정수 자료형
자바의 정수를 표현하기 위한 자료형은 대표적으로 int, long 이 있다. (byte, short 도 있지만 잘 사용하지 않는다.)

int age = 10;
long countOfStar = 8764827384923849L;※ 참고
long 변수에 값을 대입할 때는 대입하는 숫자 값이 int 자료형의 최대값인 2147483647 보다 큰 경우
8764827384923849L 과 같이 값 뒤에 L 접미사를 붙여주어야 한다.
만약 접미사를 누락하면 컴파일 에러가 발생한다.
소문자 l 를 써도 되지만 숫자 1과 비슷하게 보이므로 추천되지는 않는다.
정수 오버플로우 / 언더플로우
정수형 데이터의 타입을 사용할 때에는 반드시 자신이 사용하고자 하는 데이터의 최소/최대 크기를 고려해야 한다.
만약 해당 타입이 표현할 수 있는 범위를 벗어난 데이터를 저장하게 되면, 오버플로우(overflow)가 발생해 전혀 다른 값이 저장될 수 있기 때문이다.
- 오버플로우 : 해당 타입이 표현할 수 있는 '최대 표현 범위'보다 큰 수를 저장할 때 발생하는 현상
- 언더플로우 : 해당 타입이 표현할 수 있는 '최소 표현 범위'보다 작은 수를 저장할 때 발생하는 현상
byte max = 127;
byte min = -128;
System.out.println(max + 1000); // 오버플로우
System.out.println(min - 1000); // 언더플로우자바에서 byte 타입이 표현할 수 있는 정수 크기 범위는 -128부터 127까지 이다.
하지만 위의 코드 처럼 바이트 타입의 변수에 크기 범위를 넘어서는 연산을 하게 되면 오버플로우, 언더플로우가 발생하여 잘못된 결과가 저장되게 된다.
※ 참고
자바의 경우 int 형을 기본으로 연산을 진행한다. 즉, int 형 보다 작은 byte, char 같은 경우 내부적으로 4byte로 변환되어 연산한다.
그렇게 때문에 위 코드를 실행해보면 1127, -1128 과 같은 정상적인 값이 출력될 것이다. 단지 예시를 위해 표현 범위가 작은 byte를 사용했다.
int max = Integer.MAX_VALUE;
System.out.println(max); // 2147483647
System.out.println(max + 1000); // -2147482649 (오버플로우)위와 같이 코드를 작성해보면 오버플로우를 정상적으로 경험해볼 수 있을 것이다.
underscore 표기법
언더스코어 표기법은 JDK7 부터 지원하는 문법으로, 우리가 큰 숫자를 콤마 1000,000,000 로 표현하듯이 프로그래밍에선 콤마 대신 밑줄 문자로 표현해도 실제로는 숫자로 읽혀지게 된다.
int cost = 1000_000_000; // 1000000000
2진수 / 8진수 / 16진수
8진수와 16진수 정수는 int 자료형을 사용하여 표시하지만, 숫자 앞에 약속된 기호를 붙여주어서 이 둘을 구분한다.
// 0(숫자 '0')으로 시작하면 8진수
int octal = 023;
// 0x(숫자 '0' + 알파벳 'x')로 시작하면 16진수
int hex = 0xC;
// 0b(숫자 '0' + 알파벳 'b')로 시작하면 2진수
int binary 0b101
실수 자료형
자바의 실수를 표현하기 위한 자료형은 대표적으로 float, double 이 있다.
과거에는 실수를 표현할 때 float형을 많이 사용했지만, 하드웨어의 발달로 인한 메모리 공간의 증가로 현재에는 double형을 가장 많이 사용한다.
따라서 실수형 타입 중 기본이 되는 타입은 double형 이다.

float pi = 3.14F;
double morePi = 3.14159265358979323846;※ 참고
위의 정수 long 타입 처럼, float 변수에 값을 대입할 때에는 3.14F 와 같이 F접미사(또는 소문자 f)를 꼭 붙여 주어야 한다.
