엔티티 매니저 팩토리 & 엔티티 매니저
영속성 컨텍스트에 대해 알아보기 전에 엔티티 매니저 팩토리와 엔티티 매니저에 대해서 알아보고자 한다.
웹 어플리케이션이 구동하는 시점에 엔티티 매니저 팩토리가 생성되며 DB 커넥션 풀을 생성해 둔 후, 고객의 요청이 들어올 때마다 엔티티 매니저를 생성한다.
엔티티 매니저는 DB 연결이 필요한 시점(보통 트랜잭션이 시작되는 경우)에 커넥션 풀에 있는 connection을 얻어 DB를 핸들링하게 된다.

엔티티 매니저 팩토리가 엔티티 매니저를 사용하는 이유
엔티티 매니저 팩토리는 생성되는 시점에 DB 커넥션 풀을 생성하기에 생성 비용이 매우 크다.
그러나 엔티티 매니저의 생성 비용은 거의 들지 않으므로, 엔티티 매니저 팩토리는 필요에 따라 앤티티 매니저를 생성하여 사용한다.
또한 엔티티 매니저 팩토리는 스레드 세이프(Thread Safe)하다.
즉 여러 스레드가 동시에 접근하여도 안전한 반면, 엔티티 매니저는 여러 스레드가 동시에 접근할 경우 동시성 문제가 발생하게 된다. 따라서 엔티티 매니저는 절대로 공유해서는 안된다.
영속성 컨텍스트(Persistence Context)

영속성 컨텐스트란 엔티티(Entity)를 저장하고 관리하여 영속화시키는 논리적인 저장소 영역 이라고 할 수 있다.
영속화의 사전적 의미는 '사라지지 않고 지속되게 한다' 라는 뜻으로 쉽게 말하자면 DB에 저장된다는 의미이다.
하지만 '영속'이라는 말에 현혹되어서는 안된다. 영속성 컨텍스트에서 관리하는 엔티티라고 해도 반드시 '영속화'되어 DB에 저장된 것은 아니다. 다만 영속화 될 수 있는 가능성이 있을 뿐이다.
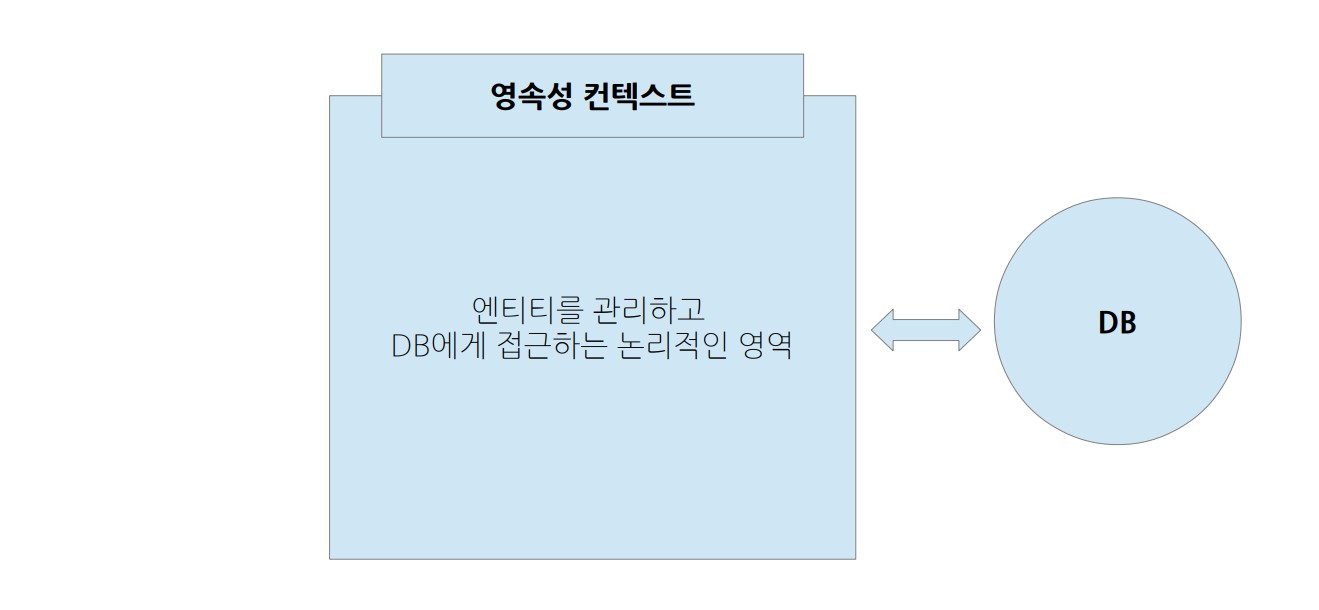
영속성 컨텍스트에서는 엔티티를 관리하고 필요에 따라 DB의 데이터를 저장, 조회, 수정, 삭제할 수 있다. 이러한 작업을 담당하는 객체를 '엔티티 매니저 (Entity Manager)'라고 한다.
영속성 컨텍스트는 크게 2가지 영역으로 나뉜다.
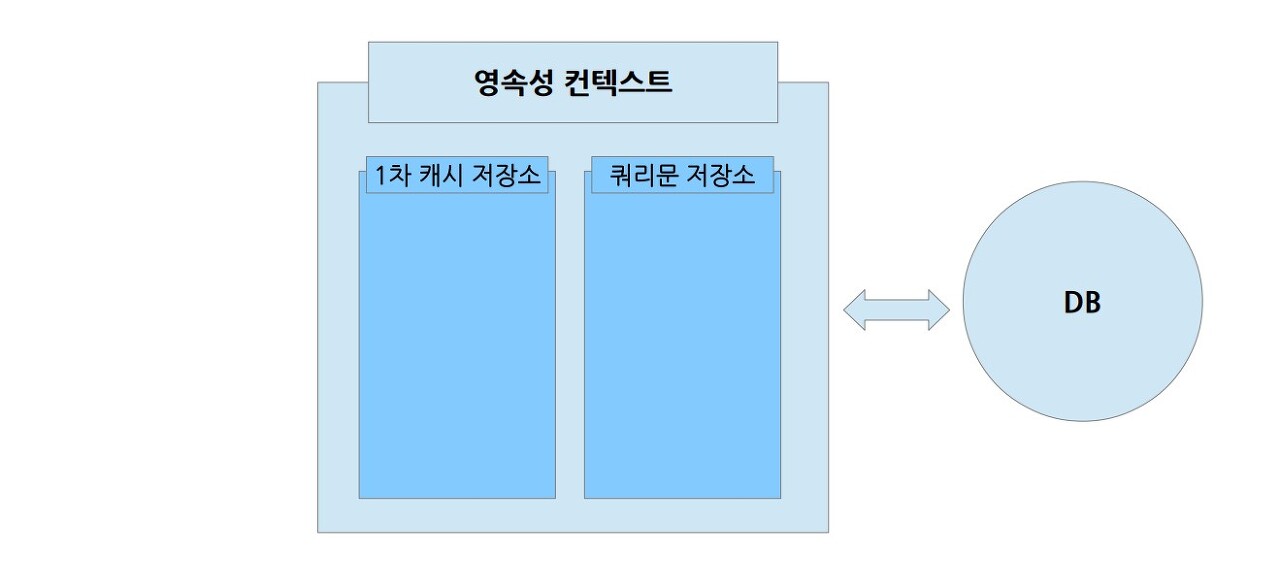
1차 캐시 저장소
영속성 컨텍스트가 관리하는 엔티티 정보를 보관한다. 이 상태를 '영속 상태' 라고 한다. 다시 한번 강조하지만 '영속 상태'는 아직 DB에 저장된 상태는 아니다. 단순히 영속성 컨텍스트에서 관리(managed)하는 상태일 뿐이다.
쿼리문 저장소 (SQL 저장소)
JPA는 필요한 쿼리문(SQL)을 보관해둔다. 최대한 여러 쿼리문을 모아두고, DB에 접근하는 횟수를 최소화하게되면 성능상에 이점을 얻을 수 있기 때문이다. 저장해둔 쿼리문으로 DB에게 접근하는 행위는 엔티티 매니저의 '플러시 flush()'로 진행한다.
