TCP/ IP 전송 계층 (Transport Layer)
TCP/IP는 인터넷에서 사용하는 프로토콜 그룹을 말한다. TCP/IP는 Application layer(응용계층), Transport layer(전송계층), Network layer, Data link layer, Physical layer로 5개의 계층으로 나뉜다.

그 중에 전송계층은 두 응용 계층 사이에서의 신뢰성 있는 process-to-process 통신을 제공한다. 전송계층은 응용계층으로부터 메시지를 받아 전송계층 패킷으로 캡슐화하여 전송한다.(segment 또는 datagram으로 부름.)
Q) 패킷(Packet)이란?
인터넷 내에서 데이터를 보내기 위한 경로배정(라우팅)을 효율적으로 하기 위해서 데이터를 여러 개의 조각들로 나누어 전송을 하는데 이때, 이 조각을 패킷이라고 한다.
전송계층의 주된 프로토콜은 TCP, UDP가 있다.
- TCP(Transmission Control Protocol)는 연결형, 신뢰성 전송 프로토콜로 TCP로 전송하는 패킷을 segment라고 부른다.
- UDP(User Datagram Protocol)는 비연결형, 비신뢰성 전송 프로토콜로 UDP로 전송하는 패킷을 datagram이라고 한다.
즉, 전송계층은 프로토콜 내에서 송신자와 수신자를 연결하는 통신 서비스를 제공하는 계층이라고 할 수 있고 End Point간 신뢰성있는 데이터 전송을 담당한다.
- 신뢰성 : 데이터를 순차적, 안정적인 전달
- 전송 : 포트 번호에 해당하는 프로세스에 데이터를 전달
HTTP / IP / TCP / UDP 는 모두 프로토콜
프로토콜은 클라이언트와 서버가 정보를 교환할 수 있도록 하는 메시지 형식에 대한 규칙 이라고 보면 된다.
수신 호스트가 전송 받은 메시지를 이해하려면 설계된 규칙에 따라 작성된 데이터 형식이어야 한다는 말이다.
예를들어 HTTP 메세지 헤더도 결국 일종의 규칙이며, IP의 숫자도 규칙이라고 말할 수 있다. 만일 규칙을 깨는 256.256.256.256 와 같은 형식은 존재하지도 않는 IP이며 작동하지도 않는다.
HTTP와 IP 프로토콜에 대해서 배우게되면 바로 그 다음 접해보는 프로토콜이 바로 TCP / UDP 일 것이다.
다만 이 TCP와 UDP에 대해서 귀가 아플정도로 들어봤겠지만 아무리 들어도 개념이 애매하게 느껴진다.
왜냐하면 HTTP 같은 경우 브라우저의 개발자 도구의 네트워크 탭에서 HTTP 메세지의 헤더(header)로 어떠한 구조로 메세지를 주고 받는지 눈으로 결과값을 확인할 수 있으며, 또한 IP 같은 경우 192.168.10.1 같이 숫자로 이루어져 무언가 주소값을 나타내고 있다는 것임을 알수 있고, 브라우저에 IP로 접속하면 해당 홈페이지로 이동해 어떠한 네트워킹 동작이 일어나고 있음을 직감할 수 있기 때문이다.
그러나 TCP / UDP는 3-HandShake니 신뢰성니 뭐니 지겹게 개념 단어와 표, 그림은 봐왔지만, 실질적인 통신 결과와 같은 눈으로 보이는게 없어 순 이론 덩어리로 느껴 들어도 잘 와닿지 않는게 현실이다.
사실 TCP만 해도 굉장히 오래된 역사를 지닌 프로토콜이라 이에 대한 이론도 몇백장이 넘어갈정도로 굉장히 방대하다. 따라서 이번 포스팅에서는 TCP와 UDP에 대한 이론을 친숙하게 접근하여 살펴보고, 시각적으로 빠르게 개념을 다지고 넘어가는 것을 목표로 한다.
그리고 상대적으로 빈약하게 배우는 UDP에 대해서 최신 기술인 HTTP 3.0와 같이 왜 각광을 받았는지에 대해 알아볼 것이다.
TCP - 전송 제어 프로토콜
TCP는 신뢰성 있는 데이터 전송을 지원하는 연결 지향형 프로토콜이다. 일반적으로 TCP와 IP가 함께 사용되는데, IP가 데이터의 전송을 처리한다면 TCP는 패킷 추적 및 관리를 하게 된다.
즉, IP(Internet Protocol)가 인터넷 프로토콜로서 복잡한 인터넷 망 속에서 클라이언트와 서버 간에 통신할 수 있게 IP 주소와 패킷과 같은 규칙을 통해 통신을 하게 하는 것이라면,
TCP(Transmission Control Protocol)는 IP 규칙으로만 통신하기에 부족하거나 불안정하던 여러 단점들(패킷 순서가 이상하거나 패킷이 유실)을 커버해, 패킷 전송을 제어하여 신뢰성을 보증하는 프로토콜로 보면 된다.
IP와 TCP 둘다 프로토콜이지만 이 둘을 동일시로 보면 안된다. 이 둘은 별개의 규칙이다.
IP 규칙에 써있는대로 목적지까지 다다랐으면, TCP 규칙에 써있는대로 올바르게 도착했는지 정확히 누구에게 전달되야하는지 하나하나 따진다고 생각하면 된다. 그래서 은행 업무나 메일과 같은 반드시 수신자가 정보를 받아야하는 신뢰성 있는 통신이 필요할때 사용된다.

TCP는 연결지향적 서비스를 제공하기 위해 데이터를 전송하기 전에 먼저 두 호스트의 전송 계층 사이에 논리적 연결(3 way-handshake)을 설립한다. - 양방향 통신
그 후 데이터 전송을 하고 데이터 전송을 완료했으면 연결을 해제한다. TCP의 통신은 이렇게 connection setup, data transfer, connection termination의 세 단계로 나뉜다.
신뢰성 있는 서비스를 제공하기 위해 TCP는 전체 스트림을 순서에 맞고 오류 없이, 또한 부분적인 손실이나 중복 없이 전송하는 것을 보장한다.
이를 가능하게 하는 방법은 오류제어, 흐름제어, 혼잡제어 등이 있다.
- 데이터의 순차 전송을 보장한다.
- 흐름제어 : 데이터를 보내는 속도와 데이터를 받는 속도의 균형을 맞추는 것을 뜻한다.
- 오류제어 : 훼손된 segment의 감지 및 재전송, 손실된 segment의 재전송, 순서가 맞지 않게 도착한 segment를 정렬하고 중복 segment 감지 및 폐기를 진행한다. 이는 TCP header의 checksum, 확인응답, 타임-아웃 등을 통해 수행된다.
- 혼잡제어 : 네트워크 내의 패킷 수가 넘치게 증가하지 않도록 방지하는 것을 말한다.
Q) TCP는 패킷을 어떻게 추적 및 관리하나?
위에서 데이터는 패킷단위로 나누어 같은 목적지(IP계층)으로 전송된다고 설명하였다. 예를 들어 한줄로 서야하는 A,B,C라는 사람(패킷)들이 서울(발신지)에서 출발하여 부산(수신지)으로 간다고 하자. 그런데 A,B,C가 순차적으로 가는 상황에서 B가 길을 잘못 들어서 분실되었다. 하지만 목적지에서는 A,B,C가 모두 필요한지 모르고 A,C만 보고 다 왔다고 착각할 수 있다. 그렇기 때문에 A,B,C라는 패킷에 1,2,3이라는 번호를 부여하여 패킷의 분실 확인과 같은 처리를 하여 목적지에서 재조립을 한다. 이런 방식으로 TCP는 패킷을 추적하며, 나누어 보내진 데이터를 받고 조립을 할 수 있다.
TCP의 안전 포장
좀 더 친숙하게 접근하기 위해 예시를 들어 설명해보자.
인터넷 통신을 택배 수하물로 비유하자면, IP는 단순히 배달 주소지라고 하면 TCP는 이 배달지로 문제없이 전송되도록 택배 스티커와 같은 여러 부가 정보들을 가미한 것이라고 보면 된다. 단순히 목적지 뿐만 아니라 순서, 검증, 전송 제어 정보가 들어있어 IP 주소지로만 물품을 배달하기엔 불안정한 부분들을 확실하게 커버하여 배달품이 목적지까지 안전하게 도착하도록 보증한다.
