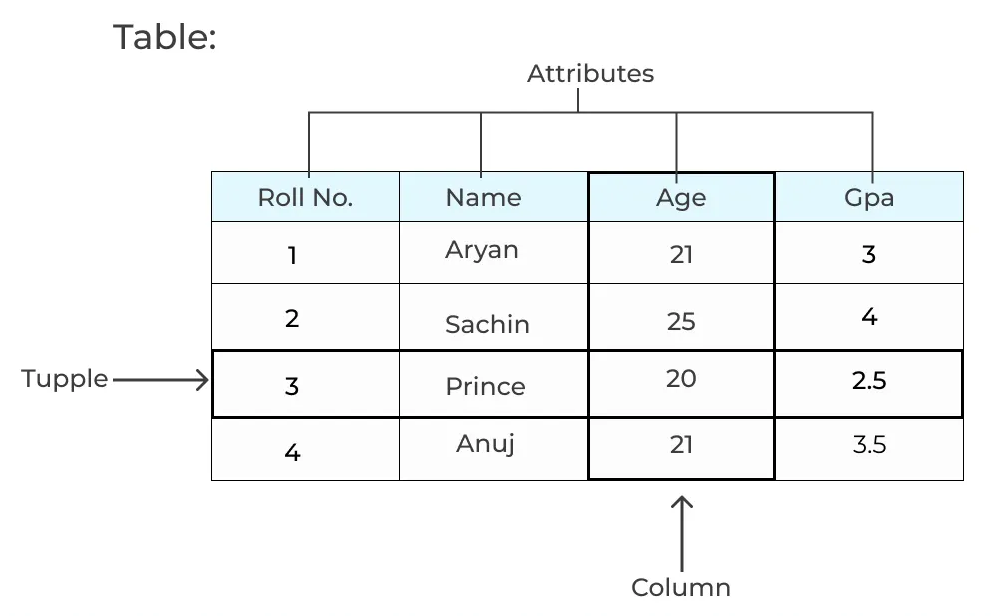
데이터베이스(Database) 란?
데이터베이스는 우리의 일상생활에서 자주 접하는 용어 중 하나 일 것이다. 예를 들어, 인터넷 쇼핑몰에서 상품을 주문하거나, 학교에서 성적을 조회하거나, 은행에서 계좌를 관리할 때 등 다양한 상황에서 데이터베이스가 쓰인다. 데이터베이스는 어렵게 생각할 필요없이 데이터들을 저장하고 조회하는 프로그램이다. 쇼핑몰의 경우 상품 정보, 고객 정보, 주문 정보 데이터를 데이터베이스에서 가져와 조회하거나 정보를 저장하는 것이다.
데이터베이스의 필요성
데이터를 저장하고 조회한다는 관점에서 보면 파일들을 폴더에 저장하여 정리하고 파일을 검색해서 조회하는 윈도우 파일 탐색기와 비슷해 보일수 있다.

하지만 데이터베이스는 이러한 단순한 데이터 저장소 개념을 넘어선 상위 호환 격이다. 데이터베이스는 프로그래밍과 같은 컴퓨터 언어(SQL)로 세밀히 제어가 가능하고, 어떻게 제어하느냐에 따라 성능이 천차 만별이다. 또한 데이터들끼리 중복된 정보가 있을 경우 이를 통합하여 구조적이며 효율적으로 데이터를 저장한다. 거기다 데이터베이스는 컴퓨터 언어로 제어가 가능하고 앱이나 웹을 통해 전세계로 공유가 가능하다.
이처럼 데이터베이스는 파일을 조직적으로 통합하여 자료 항목의 중복을 최대한 없애고 자료를 구조화하여 기억시켜 놓은 자료의 집합체라고 할 수 있다.
데이터베이스의 데이터 특징
데이터베이스는 단순이 아무 데이터나 마구잡이로 저장해 놓지 않고 구조적인 형태를 유지하기 위해 나름 효율적인 데이터 저장 규칙이 존재한다.