엔티티 매니저를 통해 엔티티를 저장하거나 조회하면 엔티티 매니저는 영속성 컨텍스트에 엔티티를 보관하고 관리한다.
- em.persist(member) : 엔티티 매니저를 사용해 회원 엔티티를 영속성 컨텍스트에 저장한다는 의미!
영속성 컨텍스트의 특징
- 엔티티 매니저를 생성할 때 하나 만들어진다.
- 엔티티 매니저를 통해서 영속성 컨텍스트에 접근하고 관리할 수 있다.
- 영속성 컨텍스트에 관리되는 엔티티의 상태를 "영속 상태"라 한다.
- persistence context는 엔티티의 @Id 필드를 이용하여 엔티티를 식별한다. 따라서 엔티티를 정의할 때 식별자 값이 꼭 있어야 한다.
- persistence context에는 쓰기 지연 기능이 있다.
- 즉 값을 변경하자마자 바로 DB에 반영하는 것이 아니라, persistence context에 쓰기 지연 SQL 저장소가 있어서 SQL 쿼리들을 저장해 뒀다가, 엔티티 매니저가 commit() 메서드를 호출할 때 DB에 반영된다. 이를 flush라 한다.
(사실 flush(), commit 의 의미는 약간의 차이가 있지만 지금은 동일시해도 된다.)
- 즉 값을 변경하자마자 바로 DB에 반영하는 것이 아니라, persistence context에 쓰기 지연 SQL 저장소가 있어서 SQL 쿼리들을 저장해 뒀다가, 엔티티 매니저가 commit() 메서드를 호출할 때 DB에 반영된다. 이를 flush라 한다.
- 그 밖에 1차 캐시, 동일성 보장, 변경 감지, 지연 로딩 등의 특징이 있다.
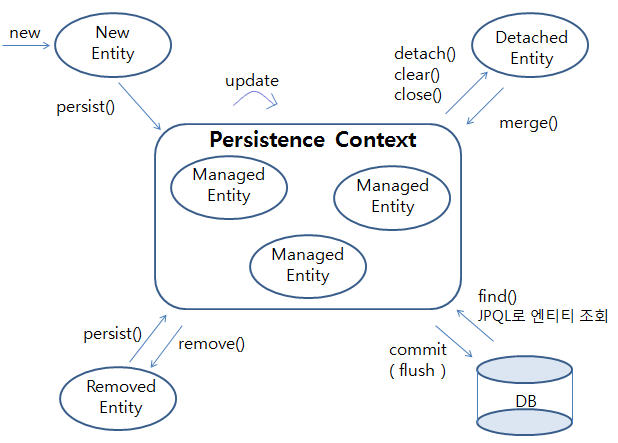
엔티티의 생명주기
JPA(영속성 컨텍스트) 입장에서 엔티티의 생명주기를 4가지로 나눌 수 있다.
엔티티는 쉽게 말해 하나의 인스턴스, DB입장에서는 1건의 레코드 정도로 이해하면 된다.
- 비영속(new/transient): 영속성 컨텍스트와 전혀 관계가 없는 상태
- 영속(managed): 영속성 컨텍스트에 저장된 상태
- 준영속(detached): 영속성 컨텍스트에 저장되었다가 분리된 상태
- 삭제(removed): 삭제된 상태
비영속
엔티티 객체를 생성했지만 아직 영속성 컨텍스트에 저장하지 않은 상태를 비영속(new/transient)라 한다.
//객체를 생성한 상태(비영속) Member member = new Member(); member.setId("member1"); member.setUsername("회원1");
영속
엔티티 매니저를 통해서 엔티티를 영속성 컨텍스트에 저장한 상태를 말하며 영속성 컨텍스트에 의해 관리된다는 뜻이다.
또 한번 말하지만, 이는 아직 DB에 저장된 상태가 아니다. 엔티티 매니저의 'persist()'를 사용하면 비영속 상태의 엔티티를 영속상태로 만들 수 있다.
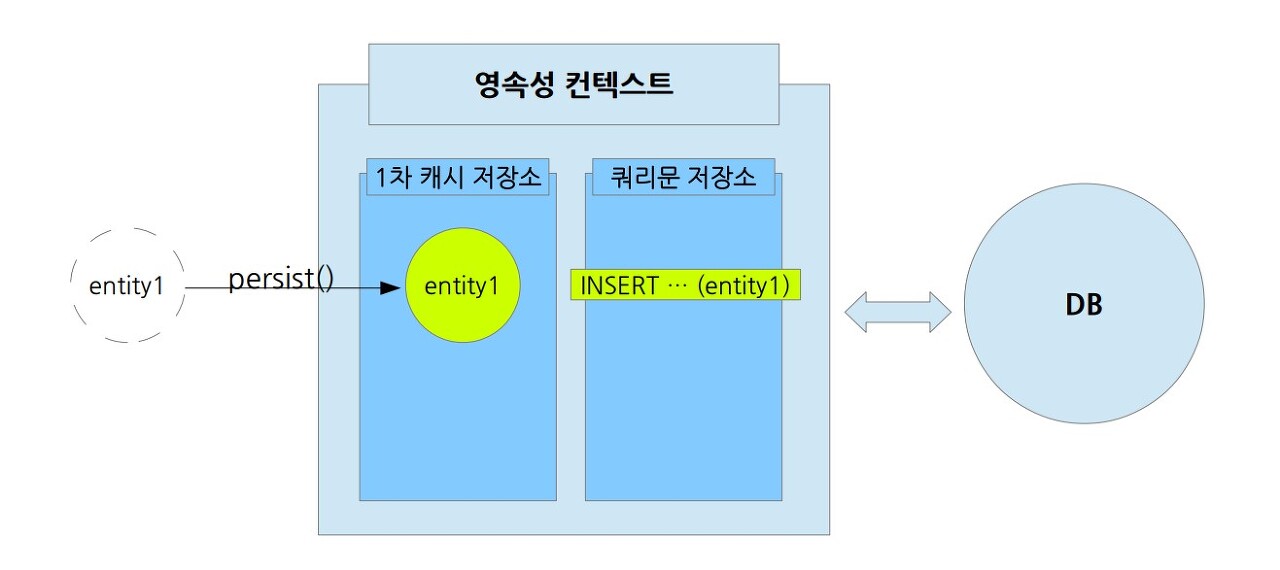
//객체를 생성한 상태(비영속) Member member = new Member(); member.setId("member1"); member.setUsername(“회원1”); EntityManager em = emf.createEntityManager(); em.getTransaction().begin(); //객체를 저장한 상태(영속) em.persist(member);
위의 이미지는 persist()를 실행한 이 후 영속성 컨텍스트를 도식화한 것이다. 엔티티를 저장하는 INSERT 쿼리문이 생성 되었지만, 아직 DB에게 전달되지 않고 쿼리문 저장소에 보관되었다. 이 부분이 영속성 컨텍스트를 이해하는 핵심이다. '플러시 flush()'가 실행되기 전에는 실제 DB에게 접근하지 않는다.