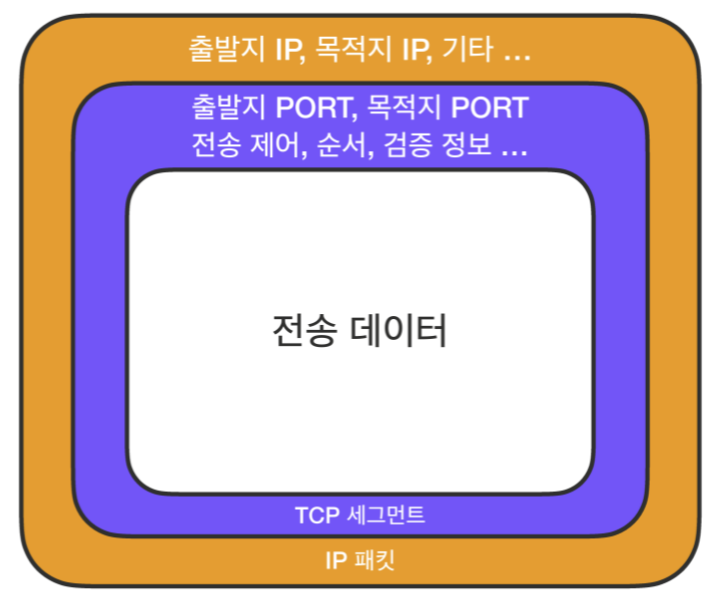
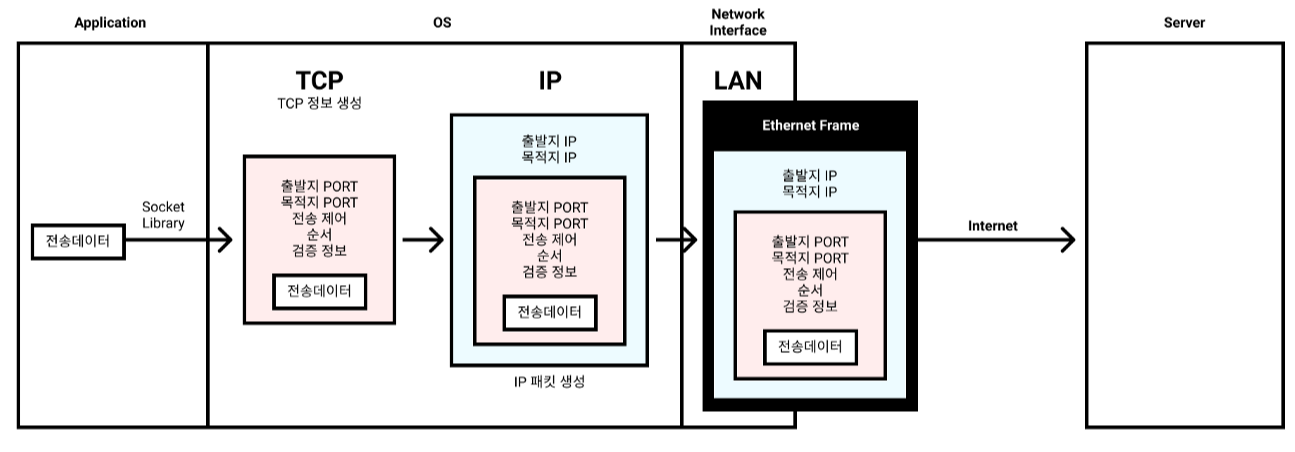
전송 데이터가 포장되는 과정을 나열해보면 아래 그림과 같다.
다만 이부분은 OSI 7 Layer와 더불어 TCP/IP 4계층에 대해 알고 있어야 이해가 가능하지만, 이 포스팅에서 네트워킹 까지 자세히 다루기에는 무리가 있어 그림으로 간단하게 표현하였다.
- 전송데이터를 TCP 포장한다.
- 포장한 전송데이터를 IP 포장한다
- 포장한 전송데이터를 이더넷 포장한다
- 인터넷을 통해 상대 컴퓨터 서버에 도달하여 포장된걸 하나씩 풀며 전송데이터를 받게 된다
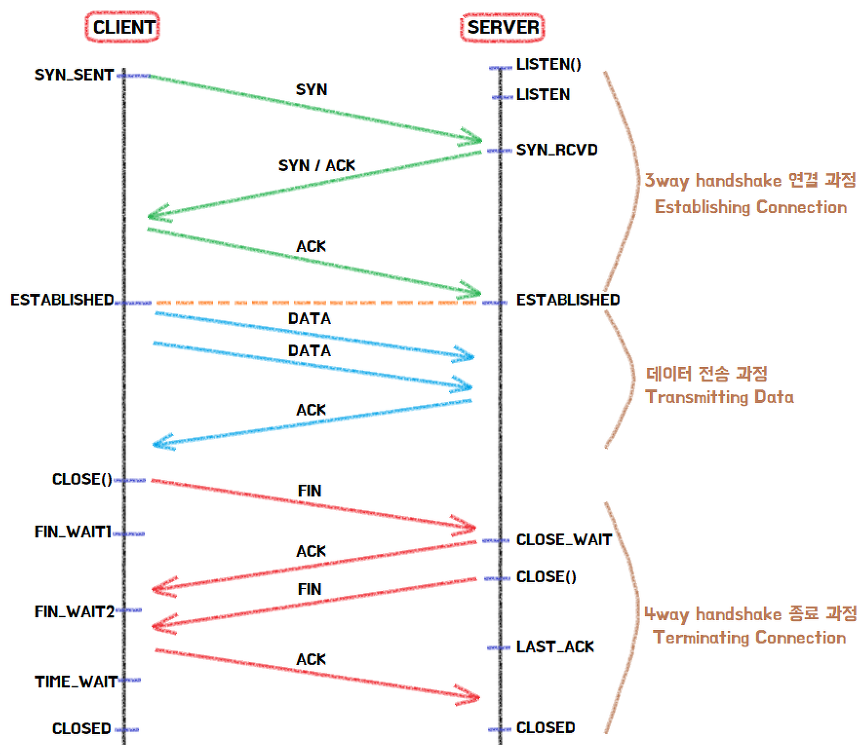
TCP의 통신 확인 방법
TCP는 신뢰성 프로토콜 답게, 배달 하기전에 목적지가 무사한지 미리 확인하고 배달을 끝나고도 또 확인도 해주는 굉장히 친절한 프로토콜이다. 통신을 시작할 때와 종료할 때 서로 준비가 되어있는지를 반드시 미리 먼저 물어보고 패킷을 전송할 순서를 정하고 나서야 본격적인 통신을 시작하기 때문이다.
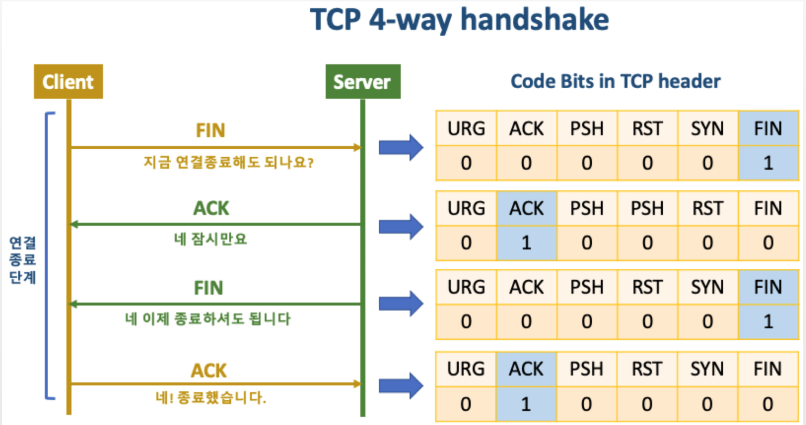
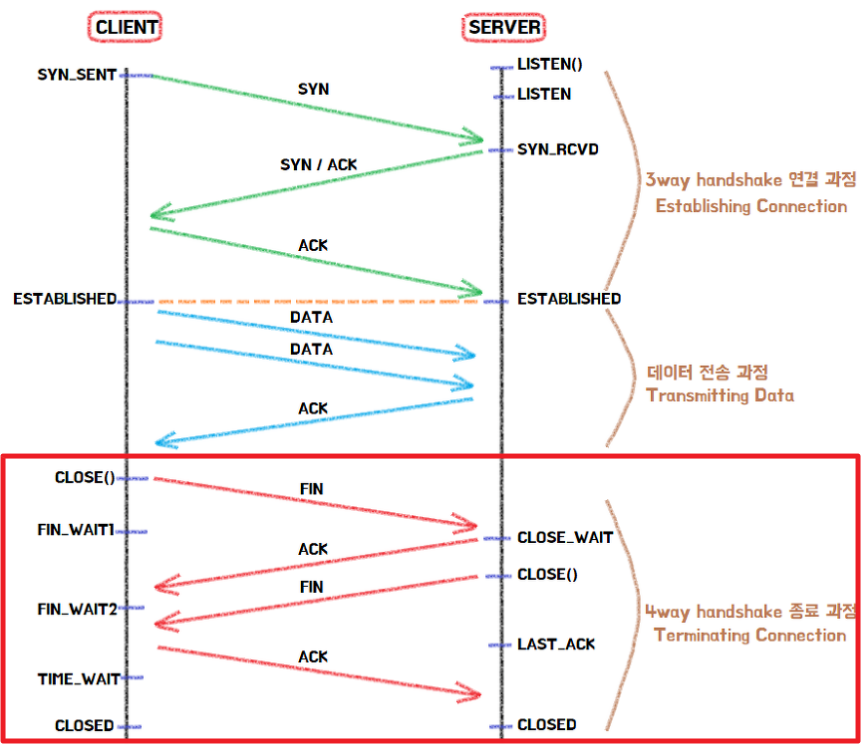
이러한 과정이 바로 3 Way Handshake 와 4 Way Handshake 과정이다.