통합된 데이터 (Integrated Data)
여러가지의 데이터를 통합하여 저장하는데 중복된 정보가 있어 이를 그대로 저장하면 용량 낭비가 발생하는 비효율적인 현상이 발생한다. 그래서 데이터베이스는 이러한 중복된 정보에 대해서 데이터를 통합하여 자료의 중복을 최소화한 데이터의 모임으로 구성한다.
저장된 데이터 (Stored Data)
우리가 사진이나 동영상 파일을 하드디스크나 SSD에 저장하는 것처럼, 데이터베이스도 컴퓨터가 접근할 수 있는 매체에 데이터를 저장한다.

운영 데이터 (Operational Data)
데이터베이스는 주로 조직의 목적을 위해 존재하고 활용되는 운영 데이터를 다루는데 주요 이용된다. 예를 들어, 쇼핑몰의 경우 판매량이나 재고량 등이 운영 데이터이다. 단순하거나 임시적으로 데이터 저장이 필요하다면 굳이 무거운 데이터베이스 소프트웨어를 사용할 필요가 없고 그냥 폴더에 저장해 버리면 된다.
공유 데이터 (Shared Data)
여러 사람들이 공유하고 사용할 목적으로 통합 관리되는 데이터를 말한다. 아마 데이터베이스라는 소프트웨어를 사용하는 가장 근본적인 이유이기도 하다. 하나의 컴퓨터나 시스템을 위한 데이터가 아니라 여러 시스템들이 공용으로 엑세스하여 이용한다. 예를 들어, 쇼핑몰의 경우 판매자와 구매자가 같은 상품 정보를 보는걸 들 수 있다.
데이터베이스의 기능 특징
데이터베이스는 이러한 특수한 특징을 가진 데이터들을 효율적으로 관리하기 위해 다음과 같은 기능을 제공한다.
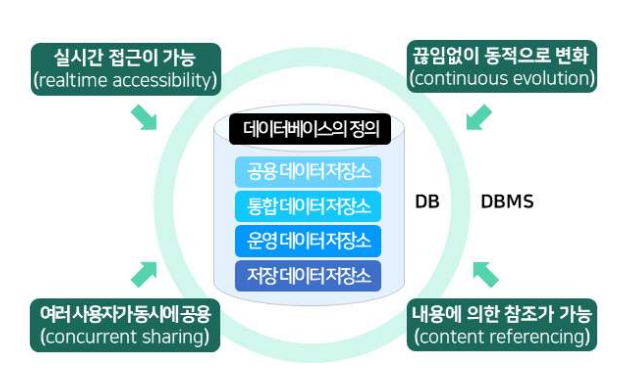
실시간 접근성 (Real-Time Accessibility)
데이터베이스는 사용자의 요구에 신속하고 정확하게 응답이 가능해야 한다. 예를 들어, 쇼핑몰 온라인의 경우 고객이 원하는 상품을 검색하거나 주문하는 것을 말한다.
지속적인 변화 (Continuous Evolution)
현실 세계의 변화를 반영하기 위해 새로운 데이터의 삽입(Insert), 삭제(Delete), 갱신(Update)으로 항상 최신의 데이터를 유지하는 것을 말한다. 예를 들어, 쇼핑몰의 경우 상품 정보나 가격 정보를 상황에 따라 계속 변경할 수 있다.
동시 공용 (Concurrent Sharing)
다수의 사용자가 동시에 같은 내용의 데이터를 이용할 수 있어야 한다. 예를 들어, 쇼핑몰의 경우 여러 고객이 동시에 같은 상품을 조회하거나 구매할 수 있다.
내용에 의한 참조 (Content Reference)
데이터베이스에 있는 데이터를 참조할 때 사용자의 요구에 따른 데이터 내용으로 데이터의 위치나 주소로 데이터를 찾는다. C언어의 포인터나, URL 주소를 떠올리면 된다.
데이터베이스의 언어 종류
본문 상단에서 데이터베이스는 컴퓨터 언어로 통신한다고 말했다. 마치 프로그래밍과 비슷하다고 볼 수 있는데, 이러한 데이터베이스와 소통하기 위해 사용하는 언어를 데이터베이스 언어(Database Language)라고 한다. 그리고 데이터베이스 언어 중에서 가장 많이 사용되는 것이 한번 쯤 들어본 SQL(Structured Query Language)이다. SQL은 관계형 데이터베이스에서 데이터를 정의하고 조작하고 제어할 수 있는 표준 언어로서, 대부분의 데이터베이스 시스템에서 지원한다. 그리고 데이터를 조회, 삭제, 생성하느냐에 따라 데이터베이스 언어는 크게 다음과 같이 4 가지로 나뉘게 된다.