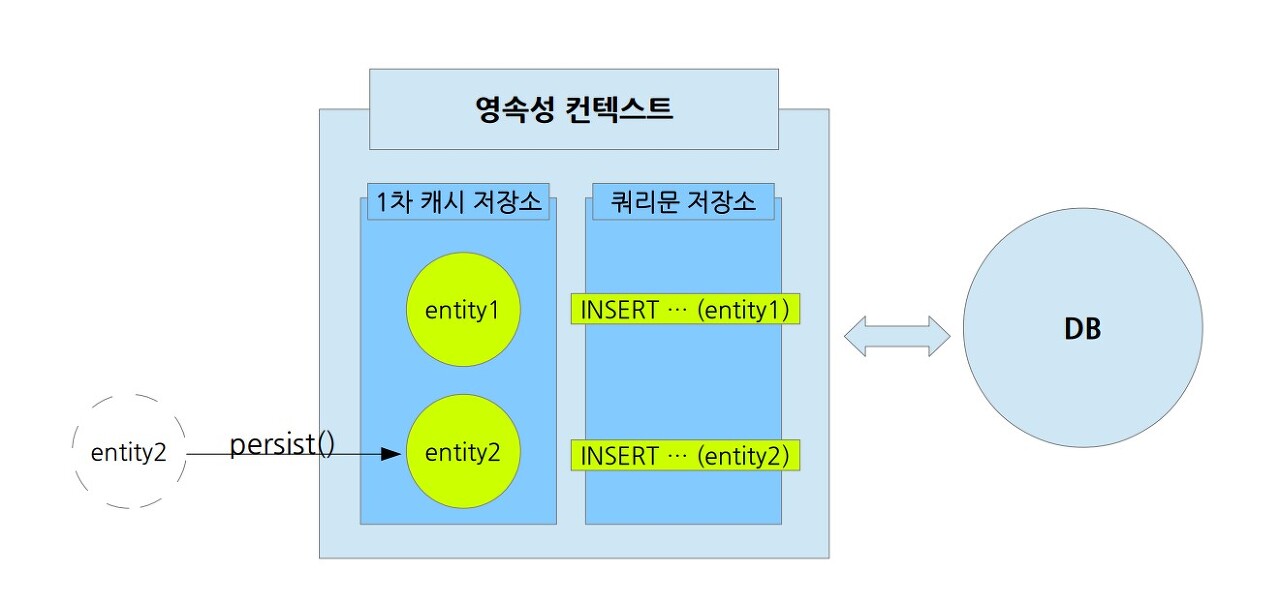
여러개의 엔티티를 persist()하게 되더라도, 해당하는 INSERT 쿼리문은 계속 쿼리문 저장소에 보관하게 된다.
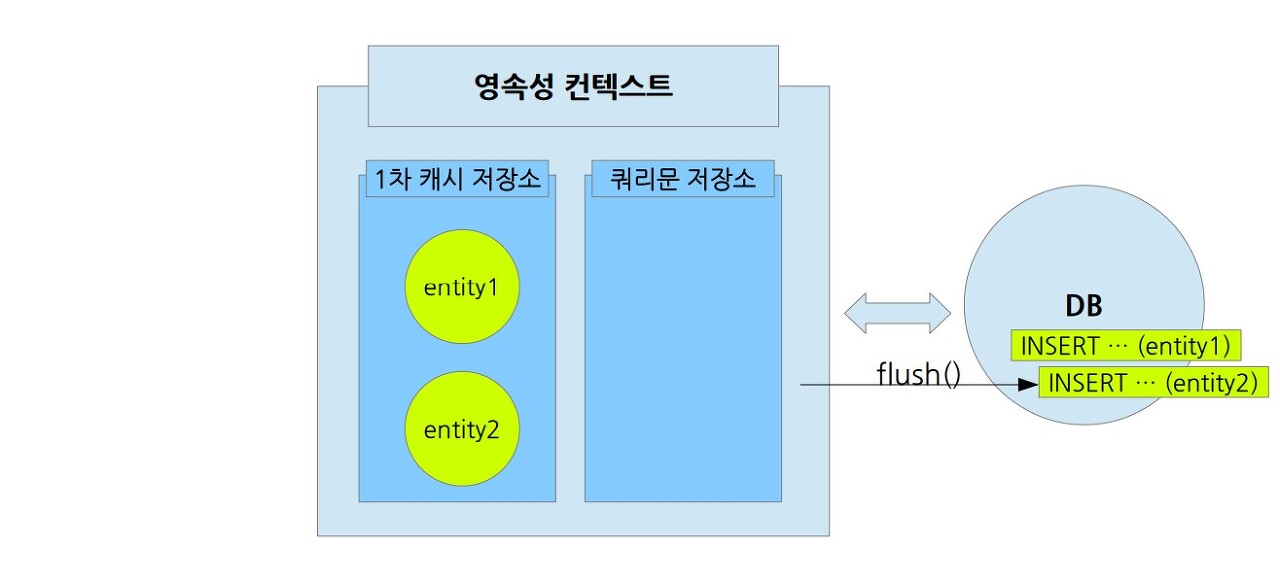
모아둔 쿼리문은 '플러시 flush()'를 실행하게 될 때 DB에 반영한다. 플러시를 하더라도 1차 캐시 저장소에서 관리중인 엔티티들이 사라지는 것은 아니다. flush()는 영속성 컨텍스트와 DB를 동기화(Synchronize) 할 뿐이다.
생성한 엔티티를 입력할 때 이외에도 엔티티 매니저가 DB에서 조회해온 데이터도 '영속 상태'인 엔티티가 된다. 조회해온 데이터는 1차 캐시 저장소에 먼저 저장되고, 저장된 엔티티 정보를 반환한다. 조회를 하기 위해서는 엔티티 매니저의 find()를 사용한다.
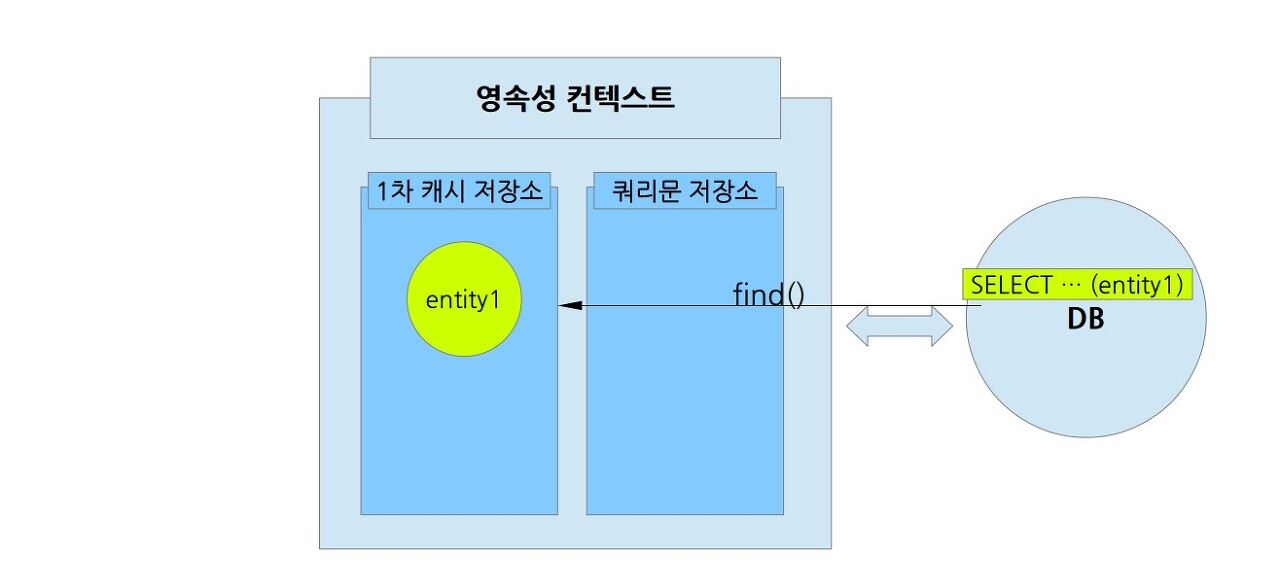
만약 같은 엔티티를 한번 더 조회하게 되면 어떻게 될까? JPA는 1차 캐시 저장소에 있는 엔티티를 반환하고 실제로 DB에 접근은 하지 않는다. JPA가 조회와 관련한 성능상의 큰 이점을 취할 수 있는 이유다. 또한 같은 인스턴스의 참조값을 반환하기 떄문에, == 로 동일성을 비교한다면 같은 인스턴스임을 확인 할 수 있다.
준영속
영속성 컨텍스트가 관리하던 영속 상태의 엔티티 더이상 관리되지 않으면 준영속 상태가 된다.
엔티티를 준영속 상태로 만드는 방법은 3가지가 있다.
1. 특정 엔티티를 준영속 상태로 만들기 위해서는 엔티티 매니저의 detach()를 사용한다.