둘다 똑같은 핸드쉐이크(Handshake)지만, 3 Way는 통신을 시작할때, 4 Way는 통신을 마칠때 거치는 과정이라는 차이만 있을 뿐이다.
한마디로 한번 통신하는데 Handshake를 두번 해서 신뢰성을 보장한다고 생각하면 된다.
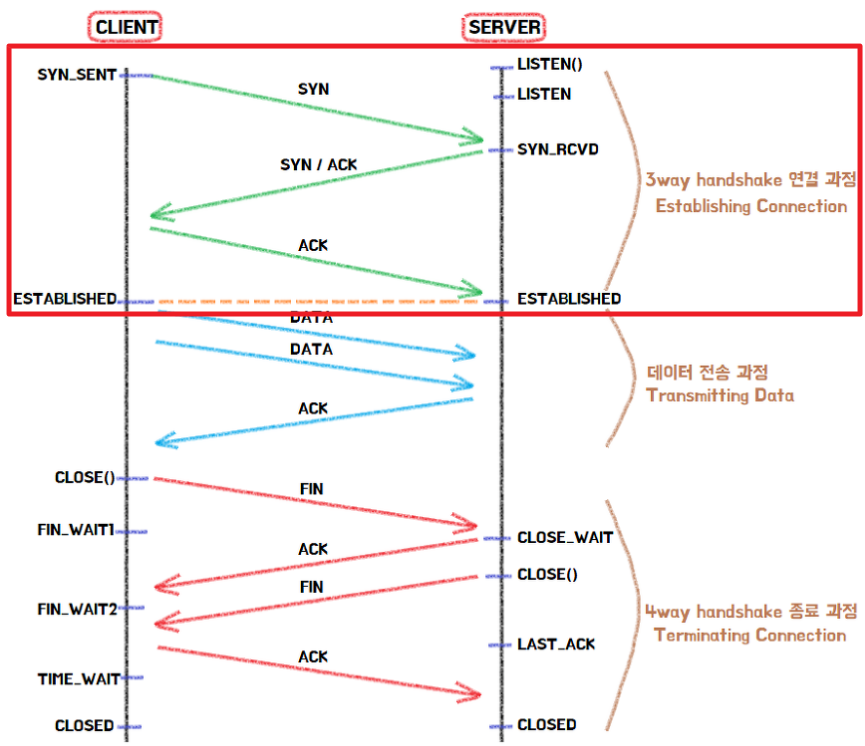
아래 그림을 보면 클라이언트가 처음 서버와 통신을 하기 위해 TCP 연결을 생성할 때 SYN와 ACK이라는 패킷을 주고 받고, 통신을 종료하는 과정에선 FIN이라는 패킷을 주고 받고 있는 걸 확인 할 수 있다.
단어가 생소하다고 해서 어렵게 생각하지말고 그냥 내가 너 한테 전송하였다는 인증 도장 정도로 생각하면 된다.
즉, 패킷 내부에 들어있는 인증 플래그 값들을 확인하여 클라이언트와 서버가 서로 보낸 패킷의 순서와 패킷을 제대로 받았는 지를 검증하는 것이다.
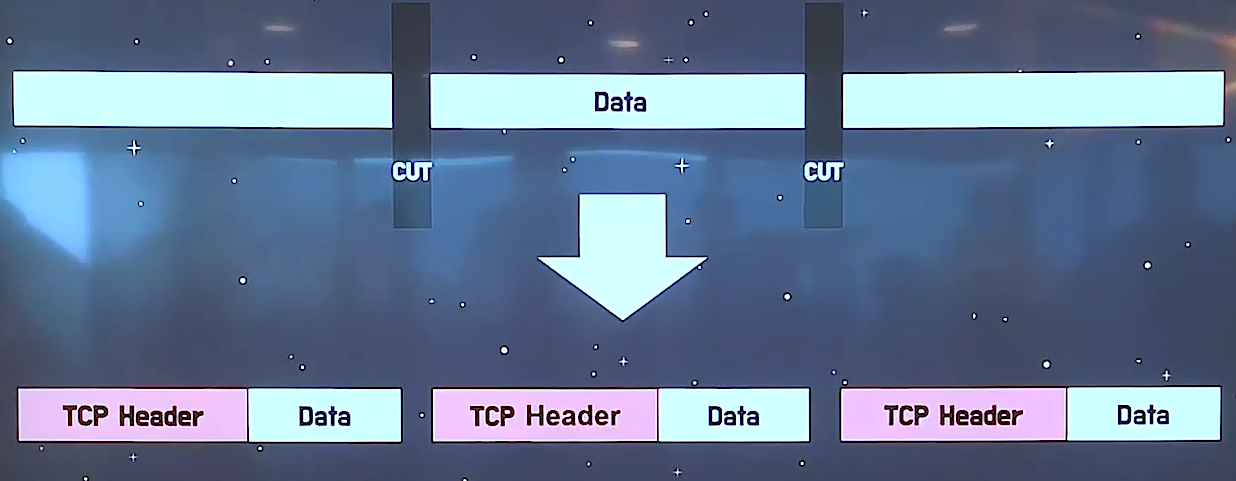
세그먼트 (Segment) - TCP 프로토콜의 PDU
세그먼트 : 어플리케이션 단에서 전송 받은 메시지를 쪼개서 TCP Header를 추가하여 만들어진 TCP의 데이터 단위
주요 flag 종류
| FLAG | 설명 |
| SYN | 접속요청을 할 때 보내는 패킷을 말한다. TCP접속시에 가장 먼저 보내는 패킷이다. |
| ACK | 상대방으로부터 패킷을 받은 뒤에, 잘 받았다고 알려주는 패킷을 말한다. 다른 플래그와 같이 출력되는 경우도 있다. |
| PSH | 데이터를 즉시 목적지로 보내라는 의미이다. |
| FIN | 접속종료를 위한 플래그 이 패킷을 보내는 곳이 현재 접속하고 있는 곳과 접속을 끊고자 할 때 사용한다. |
위에서 살펴봤다시피 TCP 통신은 아래와 같은 3단계의 과정을 거친다.
- Connection setup (tcp 연결 초기화) - 3way handshaking
- Data transfer (데이터 전송)
- Connection termination (tcp 연결 종료) - 4way handshaking
각각 하나씩 알아보도록 하자.
