 특정 DML과 Query의 성능을 향상시키고, 주로 데이터가 실시간으로 쌓이는 데이터베이스 환경에서 효율적이다.
- 특히 Full Scan에서 데이터의 접근 범위를 줄여 성능 향상을 가져올 수 있다.
- 물리적인 파티셔닝으로 인해 전체 데이터의 훼손 가능성이 줄어들며, 각 파티션 별로 독립적으로 백업하고 복구할 수 있다.
- 다만, 테이블 간 Join이 일어날 경우 비용이 증가하며 테이블과 인덱스를 별도로 파티셔닝 할 수는 없다.
파티션 종류
- 기본적으로 파티셔닝은 수평 분할과 수직 분할을 사용해서 분할하는데, 분할 기준에 따른 종류는 아래와 같다.

1) 목록 분할 (list partitioning)
코드나 카테고리 등 특정 값을 기반으로 파티션을 나눈다. 즉, 값 목록에 파티션을 할당 분할 키 값을 그 목록에 비추어 파티션을 선택한다. 예를 들어, Country 라는 컬럼의 값이 Iceland , Norway , Sweden , Finland , Denmark 중 하나에 있는 행을 빼낼 때 북유럽 국가 파티션을 구축 할 수 있다.
2) 범위 분할 (range partitioning)
분할 키 값이 범위 내에 있는지 여부로 구분한다. 예를 들어, 우편 번호를 분할 키로 수평 분할하는 경우이다.
3) 해시 분할 (hash partitioning)
해시 함수의 값에 따라 파티션에 포함할지 여부를 결정한다. 예를 들어, 4개의 파티션으로 분할하는 경우 해시 함수는 0-3의 정수를 돌려준다.

4) 합성 분할 (composite partitioning)
상기 기술을 결합하는 것을 의미하며, 예를 들면 먼저 범위 분할하고, 다음에 해시 분할 같은 것을 생각할 수 있다. 컨시스턴트 해시법은 해시 분할 및 목록 분할의 합성으로 간주 될 수 있고 키 공간을 해시 축소함으로써 일람할 수 있게 한다.
아래는 Range를 이용한 파티션의 예시이다.
CREATE DATABASE testDB;
USE testDB;
CREATE TABLE userTable (
userID CHAR(12) NOT NULL
birthYear INT NOT NULL )
PARTITION BY RANGE(birthYear) (
PARTITION part1 VALUE LESS THAN (1970),
PARTITION part2 VALUE LESS THAN (1980),
PARTITION part3 VALUE LESS THAN (1990),
PARTITION part4 VALUE LESS THAN MAXVALUE
);PARTITION BY RANGE(열 이름)으로 지정하면 해당 열에 따라 지정된 파티션으로 테이블이 분할된다. Range의 열은 INT 또는 DATE 형식이어야 한다. 예시에서는 birthYear(출생년도)가 1970 이하면 part1, 1971~1979 이면 part2, 1980~1989 이면 part3, 1990~ 이면 part4 파티션에 내용이 저장되도록 분할했다.
여기서 1968년생의 데이터를 조회한다고 가정해본다면, 원래는 전체 데이터를 조회해야 하지만, 파티션을 사용해서 1/4인 part1 데이터만 조회하고 나머지는 접근하지 않으니까 효율적인 조회를 했다고 볼 수 있다.
ALTER TABLE userTable
REORGANIZE PARTITION part4 INTO (
PARTITION part4 VALUES LESS THAN (2000),
PARTITION part5 VALUES LESS THAN (MAXVALUE)
);만약 파티션을 한번 더 분할하도록 수정하고자 한다면 ALTER TABLE ... REORGANIZE PARTITION문을 사용하면 된다. 파티션을 추가할 때는 REORGANIZE가 아니라 ADD를 사용해야 하는데, part4에 MAXVALUE를 설정했기 때문에 이를 수정해야 해서 REORGANIZE를 사용했다. 아래의 쿼리도 실행해야만 적용이 된다.
