자바에서는 대표적으로 문자열을 다루는 자료형 클래스로 String, StringBuffer, StringBuilder 라는 3가지 자료형을 지원한다.
위 3가지 클래스 자료형은 모두 문자열을 다루는데 있어 공통적으로 사용되지만, 사용 목적에 따라 쓰임새가 많이 달라지게 된다.
이번 포스팅에서는 String, StringBuffer, StringBuilder 클래스 차이점을 알아보고, 이 3가지가 어떤 상황에서 어느 자료형을 사용하는 것이 이상적이고 성능적으로는 어떤 차이가 있는지 알아보고자 한다.
StringBuffer / StringBuilder 클래스
StringBuffer / StringBuilder 클래스는 문자열을 연산(추가하거나 변경) 할 때 주로 사용하는 자료형이다.
물론 String 자료형만 으로도, + 연산이나 concat() 메소드로 문자열을 이어붙일수 있다.
하지만 덧셈(+) 연산자를 이용해 String 인스턴스의 문자열을 결합하면, 내용이 합쳐진 새로운 String 인스턴스를 생성하게 되어, 따라서 문자열을 많이 결합하면 결합할수록 공간의 낭비뿐만 아니라 속도 또한 매우 느려지게 된다는 단점이 있다.
String result = "";
result += "hello";
result += " ";
result += "jump to java";
System.out.println(result); // hello jump to java
// → 심플하지만 연산 속도가 느리다는 단점이 있다그래서 자바에서는 이러한 문자열 연산을 전용으로 하는 자료형을 따로 만들어 제공해준다.
StringBuffer 클래스는 내부적으로 버퍼(buffer)라고 하는 독립적인 공간을 가지게 되어, 문자열을 바로 추가할 수 있어 공간의 낭비도 없으며 문자열 연산 속도도 매우 빠르다는 특징이 있다.
StringBuffer sb = new StringBuffer(); // StringBuffer 객체 sb 생성
sb.append("hello");
sb.append(" ");
sb.append("jump to java");
String result = sb.toString();
System.out.println(result); // hello jump to java
// → + 연산보다는 복잡해 보이지만 연산 속도가 빠르다는 장점이 있다※ 참고
StringBuffer와 비슷한 자료형으로 StringBuilder 자료형이 있다. StringBuilder 사용법은 StringBuffer와 동일하다.
StringBuffer와 StringBuilder의 차이는, StringBuffer는 멀티 스레드 환경에서 안전하다는 장점이 있고, StringBuilder는 문자열 파싱 성능이 가장 우수하다는 장점이 있다.
기본적으로 StringBuffer의 버퍼(데이터 공간) 크기의 기본값은 16개의 문자를 저장할 수 있는 크기이며, 생성자를 통해 그 크기를 별도로 설정할 수도 있다.
만일 문자열 연산중에 할당된 버퍼의 크기를 넘게 되면 자동으로 버퍼를 증강시킨다. 다만, 효율이 떨어질 수 있으므로 버퍼의 크기는 넉넉하게 잡는 것이 좋다.
StringBuffer sb = new StringBuffer(); // 기본 16 버퍼 크기로 생성
// sb.capacity() - StringBuffer 변수의 배열 용량의 크기 반환
System.out.println(sb.capacity()); // 16
sb.append("1111111111111111111111111111111111111111"); // 40길이의 문자열을 append
System.out.println(sb.capacity()); // 40 (추가된 문자열 길이만큼 늘어남)
String vs (StringBuffer, StringBuilder) 비교
문자열 자료형의 불변과 가변
String은 불변
기본적으로 자바에서는 String 객체의 값은 변경할 수 없다.
이는 한번 할당된 공간이 변하지 않는다고 해서 '불변(immutable)' 자료형 이라고 불린다. 그래서 초기공간과 다른 값에 대한 연산에서 많은 시간과 자원을 사용하게 된다는 특징이 있다.
실제로 String 객체의 내부 구성 요소를 보면 다음과 같다.
인스턴스 생성 시 생성자의 매개변수로 입력받는 문자열은 이 value 라는 인스턴스 변수에 문자형 배열로 저장되게 된다. 이 value 라는 변수는 상수(final)형이니 값을 바꾸지 못하는 것이다.
JDK 8
public final class String implements java.io.Serializable, Comparable {
private final byte[] value;
}
~JDK 9
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
@Stable
private final byte[] value;
...
}※ 참고
JDK 8 까지는 String 객체의 값은 char[] 배열로 구성되어져 있지만, JDK 9부터 기존 char[]에서 byte[]을 사용하여 String Compacting을 통한 성능 및 heap 공간 효율(2byte -> 1byte)을 높이도록 수정되었다.