3-way handshake 과정
3-way handshake는 TCP/IP 프로토콜로 통신하기 전, 정확한 정보 전송을 위해 상대방 컴퓨터와 연결을 하는 과정이다.(TCP 연결 초기화)
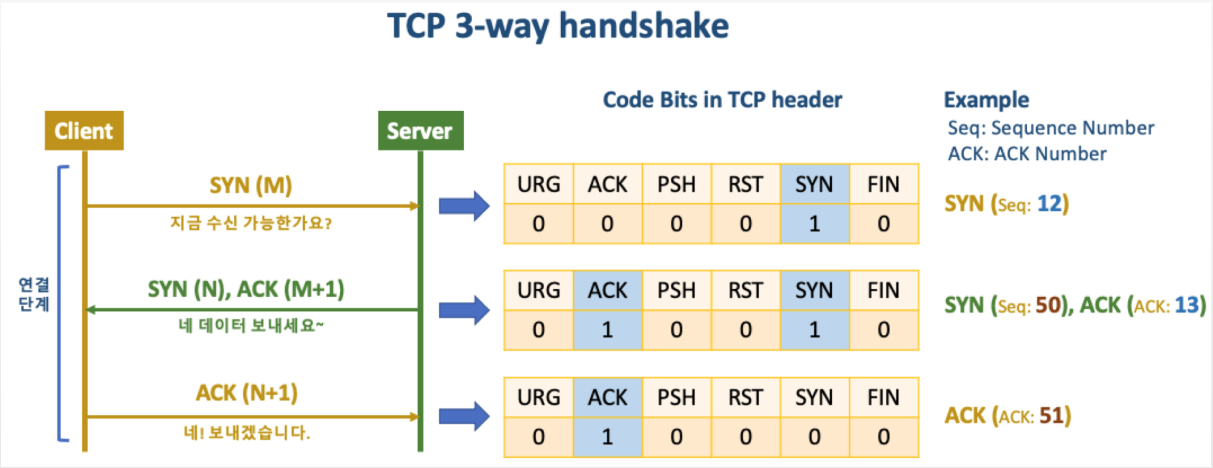
- SYN : 접속 요청
- ACK : 요청 수락
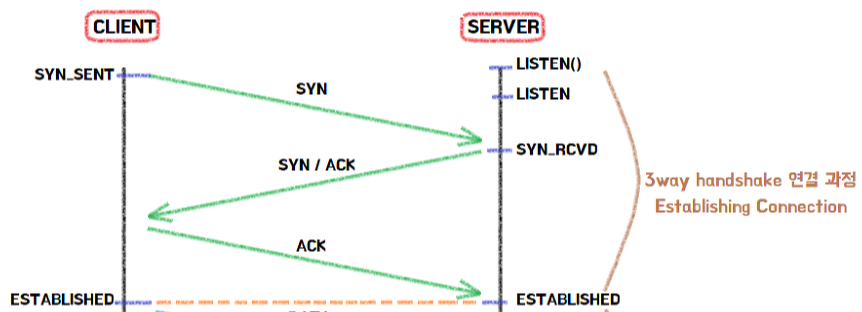
- 클라이언트는 접속을 요청하는 SYN 패킷을 보낸다.
이때 클라이언트는 응답을 기다리기위해 SYN_SENT 상태로 변한다. - LISTEN 상태였던 서버는 SYN 요청을 받으면, 클라이언트에게 요청을 수락하는 ACK 패킷과 SYN 패킷을 보낸다. (서버도 클라이언트에 접속해야 양방향 통신이 되기 때문에)
그리고 SYN_RCVD(SYN_RECEIVED)상태로 변하여 클라이언트가 ACK 패킷을 보낼 때 까지 기다리게 된다. - 클라이언트는 다시 서버에 ACK 패킷을 보내고, 이 후 ESTABLISHED 상태가 되어 데이터 통신이 가능하게 된다.
ex) HTTP 1.1 과 2.0 버전은 모두 TCP프로토콜을 사용한다. 그래서 우리가 네이버에 접속할 때마다 네이버의 서버와 나의 노트북이 3-way handshake를 하면서 서로를 확인하게 된다.
TCP 순서 보장 방법
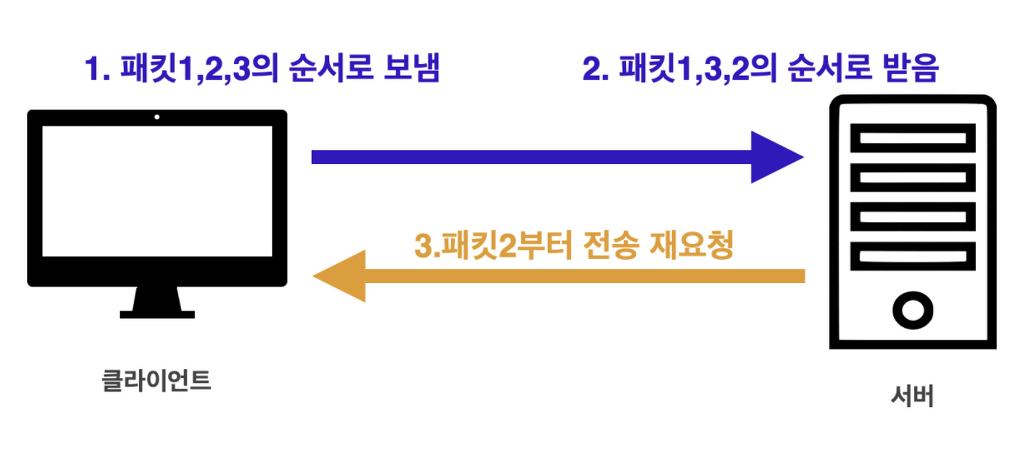
- 클라이언트에서 패킷1, 패킷2, 패킷3 순서로 전송
- 서버에서 패킷1, 패킷3, 패킷2 순서로 받음
- 서버에서 패킷2번부터 다시 보내라고 클라이언트에게 요청(TCP 기본 동작)
※ 참고
이렇게 패킷을 순서대로 제어를 할 수 있는 이유는 TCP 데이터 안에 전송 제어, 순서, 정보들이 있기 때문이다.
그래서 TCP는 신뢰할 수 있는 프로토콜이라고 얘기한다.
데이터 통신 과정
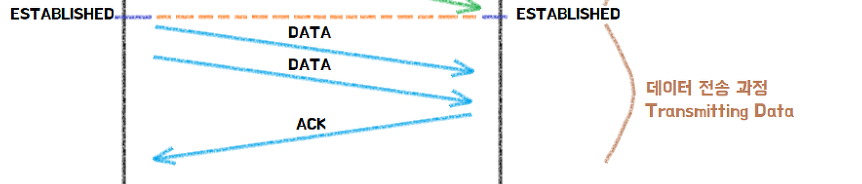
- Established 된 상태에서 서버에게 데이터를 보낸다.
- 서버는 잘 전송받았다고 ACK 플래그를 넣어 응답한다.
- 만약 클라이언트가 서버로부터 ACK를 못받았으면 제대로 송신하지 못한걸로 판단하고 데이터를 재전송을 한다.
4-way handshake 과정
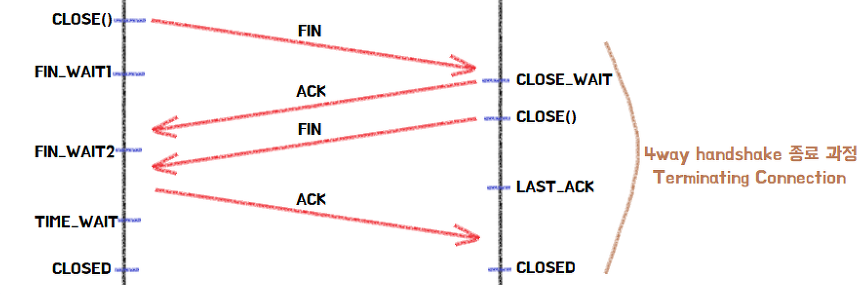
- 서버와 클라이언트가 TCP 연결이 되어있는 상태에서 클라이언트가 접속을 끊기 위해 CLOSE() 함수를 호출한다.
그러면 FIN 플래그를 보내게 되고 클라이언트는 FIN_WAIT1 상태로 변한다. - 서버는 클라이언트가 CLOSE() 한다는 것을 알게되고 CLOSE_WAIT 상태로 바꾼 후 ACK 플래그를 전송한다.
만일 서버에서 클라이언트로 보낼 남은 데이터가 있을 경우 이때 나머지를 모두 전송시킨다. - ACK를 받은 클라이언트는 FIN_WAIT2로 변환되고, 이때 서버는 CLOSE() 함수를 호출하고 FIN 플래그를 클라이언트에게 보낸다.
- 서버도 연결을 닫았다는 신호를 클라이언트가 수신하면 ACK 플래그를 보낸 후 TIME_WAIT 상태로 전환된다.
이 후 모든것이 끝나면 CLOSED 상태로 변환된다.
TCP 통신 과정 시각적으로 확인하기
리눅스 tcpdump 명령어
tcpdump는 Linux 환경에서 Client와 Server가 주고받는 네트워크 패킷을 TCP Layer에서 캡쳐하여 메세지를 확인할 수 있는 명령어이다. UDP도 확인 가능하다.
먼저 tcpdump 명령어를 리눅스에 설치해준다.
# 우분투 설치 $ apt install tcpdump # CentOS 설치 $ yum install tcpdump
그리고 다음 명령어를 실행한다.
# 인터넷 통신을 하는 모든 프로토콜을 감지 $ tcpdump -i any -nn port 80

명령어를 실행하면 위와 같이 인터넷 통신을 감지하는 상태가 된다.