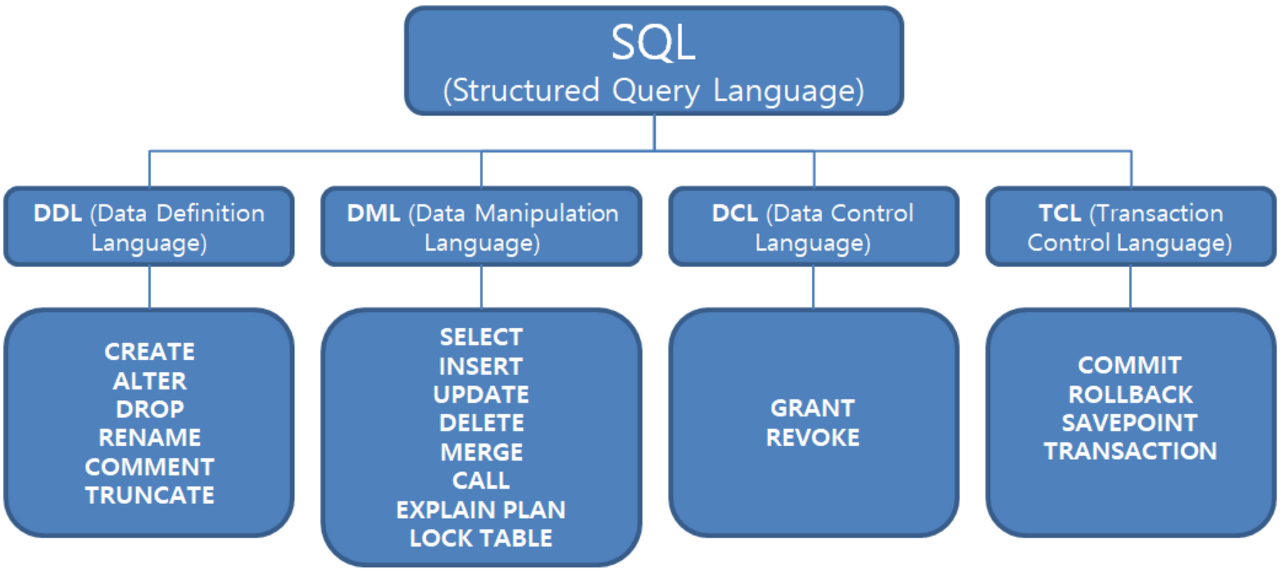
| 명령어 종류 | 명령어 | 설명 |
| 데이터 조작어 (DML : Data Manipulation Language) |
SELECT | 데이터베이스에 들어 있는 데이터를 조회하거나 검색하기 위한 명령어를 말하는 것으로 RETRIEVE 라고도 함 |
| INSERT UPDATE DELETE |
데이터베이스의 테이블에 들어 있는 데이터에 변형을 가하는 종류(데이터 삽입, 수정, 삭제)의 명령어들을 말함. | |
| 데이터 정의어 (DDL : Data Definition Language) |
CREATE ALTER DROP RENAME TRUNCATE |
테이블과 같은 데이터 구조를 정의하는데 사용되는 명령어들로 (생성, 변경, 삭제, 이름변경) 데이터 구조와 관련된 명령어들을 말함. |
| 데이터 제어어 (DCL : Data Control Language) |
GRANT REVOKE |
데이터베이스에 접근하고 객체들을 사용하도록 권한을 주고 회수하는 명령어들을 말함. |
| 트랜잭션 제어어 (TCL : Transaction Control Language) |
COMMIT ROLLBACK SAVEPOINT |
논리적인 작업의 단위를 묶어서 DML에 의해 조작된 결과를 작업단위(트랜잭션) 별로 제어하는 명령어를 말함. |
현재 단계에선 위의 개념을 모두 이해할 필요는 없다. 데이터를 어떠한 방식으로 다룰것이냐에 따라 명령어 집합이 나누는 정도만 알면 되고 추후에 MySQL 쿼리를 배우게 된다면 자연스럽게 습득하게 될 것이다.