OPTIMIZE TABLE userTable;재구성된 파티션을 적용하려면 OPTIMIZE 테이블문을 사용하면 수정했던 부분들이 적용된다.
Partition 고려 상황
가령 유저 분석을 위한 유저의 활동 기록을 저장하는 DB를 생각해보자. 하루 활동 유저 수가 천 명일 때, 한 달 만해도 많은 수의 데이터가 쌓일 것이다.
이렇게 쌓인 데이터에서 특정 월을 기준으로 모든 데이터를 검색하거나, 혹은 특정 활동을 한 유저를 통계를 위한 검색을 하면 DB 부하를 크게 주게 된다.
이 때 모든 데이터에서 검색하는 것보다 특정 기준 값으로 분리된 파일들 중에서 찾는 것이 성능상 유리할 수 있기 때문에 partition으로 나누는 것을 고려할 수 있다.
partition은 유리한 상황이 분명 존재하지만, 어떤 쿼리가 사용될지에 따라 오히려 성능이 나빠질 수도 있다.
그렇다면 언제 Parition 사용을 고려해볼 수 있을까?
Case 1. 무거운 인덱스 (INSERT와 범위 SELECT의 빠른 처리)
: 인덱스가 많이 걸려 무거워진 경우
UPDATE 와 DELETE 문 처리 시 대상 레코드를 검색하기 위해서 인덱스를 통한 검색이 필수적이다.
하지만 인덱스가 커질수록 SELECT, INSERT, UPDATE, DELETE 작업이 함께 느려진다.
INSERT 시 B-Tree 구조로 인하여 만약 리프 노드가 꽉 차서 더는 저장할 수 없을 때는 리프 노드가 분리(Split)가 되게 되며 Index Split 시에도 큰 인덱스보다는 작은 크기의 인덱스가 유리할 수 있다.
즉, 테이블의 사이즈의 커서 인덱스의 크기가 메모리 크기 보다 훨씬 큰 경우 파티션 테이블을 이용하여 분할 할 경우 인덱스도 각각 생성되기 때문에 작은 인덱스 크기로 인해 메모리에서 빠르게 쿼리 작업을 진행할 수 있다.

위 그림을 보면 파티션하지 않고 하나의 큰 테이블을 사용하여 인덱스를 구성하면, 그만큼 물리적인 메모리 공간도 많이 필요해진다는 사실을 알 수 있다.
Case 2. Working Set
: Working Set 기준으로 나눌 수 있는 경우
데이터의 특성에는 전체 데이터 셋에서 자주 찾는 데이터 그룹이 존재하게 되는데, 이렇게 모든 데이터 중 자주 사용되는 데이터를 Working Set이라고 한다.
테이블의 데이터는 실질적인 물리 메모리보다 큰 것이 일반적이겠지만 인덱스의 Working Set이 실질적인 물리 메모리보다 크다면 쿼리 처리가 상당히 느려질 것이다.
따라서 테이블의 데이터를 활발하게 사용 되는 Working Set과 그 외의 부분으로 나눠서 파티션할 수 있다면 상당히 효과적으로 성능을 개선할 수 있다.
Case 3. 주기적으로 삭제 등의 작업이 이루어지는 이력성 데이터의 효율적인 관리
비지니스 로직이나 제도화된 법에 의해서 필수 보관주기가 지난 데이터의 정리나 로그성 데이터의 테이블을 파티션 테이블로 관리한다면 불필요한 데이터 삭제 작업은 단순히 파티션을 추가하거나 삭제하는 방식으로 간단하고 빠르게 해결할 수 있다.
DML 인 Delete 로 처리하게 된다면 삭제 대상을 조회하는 부하/Operation 과 Redo/Undo를 생성하는 DML영역의 Operation 의 부하 등이 동반되기 때문에 파티션을 사용한 파티션 단위의 Drop 을 이용하면 이런 부분을 대폭 줄일 수 있다.