이번에는 새로운 터미널을 하나 더 만들고, 다음과 같이 리눅스의 netcat(nc) 명령어로 데이터 통신을 한다.
# "Hello World" 라는 데이터를 TCP로 naver.com 에 80번 포트로 전송 $ echo "Hello World" | nc naver.com 80
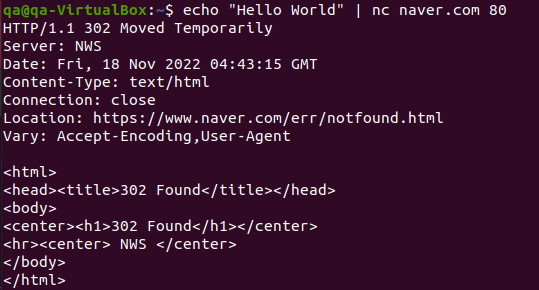
새로운 터미널에서 데이터를 보내게되면, 기존 tcpdump 명령어를 실행하여 Listen 상태였던 터미널에서 통신을 받아 로그를 띄우게 된다.
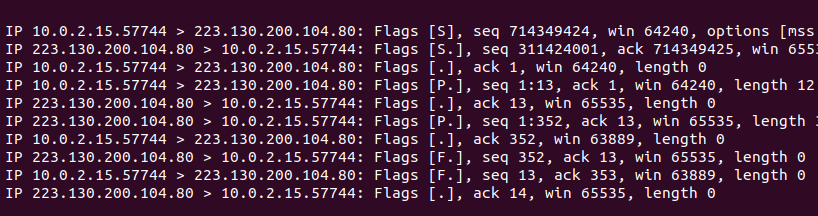
먼저 10.0.2.15:57744은 클라이언트 IP이고, 223.130.200.104:80는 서버 IP이다.
각 라인의 첫번째 필드는 보낸 놈 > 받은 놈을 의미하고 있다. 그리고 옆에 Flags [S] 라는 것이 붙어있는데, 대괄호 안의 대문자는 위에서 살펴본 플래그를 의미한다.
| Flag | 이름 |
| S | SYN |
| S. | SYN-ACK |
| . | ACK |
| P | PSH |
| F | FIN |
지금 위의 상태는 하나의 TCP 연결 및 데이터 전송과 종료 전체 통신 과정을 실행한 상태이다.
이제 각각 명령어 로그 어느 부분이 어느 핸드쉐이크인지 살펴보자.
3-way handshake 과정
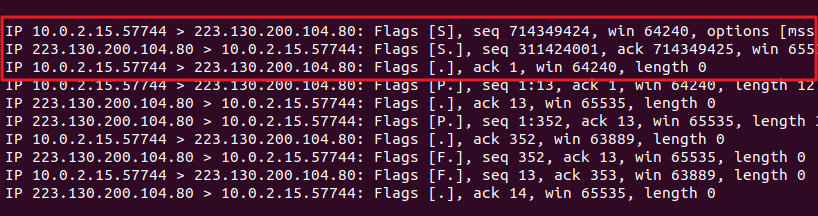
- 클라이언트(10.0.2.15) → 서버(223.130.200.104) : SYN
- 서버(223.130.200.104) → 클라이언트(10.0.2.15) : SYN ACK
- 클라이언트(10.0.2.15) → 서버(223.130.200.104) : ACK
※ 참고
seq 번호는 순서 번호로서 패킷의 전달 순서를 식별하는데 사용되는 값이다.
운영체제의 의해서 랜덤하게 생성되서 SYN 패킷에 담겨 보내진다. 그리고 이를 받은 서버에는 동기화에 대한 답신으로 seq 번호를 +1 증가시키고 ack에 담아 응답한다.
데이터 통신 과정
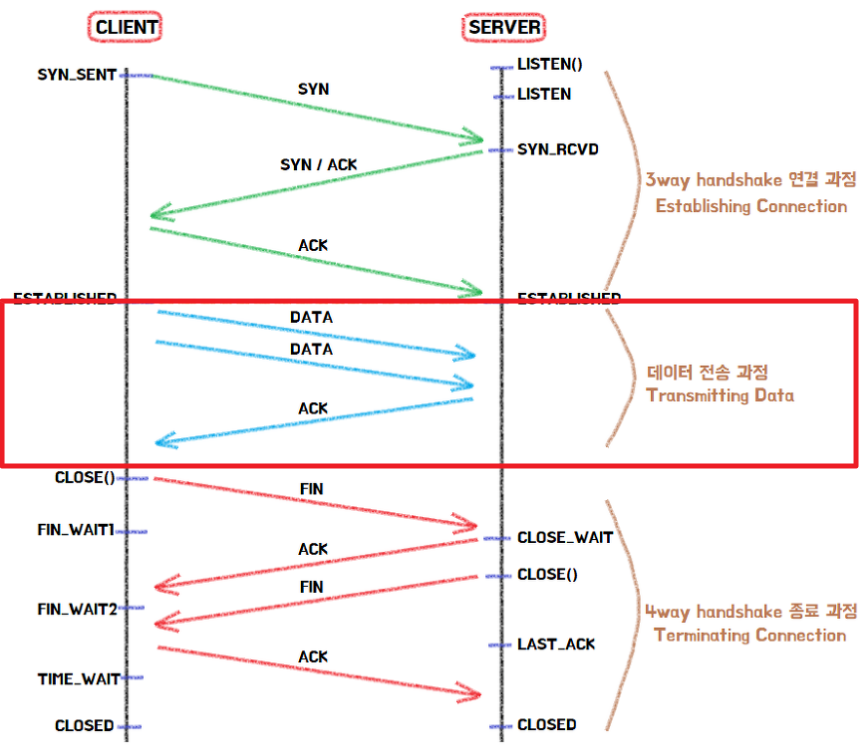
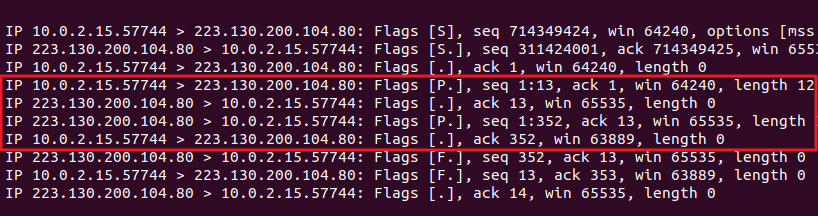
- 클라이언트(10.0.2.15) → 서버(223.130.200.104) : PSH ACK
- 서버(223.130.200.104) → 클라이언트(10.0.2.15) : ACK
4-way handshake 과정
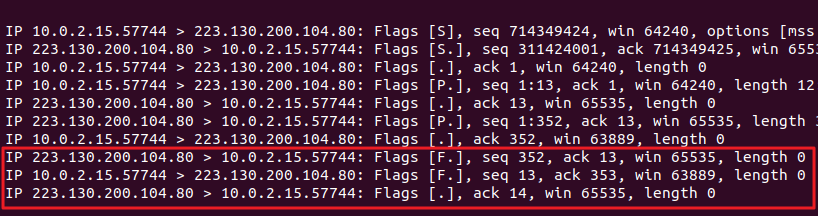
그림상에서는 클라이언트가 먼저 종료 신호를 보냈지만, 리눅스 상에서는 서버가 먼저 종료 신호를 보낸 거꾸로된 상황이다. 그래서 처음에 FIN ACK가 같이 응답해왔고, 또한 ACK와 FIN을 보내는 과정이 하나로 합쳐졌다.
- 서버(223.130.200.104) → 클라이언트(10.0.2.15) : FIN ACK
- 클라이언트(10.0.2.15) → 서버(223.130.200.104) : FIN ACK
- 서버(223.130.200.104) → 클라이언트(10.0.2.15) : ACK
TCP의 전송 제어 기법
TCP(Transmission Control Protocol)는 단어 그대로 원활한 통신을 위해 전송 흐름을 제어하는 기능을 프로토콜 자체에 포함하고 있다. 만약 TCP가 없었더라면 개발자가 일일히 데이터를 어떤 단위로 보낼 것인지 정의해야하고, 패킷이 유실되면 어떤 예외처리를 해야하는 지까지 신경써야하기 때문에, 덕분에 우리는 온전히 상위의 동작에만 집중할 수 있는 것이다.
보통 TCP의 전송 제어 방법은 다음 3가지로 정리 된다.