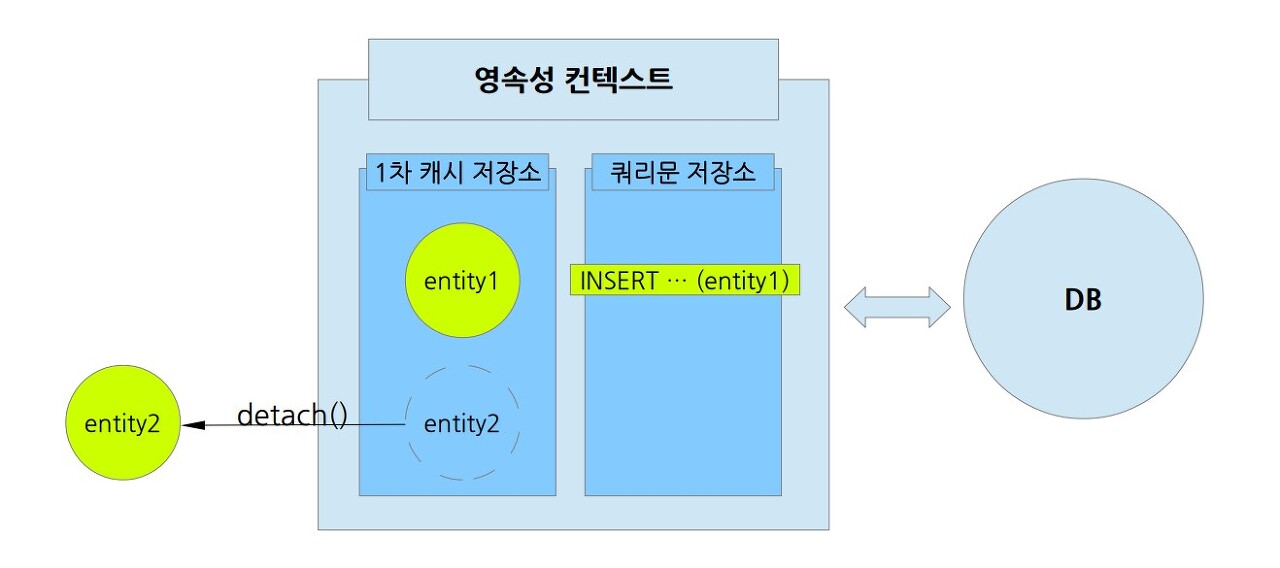
//회원 엔티티를 영속성 컨텍스트에서 분리, 준영속 상태 em.detach(member);
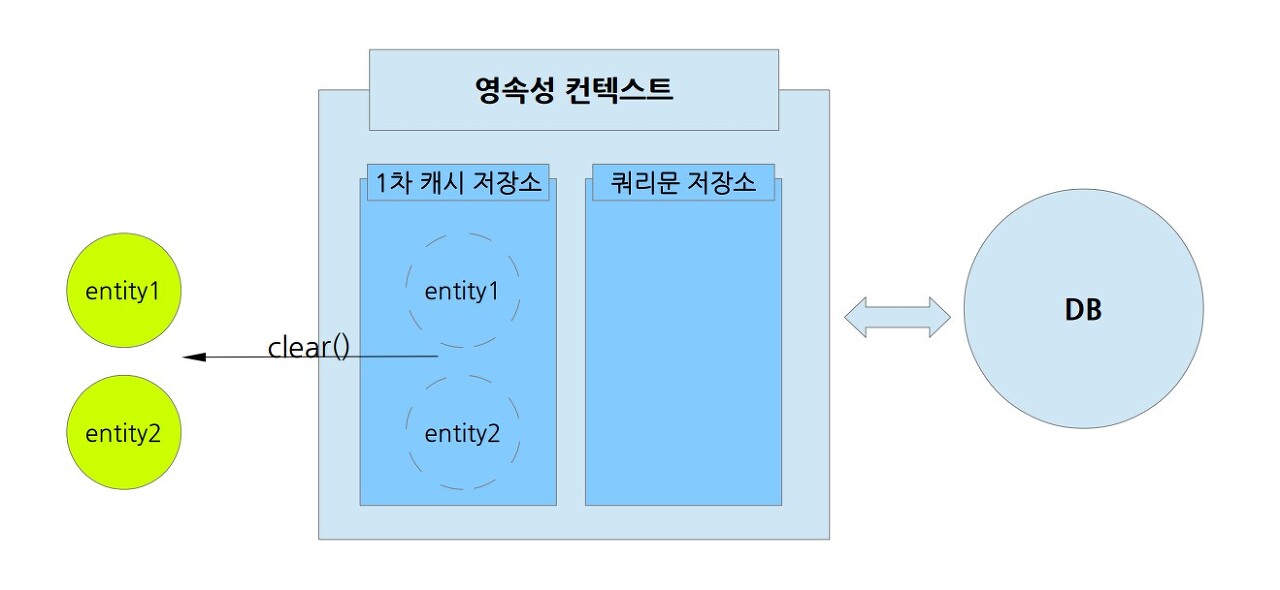
2. 영속성 컨텍스트 전체를 초기화 시키는 clear()를 사용할 수 있다. 이 때 쿼리문 저장소의 보관해둔 쿼리들도 모두 초기화된다.
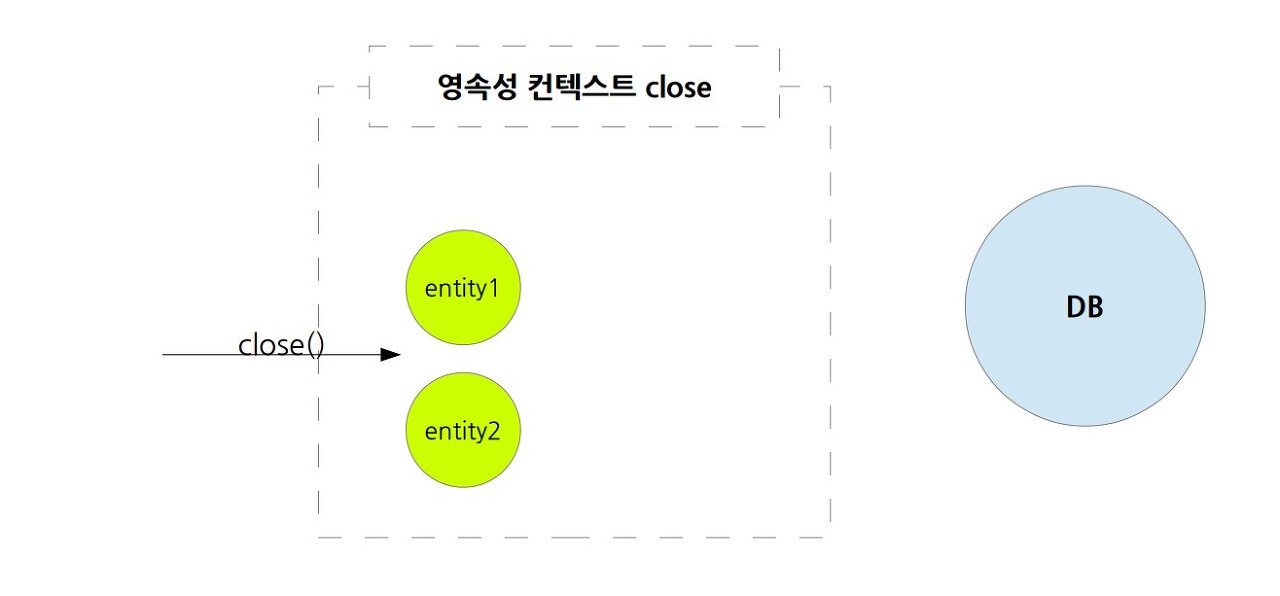
3. 영속성 컨텍스트를 닫아버리는 close()를 사용한다면, 영속성 컨텍스트 자체가 사라지게 되니, 관리되던 엔티티들은 모두 준영속 상태가 된다. (close()는 엄밀히 말해 엔티티 매니저가 닫히는 것이다. 상황에 따라 다르지만 일단은 하나의 엔티티 매니저가 하나의 영속성 컨텍스트에 속한다고 생각하면 된다.)
- 준영속 상태의 엔티티는 엔티티매니저의 merge()를 사용하면 다시 영속성 컨텍스트에서 관리되는 '영속 상태'로 변환 할 수 있다.
준영속 상태의 특징
- 1차 캐시, 쓰기 지연, 변경 감지, 지연 로딩을 포함한 영속성 컨텍스트가 제공하는 어떠한 기능도 동작하지 않는다.
- 식별자 값을 가지고 있다.
