Stream API에 대한 이해
Stream이란?
스트림의 사전적 의미는 '흐르다' 또는 '개울'이다. 프로그래밍에서의 스트림도 사전적 의미와 크게 다르지 않다. 다만, 여기서는 물이 흐르는 것은 아니고 '데이터의 흐름'을 일컫는다.
뭔가 추상적으로는 대충 데이터가 흐르겠구나.. 싶은데 정확히 어떻게 흐르고 결과를 이용하는지 알기가 어렵다. 이해를 돕기 위한 그림을 보자.

위 그림은 어부가 물고기를 그물로 잡고, 여러 마리를 일정한 기준으로 모아서 상자에 넣고, 이들을 하나로 모은 뒤 트럭에 실어서 운반하는 과정을 나타내고 있다.
stream도 이와 별반 다르지 않다. 물고기와 같은 어류의 이동을 stream이라고 정의할 수 있다.
먼저, 어부가 어류 중에서도 고등어를 잡고 싶어서 그물로 고등어를 잡았다. 이 행위를 filter라고 하고, 이 연산자를 중간 연산자라고 한다. 그리고 고등어를 포장하지 않고 생으로 팔 수는 없기 때문에 상자에 담아야 한다. 이 행위를 map이라고 하고, 이 연산자도 마찬가지로 중간 연산자라고 한다.
마지막으로, 고등어가 실린 수많은 상자를 운반하여 다른 곳으로 이동하면서 끝이 난다. 이 행위를 collect라고 하고, 이 연선자는 최종 연산자라고 한다.
즉, 스트림은 수많은 데이터의 흐름 속에서 각각의 원하는 값을 가공하여 최종 소비자에게 제공하는 역할을 한다고 보면된다.
JAVA의 Stream API
Java는 객체지향 언어이기 때문에 기본적으로 함수형 프로그래밍이 불가능하다.
하지만 JDK8부터 Stream API와 람다식, 함수형 인터페이스 등을 지원하면서 Java를 이용해 함수형으로 프로그래밍할 수 있는 API 들을 제공해주고 있다. 그 중에서 Stream API는 데이터를 추상화하고, 처리하는데 자주 사용되는 함수들을 정의해두었다. 여기서 데이터를 추상화하였다는 것은 데이터의 종류에 상관 없이 같은 방식으로 데이터를 처리할 수 있다는 것을 의미하며, 그에 따라 재사용성을 높일 수 있다.
예를 들어 주어진 배열이나 리스트의 데이터를 정렬된 상태로 출력하고자 한다고 하자. Stream API를 사용하지 않은 경우 다음과 같이 코드를 작성할 수 있다.
// Stream 사용 전
String[] nameArr = {"IronMan", "Captain", "Hulk", "Thor"}
List<String> nameList = Arrays.asList(nameArr);
// 원본의 데이터가 직접 정렬됨
Arrays.sort(nameArr);
Collections.sort(nameList);
for (String str: nameArr) {
System.out.println(str);
}
for (String str : nameList) {
System.out.println(str);
}위의 코드들도 충분히 괜찮은 코드들이다. 하지만 이를 더욱 간결하고 가독성있게 정리할 수 있으며, 원본의 데이터에 변형을 가하지 않는 방법이 있다면 그것은 분명 더욱 좋은 코드일 것이다.
Java의 Stream API는 원본의 데이터에 변경 없이 위의 코드를 더욱 간략하게 작성하는 방법을 제공하고 있다. 위의 내용을 함수형으로 리팩토링하면 다음과 같이 작성할 수 있다.
// Stream 사용 후
String[] nameArr = {"IronMan", "Captain", "Hulk", "Thor"}
List<String> nameList = Arrays.asList(nameArr);
// 원본의 데이터가 아닌 별도의 Stream을 생성함
Stream<String> nameStream = nameList.stream();
Stream<String> arrayStream = Arrays.stream(nameArr);
// 복사된 데이터를 정렬하여 출력함
nameStream.sorted().forEach(System.out::println);
arrayStream.sorted().forEach(System.out::println);이처럼 Stream API를 활용하면 코드의 라인수도 줄이고, 가독성도 높일 수 있다. 이러한 많은 장점을 지닌 Stream API에 대해 자세히 살펴보도록 하자.
Stream API의 특징
- 람다식으로 요소 처리 코드를 제공한다.
- 원본의 데이터를 변경하지 않는다.
- 일회용이다.
- 내부 반복자를 사용하여 작업을 처리한다.
- 지연된 연산
- 병렬 스트림을 제공해준다.
1. 람다식으로 요소 처리 코드를 제공한다.
위의 코드에서 볼 수 있듯이, 스트림은 람다식 또는 메소드 참조를 이용합니다. 따라서, 코드가 간결해지는 장점이 있습니다.
nameStream.sorted().forEach(System.out::println);
arrayStream.sorted().forEach(System.out::println);
2. 원본의 데이터를 변경하지 않는다.