DBMS (Database Management System)
DBMS는 단어 그대로의 뜻으로 데이터베이스를 관리하는 소프트웨어이다. 데이터베이스는 특정 조직의 업무를 수행하는 데 필요한 상호 관련된 데이터들의 복잡한 모임인데, DBMS는 이러한 데이터베이스의 데이터들을 효율적으로 저장하고 검색하고 수정하고 삭제하고 보호할 수 있도록 도와준다. DBMS는 다양한 종류와 모델이 있으며, 사용하는 목적과 환경에 따라 적절하게 선택해야 한다.
DBMS의 역사 (발전 과정)
DBMS는 시간이 지남에 따라 다양한 모델과 기능을 발전시켜왔다. 다음은 DBMS의 주요 발전 과정이다.
| 구분 | 모델 | DBMS |
| 1세대 | 파일시스템 | - ISAM - VSAM |
| 2세대 | 계층형 (Hierachical) HDBMS | - IMS - System2000 |
| 3세대 | 네트워크형 (Network) NDBMS | - IDS - TOTAL - IDMS |
| 4세대 | 관계형 (Relational) RDBMS | - Oracle - My-SQL - DB2 - SQL Server - Sybase |
| 5세대 | 객체지향 (Object Oriented) ODBMS | - Object Store - UniSQL |
HDBMS (Hierarchical DBMS)
1960년대에 개발된 최초의 DBMS로서, 데이터를 트리 구조로 표현하는 방식이다. 예를 들어, 부서와 직원의 관계를 부모 노드와 자식 노드로 나타낼 수 있다. HDBMS는 데이터 접근 속도가 빠르고 단순한 구조를 가지는 장점이 있지만, 데이터의 중복이 많고 구조 변경이 어렵고 관계 표현이 제한적인 단점이 있다.
NDBMS (Network DBMS)
1970년대에 개발된 DBMS로서, 데이터를 그래프 구조로 표현하는 방식이다. 예를 들어, 부서와 직원의 관계를 노드와 링크로 나타낼 수 있다. NDBMS는 HDBMS보다 관계 표현이 유연하고 다대다 관계를 지원하는 장점이 있지만, 구성과 설계가 복잡하고 데이터 종속성을 해결하지 못하는 단점이 있다.
RDBMS (Relational DBMS)
1970년대에 개발된 DBMS로서, 데이터를 테이블 형태로 표현하는 방식이다. 예를 들어, 부서와 직원의 관계를 테이블과 테이블 간의 외래키로 나타낼 수 있다. RDBMS는 데이터의 중복을 최소화하고 구조 변경이 쉽고 SQL 언어를 사용하여 데이터를 쉽게 조작할 수 있는 장점이 있다. 또한 ACID 원칙을 준수하여 데이터의 무결성과 일관성을 보장한다. 그래서 RDBMS는 현재 가장 널리 사용되는 DBMS로서 우리가 익히 잘아는 MySQL, Oracle, SQLite 등이 있다.
ODBMS (Object-Oriented DBMS)
1980년대에 개발된 DBMS로서, 데이터를 객체의 형태로 표현하는 방식이다. 예를 들어, 부서와 직원의 관계를 객체와 객체 간의 연결로 나타낼 수 있다. ODBMS는 객체지향 프로그래밍 언어와 호환성이 높고 복잡한 데이터 타입을 지원하는 장점이 있지만, 성능이 낮고 표준화가 부족하고 SQL과 호환되지 않는 단점이 있어 거의 사장되고 다음 타자인 NOSQL 로 넘어갔다고 보면 된다.