실수의 표현 오차
컴퓨터는 모든 데이터를 내부적으로 2진수로 처리한다.
그런데 컴퓨터의 메모리는 한정적이기 때문에 정수를 표현할수 있는 수의 제한이 있듯이, 실수의 소숫점을 표현할 수 있는 수의 제한이 존재한다.
그래서 이러한 실수의 부정확한 연산의 한계를 최소화하기 위해 컴퓨터에서는 소수를 이진법으로 표현할때 고정 소수점 방식 이 아닌 부동 소수점 방식을 이용한다.

부동 소수점 방식을 사용하면 매우 큰 범위의 실수까지도 표현할 수 있어 보다 정밀하게 소수를 표현할수는 있지만 그래도 완전히 정확하게 표현하는 것이 아니라서, 소수 연산에 있어 부정확한 실수의 계산값을 초래하게 된다.
즉, 오차가 필연적으로 발생하게 된다는 뜻이다.
이것은 자바뿐만 아니라, 모든 프로그래밍 언어에서 발생하는 기본적인 문제이다.
실수 표현(부동 소수점) 방식
실수의 2진수 표현 10진수의 정수를 2진수의 정수로 변환할 수 있듯이, 10진수의 소수를 2진수의 소수로 변환할 수 있다. 예를들어 10진수 11.765625 를 2진수 소수로 변환하는 방법은 다음과 같다. 먼
s-y-130.tistory.com
double value1 = 12.23;
double value2 = 34.45;
// 기대값 : 46.68
System.out.println(value1 + value2); // 46.6800000000000112.23 와 34.45 을 더했으니 기대 결과로 46.68 이 나와야 되지만, 실제로는 46.68000000000001가 출력되어 버린다.
이처럼 컴퓨터에서의 실수 연산에서는 소수점 단위 값을 정확히 표현하는 것이 아니라 근사값으로 처리하기 때문에, 정밀도의 문제로 인해 오차가 발생하게 되는 것이다.
물론 수 자체의 크기로서는 근사한 차이 정도 밖에 안되겠지만, 금융이나 로봇과 같은 관련 프로그램에서는 이 오차가 큰 영향을 미칠 수 있기 때문에 아주 정확한 계산이 필요하다.
따라서 이러한 컴퓨터의 실수 연산 문제를 해결 하기 위해 자바(Java)에서는 두가지 방법을 제공한다.
결론부터 말하자면 실수를 int, long 정수형 타입으로 치환하여 사용하거나, BigDecimal 클래스를 이용하면 된다.
예를 들어 12.23 과 34.45 에 100을 곱해서 1223 과 3445로 정수로 치환해서 더한 값 4668을 다시 100을 나누어서 소수 결과값 46.68을 도출하는 일종의 편법이라고 보면 된다.
하지만 컴퓨터에서는 데이터의 표현 범위가 제한되어 있기 때문에, 소수의 크기가 9자리를 넘지 않으면 int 타입을 사용하면 되고, 18자리를 넘지 않으면 long 타입을 사용하면 되지만, 만일 18자리를 초과하면 BigDecimal 클래스를 사용해야 한다.
double a = 1000.0;
double b = 999.9;
System.out.println(a - b); // 0.10000000000002274
// 각 숫자에 10을 곱해서 소수부를 없애주고 정수로 형변환
long a2 = (long)(a * 10);
long b2 = (long)(b * 10);
double result = (a2 - b2) / 10.0; // 그리고 정수끼리 연산을 해주고, 다시 10.0을 나누기 하여 실수로 변환하여 저장
System.out.println(result); // 0.1
// BigDecimal 자료형을 사용
BigDecimal bigNumber1 = new BigDecimal("1000.0");
BigDecimal bigNumber2 = new BigDecimal("999.9");
BigDecimal result2 = bigNumber1.subtract(bigNumber2); // bigNumber1 - bigNumber2
System.out.println(result2); // 0.1
실수의 유효 자릿수 (정밀도)
자바에서는 실수의 소수 자리를 표현하는데 있어 타입별 유효 자릿수 제한이 존재한다.