Stream API는 원본의 데이터를 조회하여 원본의 데이터가 아닌 별도의 요소들로 Stream을 생성한다. 그렇기 때문에 원본의 데이터로부터 읽기만 할 뿐이며, 정렬이나 필터링 등의 작업은 별도의 Stream 요소들에서 처리가 된다.
List<String> sortedList = nameStream.sorted()
.collect(Collections.toList());
3. Stream은 일회용이다.
Stream API는 일회용이기 때문에 한번 사용이 끝나면 재사용이 불가능하다. Stream이 또 필요한 경우에는 Stream을 다시 생성해주어야 한다. 만약 닫힌 Stream을 다시 사용한다면 IllegalStateException이 발생하게 된다.
userStream.sorted().forEach(System.out::print);
// 스트림이 이미 사용되어 닫혔으므로 에러 발생
int count = userStream.count();
// IllegalStateException 발생
java.lang.IllegalStateException: stream has already been operated upon or closed
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:229)
at java.util.stream.ReferencePipeline.noneMatch(ReferencePipeline.java:459)
4. 내부 반복자를 사용하여 작업을 처리한다.
외부 반복자란 개발자가 코드로 직접 컬렉션의 요소를 반복해서 가져오는 코드 패턴을 말한다. 우리가 흔히 사용하는 index를 이용한 반복문이나 Iterator를 사용한 while문은 모두 외부 반복자를 이용하는 것이다. 반면, 내부 반복자는 컬렉션 내부에서 요소들을 반복시키고, 개발자는 요소당 처리해야 할 코드만 제공하는 코드 패턴을 말한다.
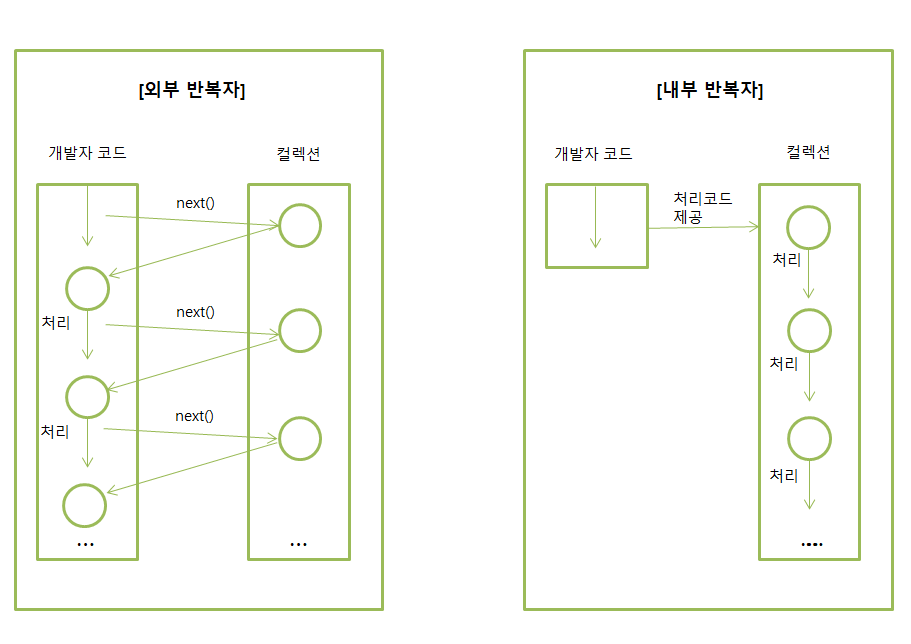
위의 그림은 외부 반복자와 내부 반복자를 나타낸 것이다. 내부 반복자는 요소들의 변경 순서를 변경하거나, 멀티 코어 CPU를 최대한 활용하기 위해서 요소들을 분배시켜 병렬 작업을 할 수 있도록 도와준다.
즉, Stream을 이용하면 코드가 간결해지는 이유 중 하나는 '내부 반복' 때문이고 기존에는 반복문을 사용하기 위해서 for이나 while 등과 같은 문법을 사용해야 했지만, stream에서는 그러한 반복 문법을 메소드 내부에 숨기고 있기 때문에, 보다 간결한 코드의 작성이 가능하다.
// 반복문이 forEach라는 함수 내부에 숨겨져 있다.
nameStream.forEach(System.out::println);5. 지연된 연산
스트림 연산에서 한 가지 중요한 점은 최종 연산이 수행되기 전까지는 중간 연산이 수행되지 않는다는 것이다. 중간 연산을 호출하는 것은 단지 어떤 작업이 수행되어야하는지를 지정해주는 것일 뿐이다. 최종 연산이 수행되어야 비로소 스트림의 요소들이 중간 연산을 거쳐 최종 연산에서 소모된다.