NO SQL (Not Only SQL)
2000년대에 개발된 DBMS로서, 테이블 형태의 관계형 모델이 아닌 여러가지의 모델로 데이터를 표현하는 방식이다. 예를 들어, 문서(Document)나 키-값(Key-Value) 쌍이나 그래프(Graph) 등으로 데이터를 나타낼 수 있다. 그래서 NOSQL은 어느 한가지 형태의 데이터베이스를 지칭하지 않고, RDBMS의 테이블 형태가 아닌 형태를 띈 DB를 총칭한다고 보면 된다.
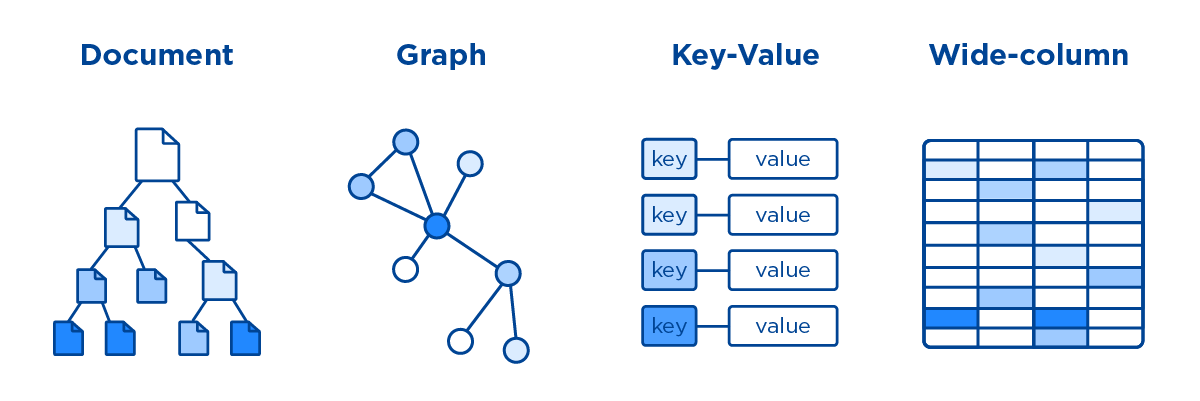
NOSQL은 RDBMS보다 확장성과 가용성이 높고 유연한 스키마를 가지는 장점이 있지만, 데이터의 일관성이 항상 보장되지 않고 기존 SQL과 호환되지 않는 단점이 있다. 그래서 우리가 새로운 프로그래밍 언어를 공부하듯이 NO SQL도 추가적인 학습이 필요하다. 하지만 NOSQL은 대용량 데이터나 분산 처리에 매우 빠르게 대응이 가능하기 때문에 페이스북, 스냅챗과 같은 SNS에서 쓰인다. (페이스북은 자체적으로 개발한 Cassandra DB를 사용한다)
NOSQL의 유명한 종류로는 MongoDB, HBase, Cassandra, Redis 등이 있다.
다만 DBMS의 1~3세대는 4세대 (관계형) DBMS로 빠른 전환이 이루어 졌지만, 관계형 DBMS에서 객체지향 DBMS로는 전환이 되지 않고 있는 실정이다. 왜냐하면 관계형 DBMS와 객체지향 DBMS는 데이터를 다른 방식으로 저장하고 접근하기 때문에 두 모델 간의 호환성이 떨어지고, 성능이 저하되고, 적용 범위가 제한적이기 때문이다. 따라서 아주 속도를 우선적으로 하는 특수한 서비스가 아니라면, 관계형 DBMS (RDBMS)가 계속 현 상태를 유지하는 중이다.
RDBMS(관계형 데이터베이스) 종류
데이터베이스 과목을 배우기 시작해 기본적인 데이터베이스 이론에 대해 습득하고 다음에 실제 소프트웨어를 다루게 되는데 주로 RDBMS를 다루게 된다. 그래서 관계형 DB 종류에 대해 잠깐 알아두면 데이터베이스를 보는 시각이 넓어지게 될 것이니 한번 둘러보는걸 추천하는 바다.
Oracle (오라클)

- 전세계적으로 가장 많이 활용되는 관계형 데이터베이스 시스템 (RDBMS)
- 오라클사에서 서비스하고 있으며 Unix, Linux, Windows 등의 대부분의 OS를 지원
- Oracle Real Application Clusters (RAC)의 기능으로 데이터베이스 관리에 있어서 자원의 확장성과 장애에 대한 대처가 유연해 하다는 장점이 있다.