※ 참고
이 TCP 제어 알고리즘은 양도 많고 난이도도 높기 때문에 따로 시간이 있을때 파보길 권하며, 개념을 잡는 지금은 TCP는 이러한 예외적인 상황에 대해서 잘 알아서 대처한다 정도로 알고 넘어가도록 하자.
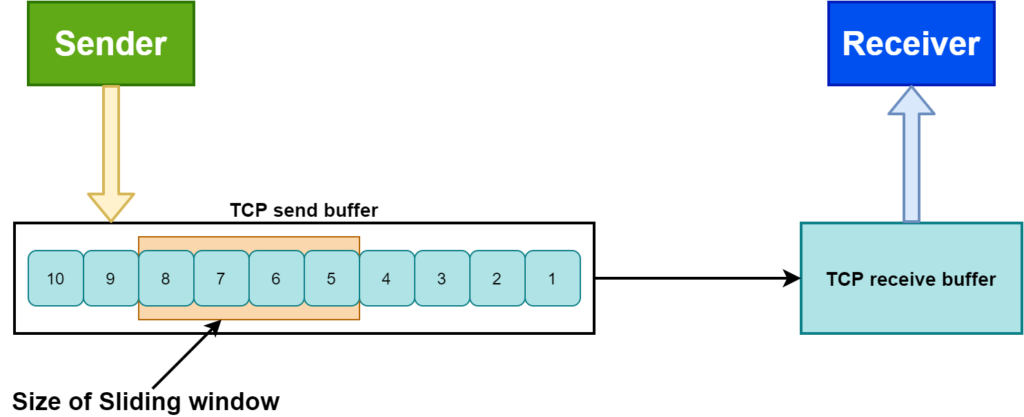
흐름 제어(Flow Control)
- 수신자가 처리할 수 있는 데이터 속도가 다르기 때문에, 송신 측은 수신 측의 데이터 처리 속도를 파악하고 얼마나 빠르게 어느 정도의 데이터를 전송할 지 제어
- 슬라이딩 윈도우(Sliding Window) 방식을 사용
- Window 라는 데이터를 담는 공간을 동적으로 조절하여 데이터량을 조절
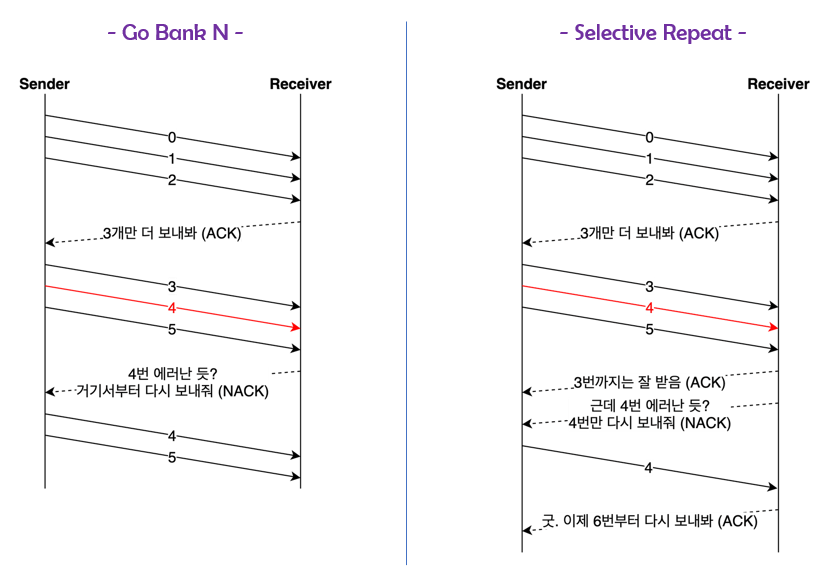
오류 제어(Error Control)
- 통신 도중에 데이터가 유실되거나 잘못된 데이터가 수신되었을 경우 대처
- Go Bank N 기법과 Selective Repeat(선택적인 재전송) 기법을 사용
- Go Bank N 기법 : 어느 데이터로부터 오류가 발생했는지 파악하여, 그 부분만 다시 순서대로 보내 제어한다.
- Selective Repeat 기법 : 에러난 데이터만 재전송하고 그전에 받았던 순서가 잘못된 데이터 버퍼를 재정렬하여 제어한다.
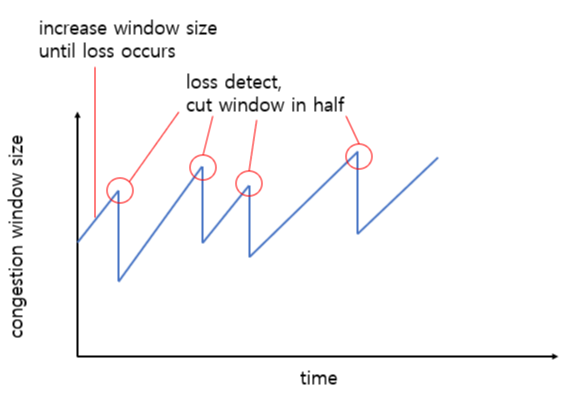
혼잡 제어(Congestion Control)
- 네트워크가 불안정하여 데이터가 원활히 통신이 안되면 제어를 통해 재전송을 하게 되는데, 재전송 작업이 반복되면 네트워크가 붕괴될 수도 있다. 따라서 네트워크 혼잡 상태가 감지되면 송식 측의 전송 데이터 크기를 조절하여 전송량을 조절한다.
- TCP에는 Tahoe, Reno, New Reno, Cubic, Elastic-TCP ..등 다양한 혼잡 제어 기법이 존재한다.
UDP - 사용자 데이터그램 프로토콜
보통 UDP 와 TCP를 비교하는데 있어 아래와 같은 표를 많이 봐왔을 것이다.
표를 보면 대략 TCP는 신뢰성이 높고 느리다 와 UDP는 신뢰성이 낮고 빠르다 정도로 정리가 된다.
| TCP | UDP | |
| 연결 방식 | 연결형 서비스 | 비연결형 서비스 |
| 패킷 교환 | 가상 회선 방식 | 데이터그램 방식 |
| 전송 순서 보장 | 보장함 | 보장하지 않음 |
| 신뢰성 | 높음 | 낮음 |
| 전송 속도 | 느림 | 빠름 |
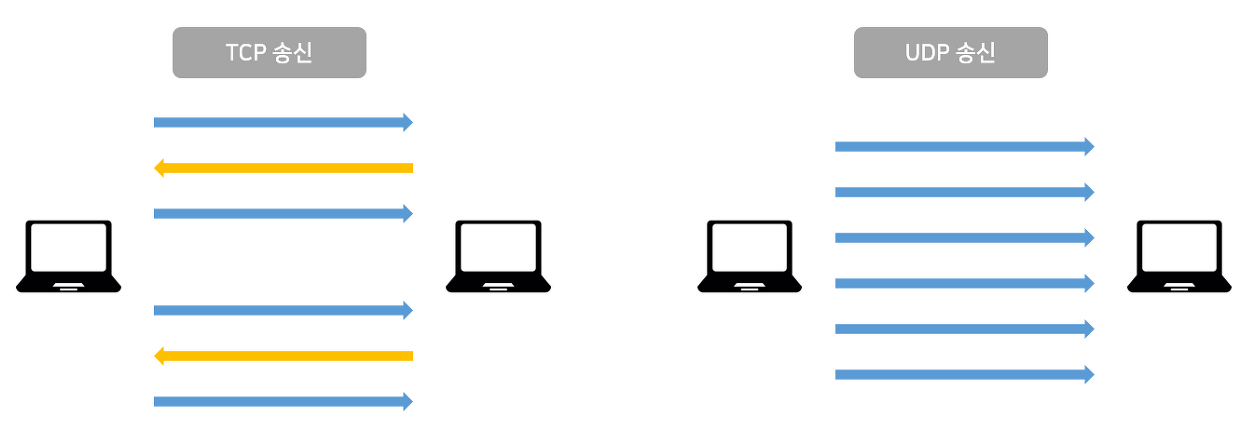
아무래도 클라이언트와 서버가 서로 신뢰성있는 통신을 할 수 있도록 TCP는 핸드쉐이크 과정을 거치게 되는데, 위에서 살펴본것 처럼 데이터 하나를 전송하기 위한 밑작업들이 많았었다.