유효자릿수는 소수점 이하 자리수를 뜻하는 것이 아니라 좌측부터의 숫자 갯수를 의미한다.

위 처럼 유효자릿수가 나오는 이유는 부동소수점 표현 방식에 따른 결과로, 가수부를 표현할 수 있는 크기에 따라 결정되기 떄문이다.
첨고로 유효 자릿수 구하는 방법은 float형은 log10(2^23) = 7.224... (약7자리), double형은 log10(2^52) = 15.653...(약15자리) 가 된다.
이 유효자릿수는 곧 실수의 정밀도를 의미 하기도 한다.
자릿수까지 변수에 저장된 값을 보장하는 것을 정밀도라고 한다.
즉, 정밀도 약 6~7 자릿수라는 뜻은 6~7 자릿수 까지는 실제값과 동일하다라고 생각하면 된다.
참고로 자릿수가 범위인 이유는 저장된 값은 공식에 의해 실제값보다 더 근사할 수도 있고 덜 근사할 수도 있기 때문이다.

// 짧은 실수 저장
double var1 = 3.14;
float var2 = 3.14f;
System.out.println("var1 : " + var1); // var1 : 3.14
System.out.println("var2 : " + var2); // var2 : 3.14
// 긴 실수를 저장 (정밀도 테스트)
double var3 = 3.14159265358979;
float var4 = 3.14159265358979f;
System.out.println("var3 : " + var3); // var3 : 3.14159265358979 - 정확히 표현
System.out.println("var4 : " + var4); // var4 : 3.1415927 - 유효자리 제한때문에 잘리고 반올림 됨 (정밀도 ↓)※ 참고
[ 실수형의 선택 기준 ]
만일 보다 정확한 실수의 정밀도가 필요하다면, 변수의 타입을 double로 하면 된다.
double타입은 float 타입보다 정밀도가 약 2배인, 10진수로 15자리의 유효자리를 가지기 때문이다.
하지만 연산속도의 향상이나 메모리를 절약하려면 float 타입을 선택하는 것도 나쁘지 않는 방법이다.
정리하자면, 연산속도 향상이나 메모리 절약하려면 float, 더 큰 값의 범위라던가 더 높은 정밀도를 필요로 한다면 double 을 선택하면 된다.
실수 오버플로우 / 언더플로우
실수형에서도 변수의 값이 표현범위의 최댓값을 벗어나면 오버플로우가 발생한다.
단, 정수형과 달리 실수형에서는 오버플로우가 발생하면 변수의 값은 무한대(infinity)가 된다. 그리고 언더플로우는 실수형으로 표현할 수 없는 아주 작은 값, 즉 양의 최솟값보다 작은 값이 되는 경우를 말하여 값은 0이 된다.
- 오버 플로우 : 무한대 (infinity)
- 언더 플로우 : 양의 최소값보다 작은 값으로 0이 된다.

지수(e) 표기법
지수 표기법은 아주 큰 숫자나 아주 작은 숫자를 간단하게 표기할때 사용되는 표기법으로, 과학적 표기법(scientific notation) 이라도고 불리운다.
길다란 실수 숫자를 나타내는 데 필요한 자릿수를 줄여 표현해준다는 장점이 있다.

double d2 = 1.234e2; // 1.234 x 10^2 = 123.4
double e1 = 1.7e+3; // 1700.0
double e2 = 1.7e-3; // 0.0017
논리형 자료형
참(true) 또는 거짓(false)의 값을 갖는 자료형을 논리형(불리언) 자료형이라고 한다.