아래 예제에서 알 수 있듯이 hashCode가 달라지므로 두 객체는 다른 객체가 된다. 그런데, 반복적으로 문자열을 이어 붙이다 보면 Heap 영역에서 참조를 잃은 문자열 객체가 계속해서 쌓이게 된다. 물론, 나중에 GC에 의해 수거가 되지만 메모리 관리 측면에서 이러한 코드는 결코 좋은 코드라고 할 수 없다. 또한 계속해서 객체를 생성하므로 연산 속도 측면에서도 성능이 떨어질 수 밖에 없다.
String s = "hello";
System.out.println(s.hashCode()); // 99162322
s += " world";
System.out.println(s.hashCode()); // 1776255224
이외에도 문자열을 다루는데 있어 가장 많이 사용하는 trim 이나 toUpperCase 메소드 사용 형태를 보면, 문자열이 변경되는 것 처럼 생각 될 수도 있지만 해당 메소드 수행 시 또 다른 String 객체를 생성하여 리턴할 뿐이다
String sql = "abc"; // "abc"
sql.toUpperCase(); // "ABC"
System.out.println(sql); // "abc" - toUpperCase를 해도 자체 문자열은 변경되지 않는다 (불변)[ 자바 언어에서 String을 불변으로 설정한 이유 ]
String 객체를 불변하게 설계한 이유는 캐싱, 보안, 동기화, 성능측면 이점을 얻기 위해서이다.
1. 캐싱 : String을 불변하게 함으로써 String pool에 각 리터럴 문자열의 하나만 저장하며 다시 사용하거나 캐싱에 이용가능하며 이로 인해 힙 공간을 절약할 수 있다는 장점이 있다.
2. 보안 : 예를 들어 데이터베이스 사용자 이름, 암호는 데이터베이스 연결을 수신하기 위해 문자열로 전달되는데, 만일 번지수의 문자열 값이 변경이 가능하다면 해커가 참조 값을 변경하여 애플리케이션에 보안 문제를 일으킬 수 있다.
3. 동기화 : 불변함으로써 동시에 실행되는 여러 스레드에서 안정적이게 공유가 가능하다.
String Constants Pool

= 연산자를 통해 값을 String에 대입하면 Heap 영역 내에 있는 String Pool이라는 공간에 문자열이 저장되고, new 연산자를 통해 String을 만들면 String Pool이 아닌 일반 Heap 영역 어딘가에 저장된다. 둘다 Heap 영역에 저장되는 것은 동일한데, String Pool에 값이 저장되면 어떠한 이점이 있는 것일까?
전자의 방식을 String literal이라고 하는데, String literal로 생성한 객체는 String Pool의 메모리 주소를 가리키게 된다. 그래서 똑같은 String literal 객체가 생성될 경우 같은 값의 주소를 가리키게 되므로 하나의 메모리를 재사용할 수 있다.
반면 후자는 일반적인 new 연산자를 통해 객체를 생성하는 방식이므로 String Pool의 해당 값이 있더라도 Heap 영역 내 별도의 메모리를 할당하여 주소를 가리키게 된다.
String a = "Cat";
String b = "Cat";
String c = new String("Cat");
System.out.println(a == b); // true
System.out.println(a == c); // false위 개념을 이해한 상태로 해당 예제 코드를 보면 이해가 갈 것이다. a와 b는 String Pool의 동일한 주소를 가리키고 있고, c는 별도로 생성한 메모리의 주소를 가리키므로 서로 참조하는 주소가 다르다는 사실을 기억하자.
StringBuffer / StringBuilder 는 가변
StringBuffer나 StringBuilder의 경우 문자열 데이터를 다룬다는 점에서 String 객체와 같지만, 객체의 공간이 부족해지는 경우 버퍼의 크기를 유연하게 늘려주어 가변(mutable)적이라는 차이점이 있다.
두 클래스는 내부 Buffer(데이터를 임시로 저장하는 메모리)에 문자열을 저장해두고 그 안에서 추가, 수정, 삭제 작업을 할 수 있도록 설계되어 있다.
String 객체는 한번 생성되면 불변적인 특징 때문에 값을 업데이트하면, 매 연산 시마다 새로운 문자열을 가진 String 인스턴스가 생성되어 메모리 공간을 차지하게 되지만,
StringBuffer / StringBuilder 는 가변성 가지기 때문에 .append() .delete() 등의 API를 이용하여 동일 객체내에서 문자열 크기를 변경하는 것이 가능하다.