삭제
삭제 상태는 엔티티를 영속성 컨텍스트에서 관리하지 않게 되고, 해당 엔티티를 DB에서 삭제하는 DELETE 쿼리문을 보관하게 된다. persist와 마찬가지로 '플러시 flush()'가 호출되기 전까지는 실제 DB에 접근하지 않는다.
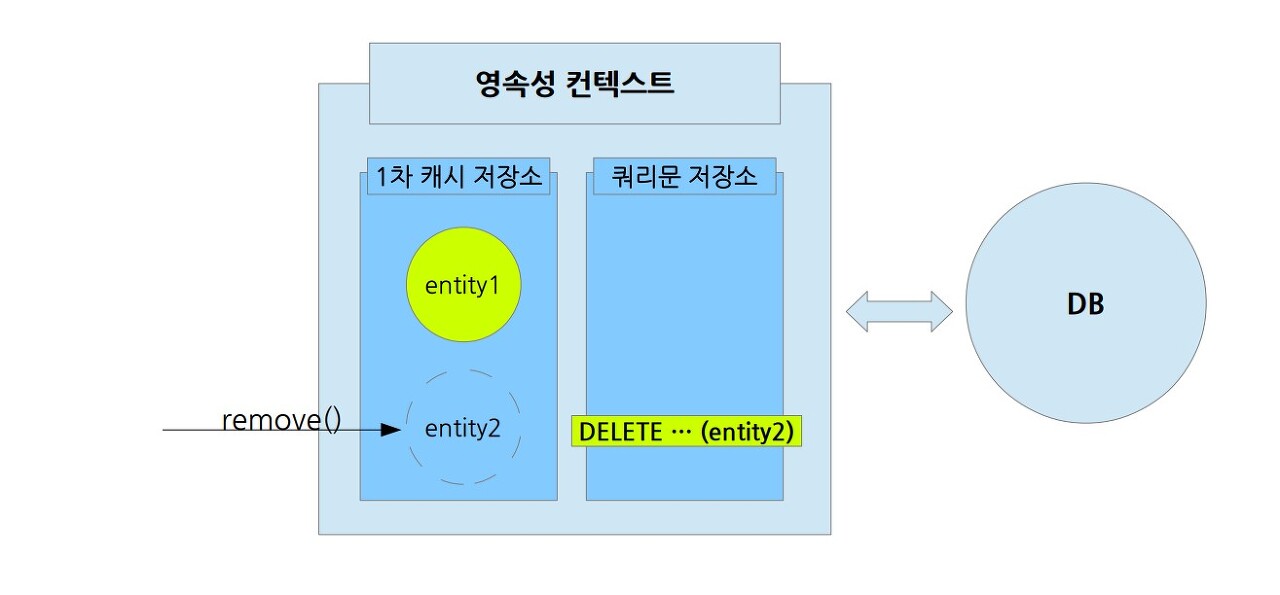
//객체를 삭제한 상태(삭제) em.remove(member);
영속성 컨텍스트가 엔티티를 관리하면 얻게되는 장점
1. 1차 캐시
- Map 객체로 저장 : 엔티티를 식별자 값(@Id 맵핑)으로 구분한다. Key-value로 관리하는데 이때 key 값이 @Id 값이 된다.
- 식별자 값 필요 : 영속상태의 엔티티는 반드시 식별자 값이 있어야 한다.
persistence context에는 1차 캐시( first level cache )라는 것이 존재한다.
엔티티 매니저가 persist() 또는 find() 메서드를 호출하면 그 엔티티는 managed 상태가 되면서 persistence context의 1차 캐시에 저장된다.
1차 캐시는 일종의 Map이라고 생각하면 되는데, key는 @Id로 지정한 식별자이고, value는 엔티티 인스턴스다.
엔티티 추가
예를들어, Member라는 엔티티가 있을 때, 이 엔티티를 추가하는 코드를 가정해보자.
public static void insert(EntityManager em) { //엔티티를 생성한 상태 (비영속) Member member = new Member(); member.setId("member1"); member.setName("회원1"); //엔티티를 영속화, em은 EntityManager em.persist(member); }
INSERT 쿼리를 수행하기 위해서는 em.persist() 메서드를 호출해야 한다. 이 메서드가 실행되면 1차 캐시에는 아래와 같이 해당 엔티티 정보가 저장된다.
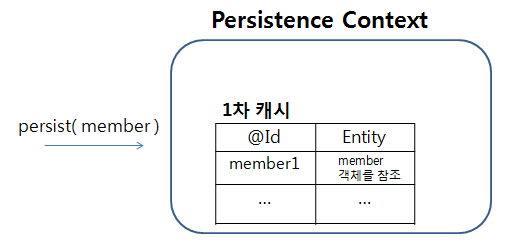
persist() 메서드를 호출하는 것만으로 해당 엔티티는 managed 상태가 된다.
1차 캐시에서 엔티티 조회
이번에는 엔티티를 조회하는 메서드가 실행된다고 가정하겠다.
public static void find(EntityManager em) { Member member = new Member(); member.setId("member2"); member.setName("회원2"); // 1. 1차 캐시에 저장 em.persist(member); // 2. 1차 캐시에서 조회 Member findMember = em.find(Member.class, "member2"); System.out.println(findMember.getName()); }

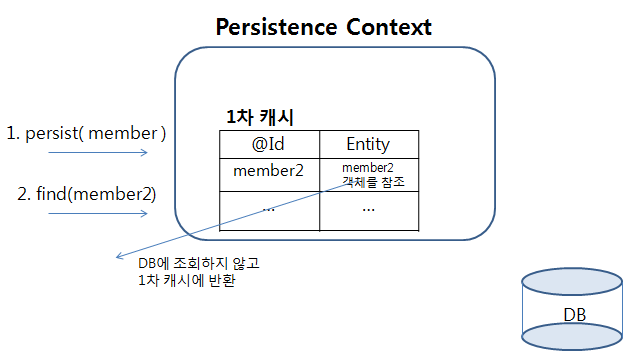
member2 엔티티를 캐시에 저장한 후, 바로 조회하는 메서드다. 이 경우 member2 엔티티가 1차 캐시에 존재하므로 DB에 접근하기 위한 SELECT 쿼리를 수행하지 않는다.
결과를 보면 " 회원2 "와 INSERT 쿼리만 콘솔에 출력되는 것을 확인할 수 있다.
이를 그림으로 그려보면 다음과 같다.
DB에서 엔티티 조회
이번에는 DB에 저장되어 있는 member3를 가져오도록 해보겠다.
public static void find(EntityManager em) { // DB에서 조회 Member findMember = em.find(Member.class, "member3"); System.out.println(findMember.getName()); }
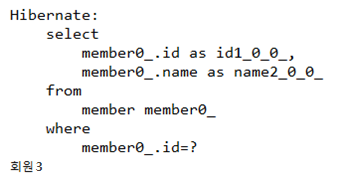
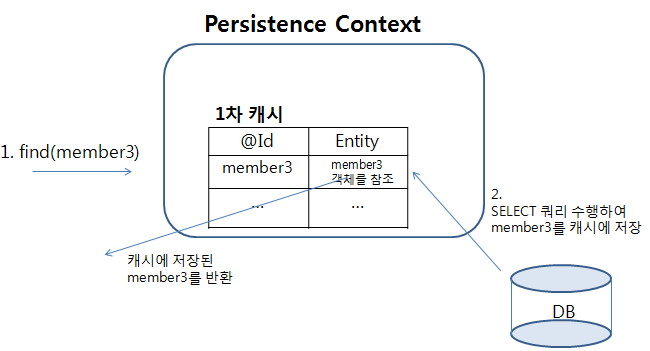
@Id로 지정한 필드의 값이 member3인 엔티티를 조회하는 메서드다.
member3가 1차 캐시에 존재하지 않으므로, DB에서 엔티티를 가져오기 위해 SELECT 쿼리를 수행한다.
1차 캐시 정리
- persist() 메서드를 호출하면 그 엔티티는 1차 캐시에 저장되어 managed 상태가 되어 엔티티 매니저가 관리하게 된다.
- find() 메서드를 호출했을 때는 찾고자 하는 엔티티가 1차 캐시에 없는 상태라면, DB에 SELECT 쿼리를 수행하여 엔티티를 가져온다.