boolean isSuccess = true;
boolean isTest = false;
불리언 자료형에는 다음과 같이 숫자 연산의 결과값이 대입 된다.
boolean bool = (2 > 1); // true
boolean bool = (1 == 2); // false
boolean bool = (3 % 2 == 1); // true (3을 2로 나눈 나머지는 1이므로 참이다.)
boolean bool = ("3".equals("2")); // false그래서 이러한 참, 거짓을 판단하는 불리언 연산을 이용해 if문과 같은 조건문에 자주 사용된다.
int base = 180;
int height = 185;
if (height > base) {
System.out.println("키가 큽니다.");
}
문자 자료형
한 개의 문자 값에 대한 자료형은 char 를 이용한다.
주의할 점은 아래 같이 문자값을 ' (단일 인용부호)로 감싸주어야 한다. 만일 " 쌍따옴표를 사용하면 에러가 난다.

char a1 = 'a';
char 타입은 문자값을 표현하는 방식이 다양하다.
아래의 코드를 보면 숫자 97과 \u0061 이라는 값을 넣었더니 똑같이 a 라는 값을 출력하는 것을 볼 수 있다.
첫번째는 문자값, 두번째는 아스키코드값, 세번째는 유니코드값으로 표현한 것이다.
char a1 = 'a'; // 문자로 표현
char a2 = 97; // 아스키코드로 표현
char a3 = '\u0061'; // 유니코드로 표현
System.out.println(a1); // a 출력
System.out.println(a2); // a 출력
System.out.println(a3); // a 출력예를들어 아스키 코드 개념을 알면 다음과 같이 응용할 수 있다.
char 문자 'C'는 아스키 코드 숫자로 103으로 표현 될 수 있다. 그리고 -2 한 숫자인 101은 문자 'A'로 표현될 수 있어서 다음과 같은 식이 성립 되는 것이다.
char a = 'C' - 2; // 103 - 2
System.out.println(a); // 'A'
[ 아스키코드 ]
1962년 안시(ANSI)가 정의한 미국 표준 정보교환 코드이며 1963년 미국표준협회(ASA)에 의해 결정되어 미국의 표준 부호가 되었다.
아스키 코드는 7비트의 이진수 조합으로 만들어져 총 128개의 부호를 표현할 수 있다.
아스키코드의 처음 32개(0~31)는 프린터나 전송 제어용으로 사용되고 나머지는 숫자와 로마 글자 및 도량형 기호와 문장 기호를 나타낸다.

문자열 자료형
문자열이란 문장을 뜻한다.
문자는 하나의 글자로 작은 따옴표로 감싸고, 문자열은 글자의 집합으로서 쌍 따옴표로 감싼다는 차이가 있다.
자바스크립트나 파이썬 같은 언어는 문자와 문자열을 구분하지는 않지만, 자바는 강한 타입 언어이기 때문에 이 둘을 엄격히 구분한다.
"Happy Java"
"a"
"123"
String 클래스
C언어에서는 문자열을 char형 배열로 표현하지만, 자바에서는 문자열을 위한 String이라는 클래스를 별도로 제공한다.
하지만 String 클래스 구성 내부 요소를 보자면, 결국 String도 char[] 배열로 이루어진 데이터 자료라고 볼수 있다.
[JDK 8]
public final class String implements java.io.Serializable, Comparable {
/* The value is used for character storage */
private char[] value; // String 데이터 생김새는 사실 char 배열로 이루어져 있다.
// ...
}[JDK 9]
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/**
* The value is used for character storage.
*/
@Stable
private final byte[] value;
// ...
}※ 참고
JDK 8 까지는 String 객체의 값은 char[] 배열로 구성되어져 있지만, JDK 9부터 기존 char[]에서 byte[]을 사용하여 String Compacting을 통한 성능 및 heap 공간 효율(2byte -> 1byte)을 높이도록 수정되었다.