- IBM의 DB2와 마찬가지로 중견기업, 대기업 등 대형화된 데이터를 관리하기에 최적화되어 있다.
MSSQL / SQL Server (Microsoft)

- 마이크로소프트 (Microsoft)사의 대표적인 관계형 데이터베이스 시스템
- MSSQL 혹은 SQL Server 로 두가지로 불리운다
- 1989년에 최초로 발표되었으며, 역시 MS제품군이기 때문에 window server에서만 구동이 되고 C#과는 가장 높은 호환성을 자랑하는 DBMS 이다.
MySQL (오라클)

- 썬 마이크로시스템즈에서 개발한 관계형 데이터베이스 시스템
- 유닉스나 리눅스, 윈도우 운영 체제 등에서 사용할 수 있으며 무엇보다 오픈소스의 장점으로 많은 기업에서 홈 페이지나 쇼핑몰 등 일반적인 웹 개발에 널리 이용되고 있다.
- 2008년 SUN에 인수되었으며, 2009년 Oracle에서 SUN을 인수함에 따라 자연스럽게 Oracle의 소유가 되었다.
- 그래서인지 메인 제품인 오라클 DB에 비해 사용자 편의를 위한 기능, 사용자 실수 또는 재해에 대비한 기능, 성능향상등 기능적인 한계가 있다
- 그래도 대중화된 오픈소스이기 때문에 현재 많은 기업에서 활용하고 있다.
MariaDB (MariaDB 재단)

- 마리아 DB는 2009년에 발표되었으며 비교적 역사가 짧은 최신 DBMS이다.
- MySQL과 완벽하게 호환되며 기본적인 명령어나 사용방법까지 동일하기 때문에 개발자 또는 DBA 가 쉽게 접할 수 있다
- MySQL에 비해 성능적인 부분에서는 70%나 향상이 되었기 때문에 이를 활용하는 기업들이 많이 늘어나는 추세이다.
※ 참고
[ MariaDB의 탄생 배경 ]
MariaDB는 한마디로 MySQL 업그레이드 버전이라 보면 된다. MariaDB의 탄생배경은 MySQL이 오라클에 인수되면서 시작이 되었는데, 오라클에서 아무래도 무료버전인 MySQL보다 주력 상품인 Oracle을 팔아야 하는 입장에서 오픈소스인 MySQL의 기능을 감소시켜버렸다. 이에 MySQL을 개발한 마이클 몬티 와이드니어스 (Michael Monty Widenius)는 오라클과의 의견 충돌로 회사를 나와 새롭게 MariaDB를 개발했다고 한다.
DB2 (IBM)

- 대형화된 데이터 관리를 목적으로 만들어진 IBM의 관계형 데이터베이스 관리 시스템
- 1983년에 발표되었으며, 사용자들이 서로 관계된 여러 개의 데이터베이스를 동시에 접근할 수 있다.
- DB2의 특징은 각 워크로드(업무)의 특성에 맞게 시스템이 최적화될 수 있으며, 자가 최적화 , 자가 치유, 자가 구성 , 워크로드 관리, 확장된 자동화 기능 등 다양한 기능을 구현할 수 있다.
- 또한 데이터 압축 기술이 좋기 때문에 대형화된 데이터를 다루는데 최적화 될 수 있다는 장점이 있다. 때문에 많은 중견기업 , 대기업 권에서 DB2를 활용하고 있다.
Sybase (Sybase)
- 사이베이스 사에서 개발, 1984년에 공개한 관계형 데이터베이스 시스템
- 현재 (2010년)는 SAP에서 인수되었다.
- 2011년에는 사이베이스 IQ 15.3이 출시 되어 컬럼 단위 데이터 처리로 I/O 속도를 90%까지 향상시켰으며, 데이터 압축 저장, 스토리지 공간의 활용도를 높이게 되었다.
- 오라클에 비해 비교적 저렴하기 때문에 많은 기업에서 관심을 가지고 있는 시스템이지만, 아직까지 국내에서는 오라클에 비해 밀리는 추세이다.
참고