- DB를 조회하여 값을 가져온 경우라면, 가져온 값을 persistence context의 1차 캐시에 저장하여 엔티티를 managed 상태로 만든다.
- 1차 캐시에 존재하는 상태라면 SELECT 쿼리를 수행하지 않고 바로 반환한다.
- 다음 번에 find() 메서드를 호출하면, DB를 거치지 않고 1차 캐시에서 가져올 수 있게된다.
- 어떤 경우에서든지 find() 메서드의 반환 값은 캐시에 저장된 엔티티가 되는 것을 알 수 있다.
이와 같이 캐시를 사용하면 DB에 접근하지 않아도 되므로 성능상의 이점을 누릴 수 있다.
! 참고
엔티티 매니저는 보통 데이터베이스 트랜잭션 단위로 생성하고, 트랜잭션이 끝나는 시점에 종료시킨다.
엔티티 매니저가 종료되면 엔티티 매니저의 1차 캐시에 존재하는 데이터들도 모두 지워진다.
트랜잭션은 길게 발생하지 않고, 굉장히 짧은 찰나의 순간에만 존재한다.
따라서 1차 캐시를 통해서 그렇게 큰 성능 이점을 얻기는 힘들다.
Q1. 1차 캐시를 사용하면 한 가지 기능을 두개의 트랜잭션으로 처리할 경우?
OSIV를 사용하여 영속성 컨텍스트의 데이터를 공유한다.
Q2. 2차 캐시는 언제 사용하나?
하이버네이트가 지원하는 캐시는 크게 3가지가 있다.
엔티티 캐시 : 엔티티 단위로 캐시한다. 식별자로 엔티티를 조회하거나 컬렉션이 아닌 연관된 엔티티를 로딩할 때 사용한다.
컬렉션 캐시 : 엔티티와 연관된 컬렉션을 캐시한다. 컬렉션이 엔티티를 담고 있으면 식별자 값만 캐시한다. (하이버네이트 기능)
- 문제는 쿼리 캐시나 컬렉션 캐시만 사용하고 대상 엔티티에 엔티티 캐시를 적용하지 않으면 성능상 심각한 문제가 발생할 수 있다.
- “select m from Member m” 쿼리를 실행했는데 쿼리 캐시가 적용되어 있다. 결과 집합은 100건이다.
- 결과 집합에는 식별자만 있으므로 한 건씩 엔티티 캐시 영역에서 조회한다.
- Member 엔티티는 엔티티 캐시를 사용하지 않으므로 한 건씩 데이터베이스에서 조회한다.
- 결국 100건의 SQL이 실행된다.
쿼리 캐시 : 쿼리와 파라미터 정보를 키로 사용해서 캐시한다. 결과가 엔티티면 식별자 값만 캐시한다. (하이버네이트 기능)
2. 동일성 보장
동일성 비교: 실제 인스턴스가 같다. == 을 사용해 비교한다.
동등성 비교: 실제 인스턴스는 다를 수 있지만 인스턴스가 가지고 있는 값이 같다. equals() 메소드를 구현해서 비교한다.
[JAVA] 동일성(identity)과 동등성(equality)에 관한 대용은 해당 포스팅 참고.
JDBC( Mybatis )에서는 쿼리를 수행할 때 마다 DB에서 매 번 가져오지만, JPA의 경우 1차 캐시에 있는 엔티티를 조회하므로 동일한 객체를 반환한다.
public static void identity( EntityManager em) { Member a = em.find(Member.class, "member1"); Member b = em.find(Member.class, "member1"); System.out.println(a == b); }

- 처음 find() 메서드가 호출 되었을 때 1차 캐시에는 아무 것도 없는 상태이므로 DB에서 엔티티를 가져오기 위한 SELECT 쿼리를 수행한다
- 이어서 find() 메서드가 호출 되면 1차 캐시에 엔티티가 존재하므로 1차 캐시에 있는 엔티티를 반환한다
- 이 때 1차 캐시에서 참조하고 있는 엔티티는 같은 객체이므로 동일성 비교 결과 true가 반환되는 것을 알 수 있다.
즉, JPA는 하나의 트랜잭션 안에 존재하는(= 1차 캐시 내에 존재하는) @Id(식별자 값)가 같은 엔티티에 대해서 동일성을 보장해준다
다음과 같이 표현 가능하다
1차 캐시로 반복 가능한 읽기(REPEATABLE READ) 등급의 트랜잭션 격리 수준을 데이터베이스가 아닌 애플리케이션 차원에서 제공한다.
영속 엔티티와, 비영속 혹은 준영속 엔티티의 비교
동일성을 보장하지 않는다.
코드를 통해 살펴보겠다.
Member memberA = em.find(Member.class, 1L); em.clear();//해당 코드가 있으면 false, 없으면 true Member memberB = em.find(Member.class, 1L); System.out.println(memberA == memberB);
위 코드에서 em.clear()로 영속성 컨텍스트를 비워주면, false가 출력된다
그렇다면 다음은 어떨까?
Member memberA = em.find(Member.class, 1L); Member memberB = em.find(Member.class, 1L); em.clear(); System.out.println(memberA == memberB);
위 코드를 실행 결과는 true다.
이유는 다음과 같다.
첫 번째 find를 통해 DB에서 Member를 조회한다. 그리고 조회한 멤버를 1차 캐시에 등록한다.
두 번째 find는 1차 캐시에서 값을 확인했는데 존재한다. 따라서 1차 캐시에 존재하는 값을 가져온다
그 이후 영속성 컨텍스트를 비우더라도, 이미 memberB는 1차 캐시에 존재하는 member의 참조주소를 가지고 왔기에 true가 출력되는 것이다.
3. 쓰기 지연 ( transaction write behind )
영속성 컨텍스트에는 1차캐시 말고도 "쓰기 지연 저장소"가 존재한다.
persist() 메서드를 호출하면 INSERT 쿼리가 수행되어 엔티티를 추가할 수 있다.
그러나 바로 DB에 추가하는 것이 아니라, persistence context 내부에 있는 쿼리 저장소에 INSERT 쿼리를 저장하고 있다가 엔티티 매니저가 commit() 메서드를 호출하면 저장해두었던 쿼리를 DB에 보낸다.
이를 트랜잭션을 지원하는 쓰기지연이라 한다.
public static void lazyWriting(EntityManager em) { Member memberA = new Member(); memberA.setId("memberA"); memberA.setName("회원A"); em.persist(memberA); Member memberB = new Member(); memberB.setId("memberB"); memberB.setName("회원B"); em.persist(memberB); System.out.println("persist()를 호출한다고 바로 INSERT가 실행되지 않는다."); }

결과를 보면 INSERT 쿼리보다 sysout()이 먼저 출력되었다.
위 코드에서 em.persist(memberA);를 하면 INSERT SQL이 생성되어 "쓰기 지연 저장소"에 저장된다
마찬가지로 em.persist(memberB);를 하면 INSERT SQL이 생성되어 "쓰기 지연 저장소"에 저장된다.
이렇게 계속 변경이 일어나면 SQL을 생성하여 쓰기 지연 저장소에 저장했다가, 트랜잭션이 커밋되는 순간 한번에 DB에 전송한다.
이로써 persist() 메서드가 호출되었을 때 바로 DB에 저장되는 것이 아니라는 것을 알 수 있다.
이 과정을 그림으로 그려보면 다음과 같다.
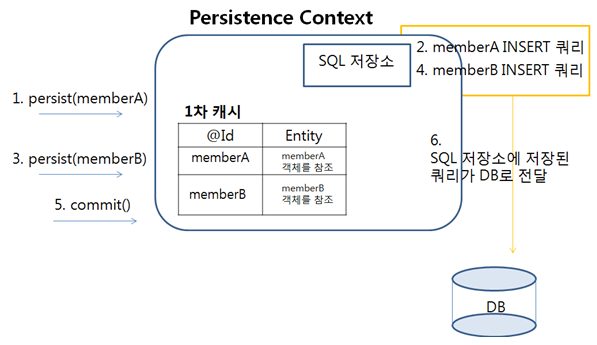
JPA가 쓰기 지연을 지원하는 이유는 쿼리를 모아 두었다가 한 번에 DB로 보내면 성능을 높일 수 있기 때문이다.