그렇지만 인터넷 기술이 발전하면서 전송해야하는 데이터도 단순 텍스트를 넘어서 동영상이나 음악과 같은 멀티미디어도 전송하면서 데이터의 크기가 점점 커져가며 동시에 빠른 통신이 필요해 졌다. 그래서 HTTP 2.0에서는 한번 연결된 TCP 회선을 길게 유지하고 데이터도 스트림이라는 특수한 형태로 보내는 식으로 극복을 했지만, TCP 자체가 가지는 근본적인 특징 때문에 결과적으로 속도 한계가 있었다. (즉, 너무 무거워서 더이상 속도를 뽑아 낼수가 없음)
반면, UDP(User Datagram Protocol)는 단어에서도 알 수 있듯이 데이터그램 방식을 사용하는 프로토콜이기 때문에 애초에 각각의 패킷 간의 순서가 존재하지 않는 독립적인 패킷을 사용한다.
데이터그램 방식은 패킷의 목적지만 정해져있다면 중간 경로는 어딜 타든 신경쓰지 않기 때문에 핸드쉐이크 과정 같은 연결 설정이 필요 없게 된다. 즉, UDP는 신뢰성을 확보하기 위해 거치던 TCP의 과정을 거치지 않기 때문에 속도가 더 빠를 수 밖에 없다는 것이다. 그래서 UDP는 실시간 영상 스트리밍과 같은 고용량 데이터를 다루는 곳에 이용된다.

UDP 통신 과정 시각적으로 확인하기
UDP가 왜 TCP 보다 빠른지는 리눅스 명령어를 통해서도 한눈에 이해할 수 있다.
기존 netcat 명령어에 -u 옵션을 주게 되면 UDP로 데이터를 송신 하게 되는데, 수신측 로그를 보면 진짜 딸랑 한줄이 끝이다. 잘받았다는 응답 패킷 없이 무지성으로 보내기만 하는 것이다.
# "Hello World" 라는 데이터를 -u 옵션(UDP로) naver.com 에 80번 포트로 전송 $ echo "Hello World" | nc -u naver.com 80

TCP 헤더와 UDP 헤더 크기 차이
TCP가 신뢰성있는 연결과 혼잡 제어 등을 위해 얼마나 많은 기능을 가지고 있는 지는 TCP와 UDP의 헤더를 비교 해보면 파악할 수 있다.
TCP 헤더 구성
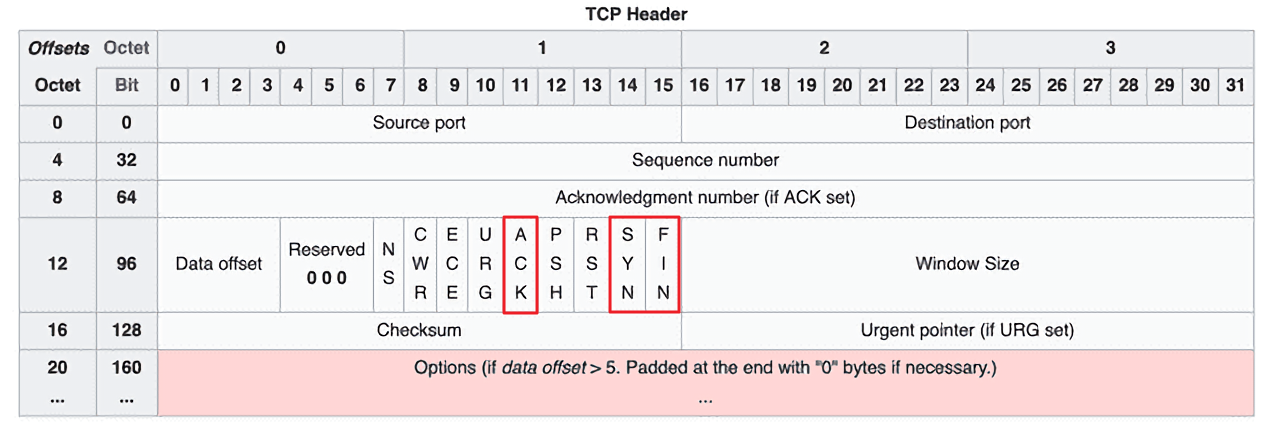
TCP의 경우 워낙 오래 전에 설계되기도 했고, 이런 저런 기능이 워낙 많이 포함된 프로토콜이다보니 이미 헤더에 많은 것들이 포함되어 있다.
- Source Port : 데이터를 생성한 애플리케이션에서 사용하는 포트번호
- Destination Port : 목적지 애플리케이션이 사용하는 포트 번호
- Sequence Number 필드 : 세그먼트 순서를 맞추기 위한 필드
- Acknowledgement Number 필드 : 다음 세그먼트 수신 준비 및 모든 데이터 수신 확인 역할
- Data Offset 필드 : TCP 헤더의 크기 ( 5~15 : 5*32<160bit> ~ 15*32<480bit> )
- Reserved 필드 : 차후의 사용을 위한 예약된 필드
- Control Flags (SYN, ACK, FIN ...등) : 긴급, 혼잡, 확인, 수신 거부 등의 기능
- Window size 필드 : 수신자가 한번에 받을 수 있는 데이터의 양. 송신자는 Window size만큼 ACK를 기다리지 않고 데이터를 전송. ACK가 계속 왔다갔다 하지 않아도 된다
- Checksum : 세그먼트 내용의 유효성과 손상 여부 검사
UDP 헤더 구성

반면 UDP는 데이터 전송 자체에만 초점을 맞추고 설계되었기 때문에 헤더에 들어있는게 없다.
UDP의 헤더에는 출발지와 도착지, 패킷의 길이, 체크섬 밖에 없다.
- Source Port : 데이터를 생성한 애플리케이션에서 사용하는 포트번호
- Destination Port : 목적지 애플리케이션이 사용하는 포트 번호
- checksum : 중복 검사의 한 형태로, 오류 정정을 통해 공간(전자 통신)이나 시간(기억 장치) 속에서 송신된 자료의 무결성을 보호하는 단순한 방법. (TCP의 체크섬과는 다르게 UDP의 체크섬은 사용해도 되고 안해도 되는 옵션)
TCP vs UDP 비교표
| TCP | UDP |
| 연결지향형 프로토콜 | 비 연결지향형 프로토콜 |
| 바이트 스트림을 통한 연결 | 메세지 스트림을 통한 연결 |
| 오류제어, 흐름제어, 혼잡제어 | 혼잡제어와 흐름제어 지원 X |
| 순서 보장, 상대적으로 느림 | 순서 보장되지 않음, 상대적으로 빠름 |
| 신뢰성 있는 데이터 전송 - 안정적 | 데이터 전송 보장 X |
| 세그먼트 TCP 패킷 | 데이터그램 UDP 패킷 |
| HTTP, Email, File transfer 에서 사용 | 도메인, 실시간 동영상 서비스에서 사용 |
아래 내용부터는 참고 사항이다. 추가적인 학습을 위해 우선 작성해 둔 것이다.
TCP를 버리고 UDP를 선택한 HTTP 3.0
2022년 11월 15일 한국 최초로 네이버도 HTTP/3을 도입하였다고 한다.
TCP는 구조상 한계로 개선해도 여전히 느리다
사실 TCP는 지금과 같이 엄청난 속도로 발전할 것이라곤 상상 할 수 없는 시기에 만들어졌다. TCP가 만들어지던 시절에 클라이언트와 서버가 동시 다발적으로 여러 개 파일의 데이터 패킷을 교환할 것이라고 상상하지 못했기 때문이다.
그래서 모바일 기기와 같이 네트워크 환경을 바꾸어가면서 서버와 클라이언트가 소통할 수 있을 것이라고 생각하지 못했다. 그 때문에 와이파이를 바꾸면 다시 새로운 커넥션을 맺어야 되서 끊김 현상이 일어나는 것이다.
또한 TCP를 사용한 통신에선 패킷은 신뢰성을 위해 무조건 순서대로 처리되어야 한다. 또한 패킷이 처리되는 순서 또한 정해져있으므로 이전에 받은 패킷을 파싱하기 전까지는 다음 패킷을 처리할 수도 없다. 만일 중간에 패킷이 손실되어 수신 측이 패킷을 제대로 받지 못했으면 다시 보내야 한다.
이렇게 패킷이 중간에 유실되거나 수신 측의 패킷 파싱 속도가 느리다면 통신에 병목이 발생하게 되는데, 이러한 현상을HOLB(Head of line Blocking)라고 부른다.
이 HOLB는 TCP 설계도상 어쩔수 없이 발생하는 문제이기 때문에 HTTP/1.1 뿐만 아니라 HTTP/2도 가지고 있는 아주 고질적인 문제였다.
따라서 이런 고질적인 문제들을 해결하기 위해 HTTP/3는 TCP를 버리고 UDP를 선택하였다.