이러한 String 자료형을 이용해 문자열 변수를 표현하는 방법은 다음과 같이 두가지가 존재한다.
String a = "Happy Java"; // 리터럴 방식
String b = new String("Happy Java"); // 생성자 방식보통 문자열을 표현할 때는 가급적 첫번째 방식(리터럴 표기)을 사용하는 것이 좋다.
첫 번째 처럼 사용하면 가독성에 이점이 있고 컴파일 시 최적화에 도움을 주기 때문이다.
String 자료형과 위에서 배운 int, double, char, boolean 자료형과의 가장 큰 차이점은, int, double, char는 원시(primitive) 자료형로 분류되고, String 자료형은 참조(reference) 자료형으로 분류 된다는 점이다.
그리고 원시 타입의 데이터는 stack 영역에 그대로 저장되지만, 참조 타입의 데이터(문자열)은 heap 영역에 저장되고 주소만 stack 영역에 저장된다.
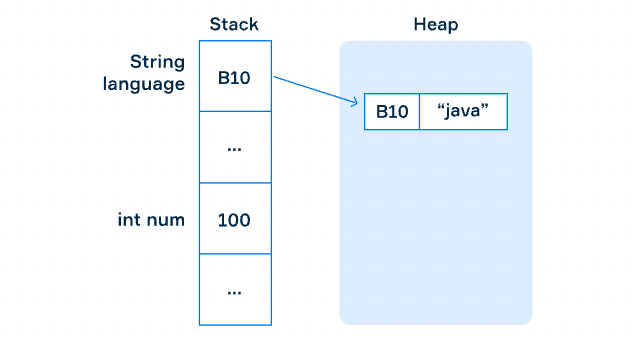
원시 / 참조 타입과 메모리 저장 방식에 관해서는 다음 포스팅을 참고하길 바란다.
[JAVA] 원시 타입 vs 참조 타입
변수의 기본형 & 참조형 타입 변수(variable)란 데이터(data)를 저장하기 위해 프로그램에 의해 이름을 할당받은 메모리 공간을 의미한다. 그리고 자바에서 말하는 데이터 타입(자료형)이란, 변수에
s-y-130.tistory.com
또한 String 인스턴스는 한 번 생성되면 그 값을 읽기만 할 수 있고, 변경할 수는 없다는 특징이 있다.
이러한 객체를 자바에서는 불변 객체(immutable object)라고 한다.
[JAVA] Mutable 객체 vs Immutable 객체
가변 객체 (Mutable Object) 가변 객체는 Java에서 Class의 인스턴스가 생성된 이후에 내부 상태가 변경 가능한 객체이다. 가변 객체는 멀티 스레드 환경에서 사용하려면 별도의 동기화 처리가 필요하
s-y-130.tistory.com
즉, 자바에서 덧셈(+) 연산자를 이용하여 문자열 결합을 수행하면, 기존 문자열의 내용이 변경되는 것이 아니라 내용이 합쳐진 새로운 String 인스턴스가 생성된다.
String s = "ABC";
s += "DEF";
자세한 내용은 다음 포스팅을 참고.
[JAVA] String 타입 특징(String Pool & 문자열 비교)
자바 String의 특징 String은 객체 자바(Java) 프로그래밍에서 String 은 int 와 char 와 달리 기본형(primitive type)이 아닌 참조형(reference type) 변수로 분류 된다. 즉, 스택(stack) 영역이 아닌 객체와 같이 힙(h
s-y-130.tistory.com
문자열 내장 메소드
String 클래스에는 문자열과 관련된 작업을 할 때 유용하게 사용할 수 있는 다양한 메소드가 포함되어 있다.