엔티티 매니저가 commit() 메서드를 호출하면 persistence context의 변경 내용을 DB에 동기화 하는 flush 작업이 이루어진다.
즉, 쓰기 지연 SQL 저장소에 모인 쿼리를 DB에 보내는 작업이 이루어지고 동기화가 되면 commit이 되어 DB에 물리적이고 영구적으로 반영된다.
웹에서는 이 과정을 @Transactional 어노테이션을 추가하여 해결한다.
즉 , 메서드가 종료되었을 때 엔티티 매니저가 commit() 메서드를 실행한다고 생각하면 된다.
4. 변경 감지 (Dirty Checking)
1차 캐시에 존재하는 엔티티에 대해서, setter를 이용해 필드 값을 수정하면 UPDATE가 이루어진다.
엔티티 매니저는 find( 조회 ), persist( 추가 ), remove( 삭제 )와 달리, 따로 update() 메서드는 존재하지 않는데 그 이유는 변경 감지( dirty checking )를 하기 때문이다.
변경 감지가 가능한 이유는 엔티티가 1차 캐시 최초 저장될 때 본래 엔티티가 아니라, 엔티티에 대한 참조와 이 엔티티를 처음 영속 상태로 만들었을 때의 복사본(Snapshot)을 가지고 있기 때문이다.
※ 참고
1차캐시 저장소에서 영속성 컨텍스트는 엔티티를 엔티티의 @id 값으로 구별한다. 만약 같은 아이디를 가지는 다른 엔티티 인스턴스가 있더라도 같은 엔티티로 취급하게 된다.
이를 스냅샷이라고 하는데, persistence context와 DB 사이의 동기화가 이루어지는 flush 시점에서 스냅샷과 현재 엔티티의 상태를 비교하여 엔티티가 변경되었다면 UPDATE 쿼리를 실행한다.
변경 감지는 managed 상태에 있는 엔티티에 대해서만 적용되므로, managed 상태가 아닌 엔티티는 칼럼 값을 변경해도 DB에 반영되지 않는다.
public static void dirtyChecking(EntityManager em) { Member member = new Member(); member.setId("member1"); member.setName("회원1"); em.persist(member); member.setName("회원2"); }
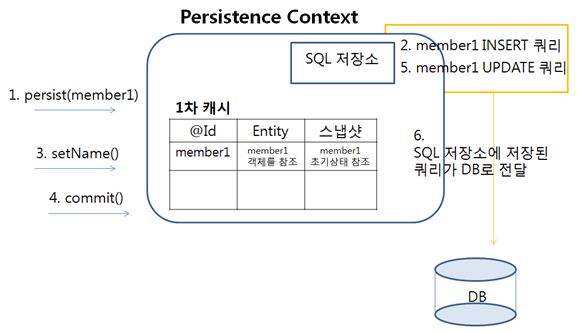
commit 하는 순간에 변경 감지를 실행하며, 변경이 감지되면 UPDATE SQL을 SQL 저장소에 저장한 후에, flush 한다.
'플러시 flush()'가 호출되고 실행하기 직전에, 엔티티 매니저는 복사본(Snapshot)과 실제 엔티티를 비교한다. 만약 저장 해둔 복사본과 실제 엔티티를 대조했을 때, 내용이 다르다면 (필드값이 다르다면) 엔티티 매니저는 '변경을 감지' 할 수 있다. 이 경우 적절한 UPDATE 문을 생성하고 플러시와 함께 쿼리문을 던져준다.
중요한 것은 "커밋되는 시점"에 "엔티티와 스냅샷을 비교"한다는 것이다.
당연하게도 변경감지는 영속성 컨텍스트에서 관리하는 엔티티만을 대상으로 진행된다. 준영속 상태인 엔티티가 변경된다고 하더라도 변경감지는 발생하지 않는다.
코드를 통해 살펴보겠다.
EntityTransaction transaction = em.getTransaction(); transaction.begin();//트랜잭션 시작 //엔티티 조회 -> 영속화 Member memberA = em.find(Member.class, 1L);//이 시점에 username="신동훈", age=22 memberA.setUsername("바보"); System.out.println(memberA.getUsername());//바보 출력 memberA.setUsername("신동훈"); System.out.println(memberA.getUsername());//신동훈 출력 transaction.commit();//트랜잭션 커밋
위 코드를 실행하면 update 쿼리는 발생하지 않다.
즉 하나의 트랙잭션 내에서는 엔티티를 어떻게 수정하여 사용하건 상관없이, 트랜잭션이 커밋되는 시점의 엔티티의 상태와 스냅샷을 비교하여 반영된다는 것이다.

JPA가 수행하는 UPDATE 쿼리를 살펴보면 엔티티의 모든 필드에 대해서 업데이트가 이루어지는 것을 볼 수 있다.
즉 수정한 것은 name 필드이지만, age라는 필드가 있을 경우 age 필드까지 UPDATE를 수행한다.
JPA에서 UPDATE 쿼리는 이와 같이 어떤 값이 변경되든 상관없이 쿼리가 항상 고정되어 있다.
이렇게 쿼리를 고정 시킴으로써 얻을 수 있는 장점은 UPDATE 쿼리를 미리 생성해둘 수 있으므로 재사용이 가능하며, DB 입장에서 동일한 쿼리를 보낼 경우 한 번 파싱된 쿼리를 재사용 할 수 있다는 점이다.
그런데 모든 필드를 UPDATE 하면 데이터 전송량이 증가한다는 단점이 존재하지만, 얻을 수 있는 이점이 더 크므로 모든 필드를 업데이트 하는 전략을 기본 값으로 한다.
모든 필드가 변경되는 것이 싫다면 엔티티를 정의할 때 @DynamicUpdate 어노테이션을 추가하면 실제로 UPDATE 되는 필드에 대해서만 UPDATE를 수행한다.
5. 삭제 ( remove )
엔티티 매니저가 remove() 메서드를 호출하면 쓰기 지연 SQL 저장소에 쿼리를 저장하고 있다가 flush가 되었을 때,
persistence context에서 엔티티를 삭제하고 DB에서도 해당 데이터를 삭제한다.
public static void remove(EntityManager em) { Member memberA = em.find(Member.class, "memberA"); em.remove(memberA); }
6. 플러쉬 ( Flush )
flush란 persistence context의 변경 내용을 DB에 동기화 하는 작업을 말한다.
INSERT , UPDATE , DELETE 할 때 flush를 수행한다.
flush는 다음의 동작으로 이루어진다.
- 변경 감지를 통해 수정된 엔티티를 찾는다.
- 수정된 엔티티가 있다면 UPDATE 쿼리를 persistence context에 있는 SQL 저장소에 등록한다.
- 쓰기 지연 SQL 저장소의 쿼리( 추가, 삭제, 수정 )를 모두 DB에 보냄으로써 동기화를 한다.
그렇다면 언제 flush가 될까?
- 엔티티 매니저가 직접 호출 ( em.flush() )
- 트랜잭션이 commit() 호출 할 때 자동으로 호출
- JPQL 쿼리 실행 전에 자동으로 호출
1번 방식은 강제로 flush 하도록 호출하는 것이기 때문에 당연하며, 2번 방식은 지금까지 알아보았던 방식이다.
그래서 3번 방식에 대해서만 알아보도록 하겠다.
JPQL 쿼리 실행 전에 flush가 호출
public static void flushBeforeJQPL(EntityManager em) { Member user1 = new Member(); user1.setId("user1"); user1.setName("유저1"); em.persist(user1); Member user2 = new Member(); user2.setId("user2"); user2.setName("유저2"); em.persist(user2); String jpql = "SELECT m FROM Member m"; TypedQuery<member> query = em.createQuery(jpql, Member.class); // SELECT 쿼리 수행 // 쿼리 실행 전에 flush가 수행되어 위의 두 엔티티를 persist하는 INSERT가 실행된다. List<member> memberList = query.getResultList(); for( Member member : memberList) { System.out.println(member.getName()); } }

원래 대로라면 persist() 메서드는 엔티티가 바로 DB에 추가되는 것이 아니라 commit() 메서드가 호출되었을 때 DB에 반영된다.
그래서 콘솔 창에 유저1과 유저2가 먼저 출력이 된 후에, INSERT 쿼리가 실행되어야 하지만 중간에 JPQL로 엔티티를 조회하는 코드가 있기 때문에 조회를 하기 전에 flush가 한 번 일어나는 것을 확인할 수 있다.