파티션 사용법
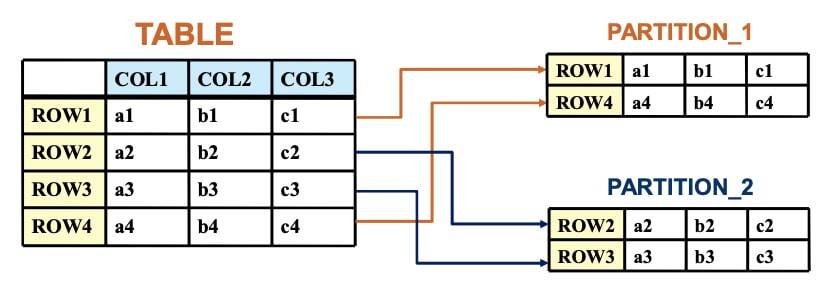
파티션 테이블 생성
PARTITION BY
연 별 데이터를 나누고 싶다면 아래와 같이 정의할 수 있다.
create database if not exists partDB ;
use partDB ;
drop table if exists partTbl ;
create table partTbl (
userID char(8) not null,
name varchar(10) not null,
birthYear datetime not null, -- 생일날짜가 파티션 범위 대로 정렬된다.
addr char(2) not null
)
partition by range(TO_DAYS(birthYear)) ( -- 출생년도를 기준으로 분할한다.
partition part1 values less than (TO_DAYS('1970')), -- 1970년 이하
partition part2 values less than (TO_DAYS('1978')), -- 1971 ~ 1978
partition part3 values less than MAXVALUE -- 1979 ~
) ;
insert into partTbl select userID, name, birthYear, addr from sqlDB.userTbl ;
-- 테이블 데이터 복사
select * from partTbl where birthYear <= 1965 ;
-- 파티션 전에는 전체 테이블을 다 뒤졌지만, 파티션을 나누었기 때문에 해당 범위인 part1 파티션만 뒤져서 성능이 올라간다.partTbl 테이블의 birthYear 컬럼은 파티션 키가 되어 레코드가 어떤 파티션에 저장될지를 결정한다. Parition의 키의 역할이 되는 중요한 역할을 하게 되는 것이다.
각 데이터를 고루 분할하고, 명확한 기준으로 나누는 값을 사용해야만 한다.
참고로, 파티션은 동일한 테이블의 형식으로 나눌 뿐, 파티션 별 다른 형태를 갖지 않는다.
가령 각각 다른 인덱스를 생성하는 등의 형태는 지원하지 않는다.
Functions
partTbl 테이블은 birthYear 칼럼에서 TO_DAYS( ) 라는 MySQL 내장 함수를 이용해 날짜만 추출하고, 그 날짜를 이용해 테이블을 연도 범위별로 파티션한다.
ABS(), CEILING(), EXTRACT(), FLOOR(), MOD(),
DATEDIFF(), DAY(), DAYOFMONTH(), DAYOFWEEK(), DAYOFYEAR(), HOUR(), MICROSECOND(), MINUTE(),
MONTH(), QUARTER(), SECOND(), TIME_TO_SEC(), TO_DAYS(), TO_SECONDS(), UNIX_TIMESTAMP(),
WEEKDAY(), YEAR(), YEARWEEK()위와 같은 MySQL 내장 함수를 사용하여 파티션에 사용할 수 있다.