6. 병렬 스트림을 제공해준다.
스트림으로 데이터를 다룰 때의 장점 중 하나가 병렬 처리가 쉽다는 것이다. 병렬 스트림은 내부적으로 fork&join을 이용해서 자동적으로 연산을 병렬로 수행한다. 모든 스트림은 기본적으로 병렬 스트림이 아니므로 병렬 스트림을 사용하려면 parallelStream() 메서드를 사용해 병렬 스트림으로 전환해야 한다.
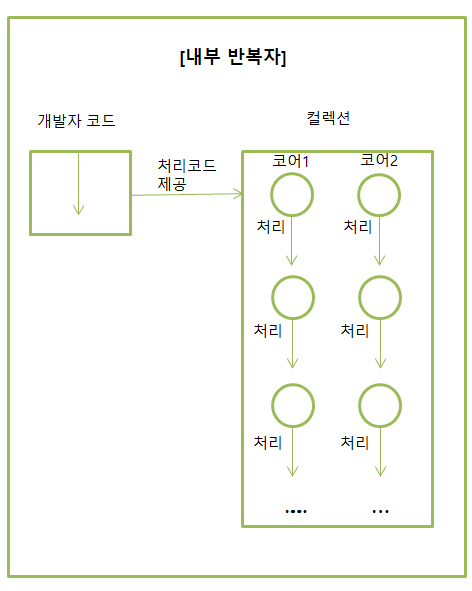
스트림은 람다식으로 요소 처리 내용만 전달할 뿐, 반복은 컬렉션 내부에서 일어난다. 따라서, 요소의 병렬 처리가 컬렉션 내부에서 처리되므로 효율적인 병렬 처리가 가능하다.
Stream API의 연산 종류
Stream API의 3가지 단계
Stream은 데이터를 처리하기 위해 다양한 연산들을 지원한다. Stream이 제공하는 연산을 이용하면 복잡한 작업들을 간단히 처리 할 수 있는데, 스트림에 대한 연산은 크게 생성하기, 가공하기, 결과만들기 3가지 단계로 나눌 수 있다.
- 생성하기
- 가공하기
- 결과만들기
1. 생성하기
- Stream 객체를 생성하는 단계
- Stream은 재사용이 불가능하므로, 닫히면 다시 생성해주어야 한다.
Stream 연산을 하기 위해서는 먼저 Stream 객체를 생성해주어야 한다. 배열, 컬렉션, 임의의 수, 파일 등 거의 모든 것을 가지고 스트림을 생성할 수 있다. 여기서 주의할 점은 연산이 끝나면 Stream이 닫히기 때문에, Stream이 닫혔을 경우 다시 Stream을 생성해야 한다.
2. 가공하기
- 원본의 데이터를 별도의 데이터로 가공하기 위한 중간 연산
- 연산 결과를 Stream으로 다시 반환하기 때문에 연속해서 중간 연산을 이어갈 수 있다.
가공하기 단계는 원본의 데이터를 별도의 데이터로 가공하기 위한 중간 연산의 단계이다. 어떤 객체의 Stream을 원하는 형태로 처리할 수 있으며, 중간 연산의 반환값은 Stream이기 때문에 필요한 만큼 중간 연산을 연결하여 사용할 수 있다.
3. 결과 만들기
- 가공된 데이터로부터 원하는 결과를 만들기 위한 최종 연산
- Stream의 요소들을 소모하면서 연산이 수행되기 때문에 1번만 처리가능하다.
[ Stream 연산 예시 코드 ]
List<String> myList = Arrays.asList("a1", "a2", "b1", "c2", "c1");
myList
.stream() // 생성하기
.filter(s -> s.startsWith("c")) // 가공하기(중간연산)
.map(String::toUpperCase) // 가공하기(중간연산)
.sorted() // 가공하기(중간연산)
.count(); // 결과만들기(최종연산)위의 코드에서는 먼저 stream()을 통해 Stream 객체를 생성하고 있다. 그리고 원하는 데이터를 필터링하고, 변형하고, 정렬하는 중간 연산을 진행하고 있다. 이렇듯 중간 연산이 세미콜론 없이 여러 번 연결되는 것은 해당 중간 연산이 Stream을 반환하기 때문이다. 이렇게 Stream 연산이 연결된 것을 연산 파이프라인이라고 하기도 한다. 최종 연산에서는 필요한 결과를 만들 수 있다. 위의 예제에서는 count()를 통해 남아 있는 요소의 갯수를 최종적으로 반환하도록 되어 있다. 물론 forEach와 같이 값을 반환하지 않는 최종 연산도 존재한다.
위의 예시 코드에서 확인 가능하듯 Stream 연산들은 매개변수로 함수형 인터페이스(Functional Interface)를 받도록 되어있다.
함수형 인터페이스(Functional Interface) 및 람다식에 대한 내용은 아래 포스팅 참고
참고