UDP는 신뢰성이 없는게 아니라 탑재를 안했을 뿐이다
앞서 신뢰성 대신 속도를 택한 UDP는 스트리밍과 같은 서비스에서 사용된다고 소개한 바가 있다. 방송이나 동영상은 중간에 끊길지언정 바로바로 데이터를 빠르게 송출하는것이 더 중요하기 때문이다.
하지만 기본적으로 인터넷은 클라이언트와 서버 간의 정확한 패킷 통신이 필요하기 때문에 신뢰성이 보장받아야 한다. 왜 HTTP가 TCP를 기반으로 했는지 그 이유이다.
많이들 착각하는 것이 빠른건 알겠는데 UDP는 신뢰성이 없기 때문에 사용성이 적다고 이해하는 것이다. 하지만 이는 명확하지 않다.
UDP는 신뢰성이 없는게 아니라 탑재를 안했을 뿐이다. UDP의 진짜 장점은 커스터마이징이 가능하다는 점이다.
즉, UDP 자체는 헤더에 들은게 없어 신뢰성이 낮고 제어 기능도 없지만, 이후 개발자가 애플리케이션에서 구현을 어떻게 하냐에 따라서 TCP와 비슷한 수준의 기능을 가질 수도 있다는 말이다.
UDP를 개조한 QUIC 프로토콜
QUIC(Quick UDP Internet Connections)는 UDP를 기반으로 TCP + TLS + HTTP 의 기능을 모두 구현하는 프로토콜이다. 따라서 HTTP 3.0이 UDP를 이용하였다라는 말은 정확히 말하면 UDP 기반으로 만들어진 QUIC 프로토콜을 채택하였다라는 뜻이다.
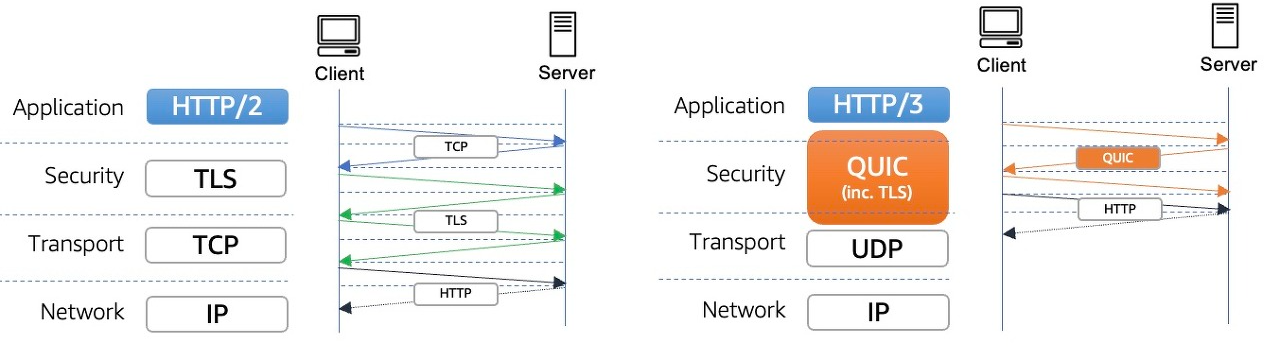
QUIC은 TCP를 사용하지 않기 때문에 통신을 시작할 때 번거로운 3 Way Handshake 과정을 거치지 않아도 된다.
클라이언트가 보낸 요청을 서버가 처리한 후 다시 클라이언트로 응답해주는 사이클을 RTT(Round Trip Time)이라고 하는데, TCP는 연결을 생성하기 위해 기본적으로 1 RTT가 필요하고, 여기에 TLS를 사용한 암호화까지 하려고 한다면 TLS의 자체 핸드쉐이크까지 더해져 총 3 RTT가 필요하다.
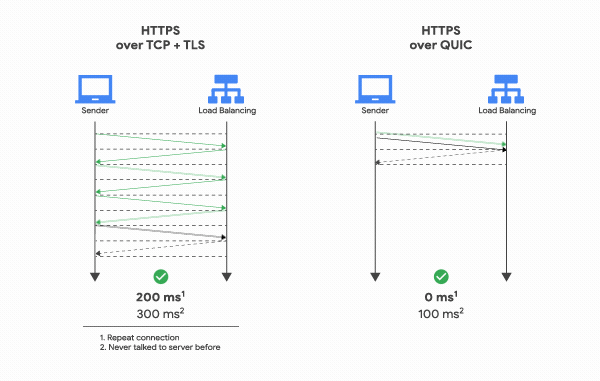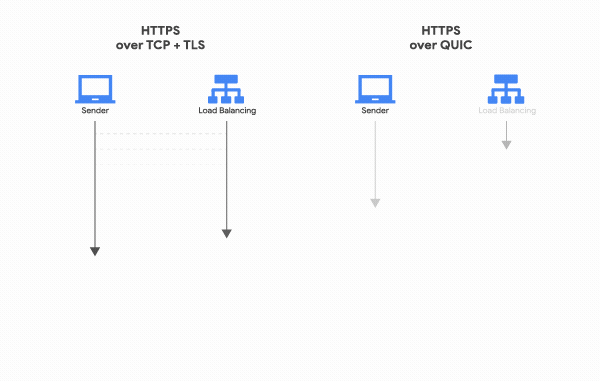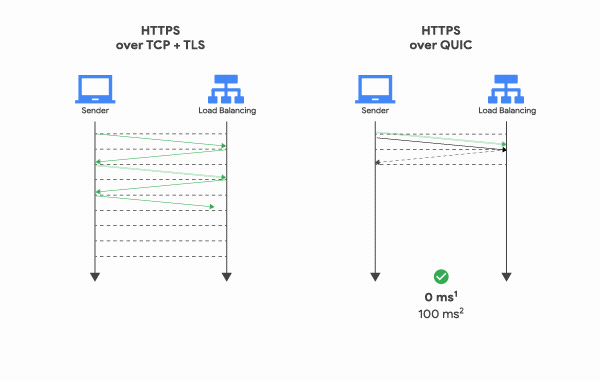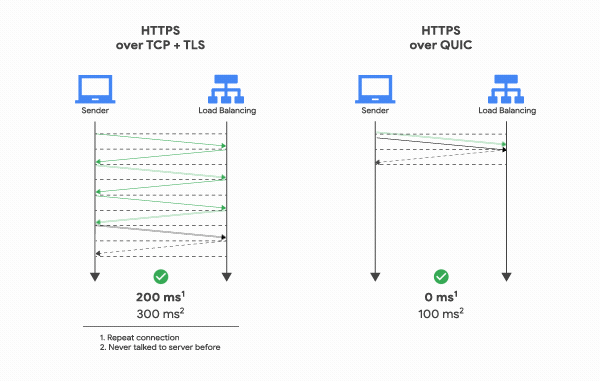
반면 QUIC은 첫 연결 설정에 1 RTT만 소요된다.
TCP 핸드쉐이크 과정을 거치지 않으며 TLS 자체를 내포하고 있기 때문에, 연결 설정에 필요한 정보와 함께 데이터도 보내버리기 때문이다. 그리고 한번 연결에 성공했다면 서버는 그 설정을 캐싱해놓고 있다가, 다음 연결 때는 캐싱해놓은 설정을 사용하여 바로 연결을 성립시키기 때문에 0 RTT만으로 바로 통신을 시작할 수도 있다.
이밖에도 패킷 손실 감지에 걸리는 시간 단축되었으며, 클라이언트의 IP가 바뀌어도 연결이 유지되어 모바일에서 와이파이를 바꾸어도 끊김이 없어지게 되었다.
참고
- TCP/ IP 전송 계층 (Transport Layer)
- HTTP / IP / TCP / UDP 는 모두 프로토콜
- TCP - 전송 제어 프로토콜
- TCP의 안전 포장
- TCP의 통신 확인 방법
- 세그먼트 (Segment) - TCP 프로토콜의 PDU
- 주요 flag 종류
- 3-way handshake 과정
- 데이터 통신 과정
- 4-way handshake 과정
- TCP 통신 과정 시각적으로 확인하기
- TCP의 전송 제어 기법
- UDP - 사용자 데이터그램 프로토콜
- UDP 통신 과정 시각적으로 확인하기
- TCP 헤더와 UDP 헤더 크기 차이
- TCP vs UDP 비교표
- TCP를 버리고 UDP를 선택한 HTTP 3.0
- TCP는 구조상 한계로 개선해도 여전히 느리다
- UDP는 신뢰성이 없는게 아니라 탑재를 안했을 뿐이다
- UDP를 개조한 QUIC 프로토콜