파티션 확인
select table_schema, table_name, partition_name, partition_ordinal_position, table_rows
from information_schema.partitions
where table_name = 'partTbl' ;explain partitions select * from partTbl where birthYear <= 1965 ;
-- 어떤 파티션에서 뒤지는지 확인 용도파티션 더 쪼개기
alter table partTbl
reorganize partition part3 into (
partition part3 values less than (1985), -- 파티션3을 더 쪼갰다.
partition part4 values less than MAXVALUE
) ;
optimize table partTbl ; -- 파티션 작업된 테이블 적용파티션 합치기
alter table partTbl
reorganize partition part1, part2 into (
-- part1와 part2 파티션을 합쳐서 새로운 파티션 part12를 만든다.
partition part12 values less than (1978)
) ;
optimize table partTbl ;파티션 삭제
- 파티션을 지우면, 그 파티션에 해당하는 데이터도 지워진다.
alter table partTbl drop partition part12 ;
optimize table partTbl ;
Search, Insert, Update 시 파티션 처리 과정
Search
위의 파티션 고려사항에서 파티션을 사용하면서 오히려 성능이 더 떨어질 수도 있다고 했었다.
사용할 쿼리가 어떤 것일지를 고민해보고, 좋은 성능이 기대된다면 파티션을 사용할 수 있다.
데이터 검색을 먼저 구분해보자면, WHERE 절의 조건으로 아래와 같은 사항을 따져볼 수 있다.
- 검색할 파티션을 찾을 수 있는지
- 인덱스를 효율적으로 사용할 수 있는지 (Index Range Scan)
CASE 1 📌 파티션 선택 O + 인덱스 효율 O
이때는 파티션의 개수와 관계없이 검색을 위해 꼭 필요한 파티션의 Index Range Scan하는 경우를 의미한다.
두 조건이 모두 가능할 때 쿼리가 가장 효율적으로 처리될 수 있다.
CASE 2 📌 파티션 선택 X + 인덱스 효율 O
이 경우 우선 테이블의 모든 파티션을 대상으로 검색해야 하지만, 각 파티션에 Index Range Scan을 사용할 수 있다.
최종적으로 테이블에 존재하는 모든 파티션의 개수만큼 Index Range Scan 검색 하게 된다.
이 작업은 파티션 개수만큼의 테이블에 대해 Index Range Scan 을 한 다음, 결과를 병합해서 가져오는 것과 같다.
CASE 3 📌 파티션 선택 O + 인덱스 효율 X
검색하려는 레코드가 저장된 파티션을 선별할 수 있기 때문에, 파티션 개수와 관계없이 검색을 위해 필요한 파티션만 읽으면 된다.
하지만 인덱스는 이용할 수 없어서 대상 파티션에 대해 Full Table Scan 하기 때문에, 각 파티션의 레코드 건수가 많다면 상당히 느리게 처리된다.
CASE 4 📌 파티션 선택 X + 인덱스 효율 X
테이블의 모든 파티션을 검색해야 하고 각 파티션에서도 Full Table Scan을 수행해야 된다.
최악의 경우이다.
CASE 3, 4와 같은 경우가 발생한다면 파티션을 지양하는 것이 좋다.
INSERT
Partition을 통해 데이터를 조회할 때는 파티션 키로 정한 데이터를 기준으로 파티션이 결정한 후,
파티션이 결정되면 나머지 과정은 파티션되지 않은 일반 테이블과 동일하게 처리된다.

데이터를 조회할 때 파티션 키 값을 통해 조회하면 좋은 성능을 기대할 수 있지만, 반대로 없다면 테이블의 모든 파티션에서 검색해야 한다.
파티션을 사용하는 의미가 사라질 수 있으니, 최대한 파티션 키를 통해 데이터를 찾을 수 있게끔 조건을 걸어주는 것을 권장한다.
UPDATE
데이터를 변경할 때는 파티션 키를 변경하는지 아닌지로 구분해서 설명할 수 있다.
#1. 파티션 키 외의 데이터 수정
먼저, 파티션 키 외의 데이터가 수정될 때에는 파티션이 적용되지 않은 일반 테이블과 마찬가지로 칼럼 값만 변경하면 된다.
#2. 파티션 키 칼럼이 변경될 때
아래와 같이 기존의 레코드가 저장된 파티션에서 해당 레코드를 삭제한다. 그리고 변경되는 파티션 키 칼럼의 표현식을 평가한 후,그 결과를 이용해 레코드를 이동시킬 새로운 파티션을 결정해서 레코드를 새로 저장한다.