// 문자열 비교
String a = "hello";
String b = "java";
String c = "hello";
System.out.println(a.equals(b)); // false 출력
System.out.println(a.equals(c)); // true 출력
// 문자열 순서 비교 (오츰차순 또는 내림차순으로 어떤 문자열이 앞이나 뒤에 있는지 확인할때)
int value = "abc".compareTo("jzis"); // -9 (의미 abc가 더 앞이다)
int value = "jzis".compareTo("abc"); // 9 (의미 abc가 더 앞이다)
int value = "aa".compareTo("aaa"); // -1 (의미 aa가 더 앞이다)String a = "Hello Java";
// 문자열에서 특정 문자열이 포함되어 있는지의 여부
a.contains("Java"); // true 출력
// 문자열 앞부분과 돌일 여부
a.startWith("Java"); // true 출력
// 문자열에서 특정 문자가 시작되는 위치(인덱스)를 리턴
// 만일 문자열이 포함되어 있지 않으면 -1을 반환
a.indexOf("Java"); // 6 출력
// 문자열에서 특정 위치의 문자(char)를 리턴
a.charAt(6); // "J" 출력String a = "Hello Java";
// 문자열 중 특정 부분을 뽑아내고 싶을 때 (시작위치 <= a < 끝위치)
a.substring(0, 4); // Hell 출력
a.substring(4); // o Java 출력
// 문자열을 합칠 때
a.concat(" World"); // Hello Java World 출력
// 첫번째 매개 변수로 전달된 문자열을 모두 찾아, 두 번째 매개변수로 치환
a.replaceAll("Java", "World") // Java를 World 로 replace → Hello World 출력
String text = "카페라떼, 녹차라떼, 코드라떼";
text.replace("라떼", "AA"); // "카페AA, 녹차AA, 코드AA"String a = "a:b:c:d";
// 문자열을 특정 구분자로 분리하여 배열로 만듬
String[] str = a.split(":"); // result는 {"a", "b", "c", "d"}
// 배열을 다시 하나의 문자열로 합침. 이때 배열 원소들을 . 구분자를 넣어 결합한다
str.join("."); // "a.b.c.d"String a = "Hello Java";
// 문자열을 모두 대문자로 변경
a.toUpperCase(); // HELLO JAVA 출력
// 문자열을 모두 소문자로 변경
a.toLowerCase(); // hello java 출력
// 문자열의 맨 앞과 맨 뒤에 포함된 모든 공백 문자를 제거
String a2 = " Hello Java ";
a2.trim(); // Hello Java (앞뒤 공백 제거)| 메서드 | 설 명 |
| String(String s) | 주어진 문자열( s )를 갖는 String 인스턴스 생성 |
| String(char[ ] value) | 주어진 문자열( char 배열인 value )를 갖는 String 인스턴스 생성 |
| String(StringBuffer buf) | StringBuffet 인스턴스인 buf 가 갖고있는 문자열과 같은 내용의 String 인스턴스 생성 |
| char charAt(int index) | 지정된 위치( index , 0부터 시작)에 있는 문자를 알려준다. |
| int compareTo(String str) | 문자열( str )과 사전순서로 비교한다. (같으면 0 , 이전이면 음수 , 이후면 양수 (떨어진 숫자만큼)를 반환) int i = "a".compareTo("a"); → 0반환 int i2 = "a".compareTo("c"); → -2반환 int i3 = "e".compareTo("a"); → 4반환 |
| String concat(String str) | 문자열( str )을 뒤에 덧붙임 |
| boolean contains(CharSequence s) | 지정된 문자열( s )이 포함되었는지 검사 |
| boolean endsWith(String suffix) | 지정된 문자열( suffix )로 끝나는지 검사 |
| boolean equals(Object obj) | 매개변수로 받은 문자열( obj )과 String 인스턴스의 문자열을 비교 (문자열이 다르거나 Obj 가 String 이 아닌경우 false 를 반환) |
| boolean equalsIgnoreCase(String str) | 대소문자의 구분없이 String 인스턴스의 문자열을 문자열( str )과 비교 |