7. 준영속 ( Detached )
엔티티 매니저는 detach() 메서드를 호출하여 엔티티를 영속 상태(managed)에서 준영속 상태(detached)로 만다.
준영속 상태가 되면 persistence context에 있는 1차 캐시, 쓰기 지연 SQL에 저장된 쿼리들을 제거하기 때문에 엔티티 매니저는 더 이상 해당 엔티티를 관리하지 않는다.
또한 detach() 메서드 뿐만 아니라 clear() 메서드( em.clear() )를 호출하여 persistence context에 있는 모든 엔티티들을 준영속 상태로 만들 수 있고, close() 메서드를 호출하면 persistence context를 아예 사용하지 못하게 종료 시켜버린다.
특징
- 거의 비영속 상태에 가까움
- 비영속 상태는 식별자 값이 없을 수도 있지만, 준영속 상태는 한 번 영속 상태가 된 것이기 때문에 식별자 값이 반드시 존재
- 지연 로딩을 할 수 없음 ( 지연 로딩이란 엔티티가 실제로 사용될 때, 즉 필요할 때 그제서야 로딩이 되는 방식을 의미한다. )
public static void detached(EntityManager em) { Member userA = new Member(); // 1. Entity 생성 - 비영속 상태( new ) userA.setId("userA"); userA.setName("유저A"); em.persist(userA); // 2. 영속 상태( managed ) em.detach(userA); // 3. persistence context에서 분리 - 준영속 상태( detached ) }
persist() 메서드를 호출 했음에도, 준영속 상태이므로 DB에 반영되지 않는다. ( INSERT가 출력 되지를 않으니 수행되는 쿼리를 확인할 수 없다. )
public static void clearAndClose(EntityManager em) { // persistence context 초기화 em.clear(); // persistence context 종료 em.close(); }
detach()는 특정 엔티티를 준영속 상태로 만들지만, clear()는 영속 상태에 있는 모든 엔티티를 준영속 상태로 만든다.
즉, 1차 캐시 및 SQL 저장소를 초기화 한다고 생각하면 된다. 또한 close()는 persistence context 자체를 제거한다.
8. merge
detached 상태를 다시 영속상태로 변경하려면 병합( merge )을 해야 한다.
detached 상태에서는 필드 값을 변경하여도 DB에 반영이 되지 않지만, 필드 값을 변경 한 후 merge를 하면 그 엔티티는 managed 상태가 되므로 변동 감지가 이루어지고, commit() 메서드를 호출할 때 변경 내용이 DB에 반영된다.
정확히는 merge() 메서드의 결과로 detached 상태인 엔티티가 managed 상태로 변경되는 것이 아니라, managed 상태인 새로운 엔티티를 반환한다.
즉, merge() 메서드를 호출할 때 넘겨준 엔티티는 여전히 detached 상태에 있다.
그리고 merge() 메서드를 호출할 때 넘겨준 엔티티의 값을 새로운 엔티티의 값으로 채워 넣는다.
public class App { private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpatest"); public static void main(String[] args) { Member member = createMember("user0", "멤버1"); // 준영속 상태에서 데이터 변경 member.setName("멤버2"); mergeMember(member); } public static Member createMember(String id, String name) { /*** 영속성 컨텍스트 시작 ***/ EntityManager em = emf.createEntityManager(); EntityTransaction tx = em.getTransaction(); tx.begin(); // 엔티티 생성 - 비영속 상태 ( new ) Member member = new Member(); member.setId(id); member.setName(name); // 영속 상태 ( managed ) em.persist(member); // flush 및 commit 수행 tx.commit(); // member 엔티티는 준영속 상태가 된다. em.close(); /*** 영속성 컨텍스트 종료 ***/ // 준영속 엔티티를 반환 return member; } public static void mergeMember(Member member) { /*** 영속성 컨텍스트 시작 ***/ EntityManager em = emf.createEntityManager(); EntityTransaction tx = em.getTransaction(); tx.begin(); // 비영속 상태인 엔티티를 merge하여 새로운 영속상태 객체를 반환 Member mergedMember = em.merge(member); // flush 및 commit 수행 tx.commit(); System.out.println("memberName : " + member.getName()); System.out.println("mergedMemberName : " +mergedMember.getName()); // Entity Manager가 member와 mergedMember 엔티티를 갖고 있는지 확인 System.out.println("em contains member : " +em.contains(member)); System.out.println("em contains mergedMember : " +em.contains(mergedMember)); em.close(); /*** 영속성 컨텍스트 종료 ***/ } }

출력 결과를 보시면 meber 객체는 entity manager가 관리하고 있지 않지만, mergedMember 객체는 entity manager가 관리하고 있다는 것을 알 수 있다.
예상 면접 질문 및 답변
Q. JPA 영속성 컨텍스트의 이점(5가지)을 설명해주세요.
영속성 컨텍스트는 엔티티를 영구 저장하는 환경을 의미합니다.
영속성 컨텍스트를 쓰는 이유는 1차 캐시, 동일성 보장, 쓰기 지연, 변경감지(Dirty checking), 지연로딩이 있습니다.
- 1차 캐시: 조회가 가능하며 1차 캐시에 없으면 DB에서 조회하여 1차 캐시에 올려 놓습니다.
- 동일성 보장: 동일성 비교가 가능합니다.(==)
- 쓰기 지연: 트랜잭션을 지원하는 쓰기 지연이 가능하며 트랜잭션 커밋하기 전까지 SQL을 바로 보내지 않고 모아서 보낼 수 있습니다.
- 변경 감지(Dirty checking): 스냅샷을 1차 캐시에 들어온 데이터를 찍습니다. commit 되는 시점에 Entity와 스냅샷과 비교하여 update SQL을 생성합니다.
- 지연 로딩: 엔티티에서 해당 엔티티를 불러올 때 그 때 SQL을 날려 해당 데이터를 가져옵니다.
Q. JPA를 쓴다면 그 이유에 대해서 설명해주세요.
사실 면접관이 의도한 바를 파악하는게 중요합니다. 각기 다른 조건에서 같은 질문을 들었을 때 대답을 다르게 했던 기억이 납니다.
제가 JPA를 사용하는 이유는 객체지향 프레임워크이기 때문입니다. JPA를 사용하면 비즈니스 로직이 RDBMS에 의존하는 것이 아니라, 자바 코드로 표현될 수 있기 때문입니다. 그로 인해서 생산성이 높아진다고 볼 수 있습니다.(이는 JPA에 익숙하다는 것을 전제로 합니다.)
또, JPA는 JPQL로 SQL을 추상화하기 때문에 RDBMS Vendor에 관계없이 동일한 쿼리를 작성해서 같은 동작을 기대할 수 있다는 장점도 가지고 있습니다. 이는 database dialect를 지원하기 때문에 가지는 장점입니다.
참고
- https://siyoon210.tistory.com/138
- https://ttl-blog.tistory.com/108
- https://velog.io/@neptunes032/JPA-%EC%98%81%EC%86%8D%EC%84%B1-%EC%BB%A8%ED%85%8D%EC%8A%A4%ED%8A%B8%EB%9E%80
- https://incheol-jung.gitbook.io/docs/q-and-a/spring/persistence-context#undefined
- https://code-lab1.tistory.com/290
- https://victorydntmd.tistory.com/207
- 엔티티 매니저 팩토리 & 엔티티 매니저
- 영속성 컨텍스트(Persistence Context)
- 엔티티의 생명주기
- 비영속
- 영속
- 준영속
- 삭제
- 영속성 컨텍스트가 엔티티를 관리하면 얻게되는 장점
- 1. 1차 캐시
- 2. 동일성 보장
- 3. 쓰기 지연 ( transaction write behind )
- 4. 변경 감지 (Dirty Checking)
- 5. 삭제 ( remove )
- 6. 플러쉬 ( Flush )
- 7. 준영속 ( Detached )
- 8. merge
- 예상 면접 질문 및 답변
- Q. JPA 영속성 컨텍스트의 이점(5가지)을 설명해주세요.
- Q. JPA를 쓴다면 그 이유에 대해서 설명해주세요.