Index 별 파티션 처리 과정
모든 인덱스는 파티션 단위로 생성된다.
MySQL의 파티션 테이블에서 인덱스는 전부 로컬 인덱스로, 테이블 단위의 글로벌한 인덱스는 지원하지 않는다.

파티션되지 않은 테이블에서는 인덱스를 순서대로 읽으면 그 칼럼으로 정렬된 결과를 바로 얻을 수 있지만, 파티션된 테이블은 인덱스가 분리되어 있기 때문에 다르게 동작한다.
먼저, 검색하려는 대상 데이터를 각 파티션에서 가져온다
각 파티션 별로 데이터를 가져왔다면 가져온 데이터들을 병합을 해야 할텐데, 이 데이터들을 어떻게 합쳐야 할까?
일반 테이블의 인덱스 스캔처럼 결과를 바로 반환하는 것이 아니라, 여러 파티션에 대해 인덱스 스캔을 수행할 때 각 파티션으로부터 조건에 일치하는 레코드를 정렬된 순서대로 읽으면서 우선순위 큐(Priority Queue)에 임시로 저장하여 가져온다.
즉, 각 파티션 에서 읽은 데이터가 이미 정렬되어 있기 파티션에 접근한 후 그 순서대로만 가져오며, 내부적으로 큐 처리를 한다.
Partition pruning
: 최적화 단계에서 필요한 파티션만 골라내고 불필요한 것 들은 실행 계획에서 배제
옵티마이저가 다수의 파티션 중 일부만 읽어도 된다고 판단되면 불필요한 파티션에는 전혀 접근하지 않는다.
가령 202208 월 범위 내의 해당하는 데이터를 읽고자 한다면 그 이외의 파티션 (202207, 202209 ...)에는 전혀 접근하지 않는다.
실제로 쿼리 플랜을 확인해보면 partition 에 해당하는 데이터로는 P_202208밖에 없음을 알 수 있다.
mysql> EXPLAIN SELECT * FROM users WHERE reg_at > '20220801' AND reg_at > '20220801';
+----+------------+------------+-------+---------+---------+------+--------------------------+
| id | table | partitions | type | key | key_len | rows | Extra |
+----+------------+------------+-------+---------+---------+------+--------------------------+
| 1 | tb_article | P_202208 | index | PRIMARY | 9 | 1 | Using where; Using index |
+----+------------+------------+-------+---------+---------+------+--------------------------+
파티션 주의할 점
- 파티션 테이블에는 외래 키를 설정할 수 없다. (부모 테이블로서의 역할만 됨)
- 그러므로 단독으로만 사용되는 테이블에만 파티션을 설정 할 수 있다.
- 스토어드 프로시저, 스토어드 함수, 사용자 변수 등을 파티션 식에 사용할 수 없다.
- 임시 테이블(with)은 파티션을 사용할 수 없다.
- 파티션 키에는 일부 함수만 사용할 수 있다.
- MySQL은 파티션 개수는 최대 1,024개까지 지원한다.
- 레인지 파티션은 숫자형 연속된 범위를 사용하고
- 리스트 파티션은 숫자형 또는 문자형 연속되지 않은 값(지역별, 혈액형 등)을 사용한다.
따라서 리스트 파티션은 MAXVALUE개념이 존재하지 않는다.
참고
추가적인 파티션 사용법은 아래 포스팅을 참고
MySQL Partition, 제대로 사용하기 (2)
MySQL의 Parition 의 사용법을 알아보며 실제 저장 과정을 분석하는 것이 본 포스팅의 목표입니다. 지난 포스팅 MySQL Partition, 제대로 이해하기 (1)에 이어 이번 포스팅은 Parition의 사용법에 대해 다루
gngsn.tistory.com
.