| int indexOf(int ch) | 주어진 문자( ch )가 문자열에 존재하는지 확인하여 위치( index )를 반환 (index는 0부터 시작하고, 못찾으면 -1을 반환) |
| int indexOf(int ch, int pos) | 주어진 문자( ch )가 문자열에 존재하는지 지정된위치( pos )부터 확인하여 위치( index )를 알려준다. (index는 0부터 시작하고, 못찾으면 -1을 반환) |
| int indexOf(String str) | 주어진 문자열( str )이 존재하는지 확인하여 그 위치( index )를 반환 (index는 0부터 시작하고, 못찾으면 -1을 반환) |
| String intern( ) | 문자열을 상수풀(constant pool)에 등록 이미 상수풀에 같은 내용의 문자열이 있을 경우에는 그 문자열의 주소값을 반환 |
| int lastIndexOf(int ch) | 지정된 문자 또는 문자코드( ch )를 오른쪽 끝에서부터 찾아 위치( index )를 반환 (못찾으면 -1을 반환) |
| int lastIndexOf(String str) | 지정된 문자열( str )을 인스턴스의 문자열 끝부터 찾아 위치( index )를 반환 (못찾으면 -1을 반환) |
| int length( ) | 문자열의 길이 반환 |
| String replace(char old, char nw) | 문자열 중의 문자( old )를 새로운 문자( nw )로 모두 바꾼 문자열을 반환 |
| String replace(CharSequence old, CharSequence nw) | 문자열의 문자열( old )을 새로운 문자열( nw )로 모두 바꾼 문자열을 반환 |
| String replaceAll(String regex, String replacement) | 문자열 중에서 지정된 문자열( regex )와 일치하는 것을 새로운 문자열( replacement )로 모두 변경 |
| String replaceFirst(String regex, String replacement) | 문자열 중에서 지정된 문자열( regex )와 일치하는 것중, 첫번째 것만 새로운 문자열( replacement )로 변경 |
| String[ ] split(String regex) | 문자열을 지정된 분리자( regex )로 나누어 문자열 배열에 담아 반환 String s1 = "one,two,three"; String[ ] s2 = s1.split(","); → s2배열에 ,를 기준으로 나뉜 3개의 배열이됨 |
| String[ ] split(String regex, int limit) | 문자열을 지정된 분리자( regex )로 나누어 문자배열에 담아 반환하되 문자열 전체를 지정된 개수( limit )로 나눈다. String s1 = "one,two,three"; String[ ] s2 = s1.split(",", 2); → s2배열에 ,를 기준으로 나누되 2개의 배열이 됨 |
| String[] join(String regex, String[] str) | 문자열 배열을 하나의 문자열로 합치는데, 구분자를 넣어 각 요소를 구분해줄 수 도 있다. |
| boolean startsWith(String prefix) | 주어진 문자열( prefix )로 시작하는지 검사 |
| String substring(int begin) String substring(int begin, int end) |
주어진 시작위치( begin )부터 끝위치( end )범위에 포함된 문자열을 얻는다. (※ 시작위치는 포함되지만 끝위치는 포함되지 X , begin <= x < end ) |
| String toLowerCase( ) | String 인스턴스에 저장되어 있는 모든 문자열을 소문자로 변환하여 반환 |
| String toUpperCase( ) | String 인스턴스에 저장되어 있는 모든 문자열을 대문자로 변환하여 반환 |
| String trim( ) | 문자열의 왼쪽 끝과 오른쪽 끝에 있는 공백을 없앤 결과를 반환. (문자열 중간에 있는 공백은 제거되지 X) |
| String toString( ) | String 인스턴스에 저장되어 있는 문자열을 반환 |
| static String valueOf(boolean b) static String valueOf(char c) static String valueOf(int i) static String valueOf(long l) static String valueOf(float f) static String valueOf(double d) static String valueOf(Object o) |
지정된 값을 문자열로 변환하여 반환 참조변수의 경우, toString( ) 을 호출한 결과를 반환 |
참고