따라서 값이 변경될 때마다 새롭게 객체를 만드는 String 보다 훨씬 빠르기 때문에, 문자열의 추가, 수정, 삭제가 빈번하게 발생할 경우라면 String 클래스가 아닌 StringBuffer / StringBuilder를 사용하는 것이 이상적이라 말할 수 있다.
※ 참고
StringBuilder 나 StringBuffer 클래스의 사용 문법은 둘이 똑같다.
다만 내부적으로 동작 차이점 존재하는데 이에 대해선 바로 뒤에서 다룬다. 지금은 둘이 동일시로 봐도 된다.
StringBuffer의 내부구조를 보면 상수(final) 키워드가 없는것을 볼 수 있다.
public final class StringBuffer implements java.io.Serializable {
private byte[] value;
}// new StringBuffer() 인수에 아무것도 넣어주지 않으면 기본 16으로 배열 길이를 잡음
StringBuffer sb = new StringBuffer();
// sb.capacity() - StringBuffer 변수의 배열 용량의 크기 반환
System.out.println(sb.capacity()); // 16
sb.append("1111111111111111111111111111111111111111"); // 40길이의 문자열을 append
System.out.println(sb.capacity()); // 40 (추가된 문자열 길이만큼 늘어남)
아래 코드는 별* 문자를 루프문을 순회할때마다 추가해 길다란 별 문자열을 만드는 예제로, 각각 String 객체와 StringBuffer 객체를 이용했을시 차이를 보여준다.
String star = "*";
for ( int i = 1; i < 10; i++ ) {
star += "*";
}
StringBuffer sb= new StringBuffer("*");
sb.append("*********");
String 객체일 경우 매번 별 문자열이 업데이트 될때마다 계속해서 메모리 블럭이 추가되게 되고, 일회용으로 사용된 이 메모리들은 후에 Garbage Collector(GC)의 제거 대상이 되어 빈번하게 Minor GC를 일으켜 Full GC(Major Gc)를 일으킬수 있는 원인이 된다.
[JAVA] 가비지 컬렉션(Garbage Collection) 동작 원리 & GC 종류
가비지 컬렉션(Garbage Collection)이란? 가비지 컬렉션(Garbage Collection, 이하 GC)은 자바의 메모리 관리 방법 중의 하나로 JVM(자바 가상 머신)의 Heap 영역에서 동적으로 할당했던 메모리 영역 중 필요 없
s-y-130.tistory.com
반면 StringBuffer는 위 사진 처럼 자체 메모리 블럭에서 늘이고 줄이고를 할수 있기 때문에 훨씬더 효율적으로 문자열 데이터를 다룰 수 있다는 것을 볼 수 있다.
문자열 자료형의 값 비교
String 값 동등 비교
String 객체는 간단하게 equals() 메서드를 통해 문자열 데이터 동등 비교가 가능하다.
String str1 = "Hello"; // 문자열 리터럴을 이용한 방식
String str3 = new String("Hello"); // new 연산자를 이용한 방식
// 리터럴과 객체 문자열 비교
System.out.println(str1 == str3); // false
System.out.println(str3.equals(str1)); // trueStringBuffer / StringBuilder 값 동등 비교
하지만 StringBuffer/StringBuilder 클래스는 String 객체와 달리 equals() 메서드를 오버라이딩하지 않아 '==' 로 비교한 것과 같은 결과를 얻게 된다.
StringBuffer sb = new StringBuffer("hello");
StringBuffer sb2 = new StringBuffer("hello");
System.out.println(sb == sb2); // false
System.out.println(sb2.equals(sb)); // false따라서 toString() 으로 StringBuffer/StringBuilder 객체를 String 객체로 변환하고 난 뒤에 equals 로 비교를 해야 한다.
// StringBuffer객체를 toString()을 통해 String객체화를 하고 equals 비교
String sb_tmp = sb.toString();
String sb2_tmp = sb2.toString();
System.out.println(sb_tmp.equals(sb2_tmp)); // true문자열 자료형의 성능 비교
문자열 합치기 성능
자바를 개발 하다보면 문자열을 다루는데 있어, 별다른 고민없이 "Hello" + " World" 와 같이 + 기호를 통해 문자열을 이어 붙이곤 한다. 하지만 Java 개발자라면 고민을 더 해보고 문자열 관련 Class를 선택해야한다.
위에서 알아봤듯이, String 데이터를 + 연산하면 불필요한 객체들이 힙 메모리에 추가되어 안좋기 때문에 String을 직접 + 연산을 통한 문자열 합치기를 지양하고 StringBuffer나 StringBuilder의 append() 메소드를 통해 문자열 데이터를 추가하는 것이 좋다고 한다.
하지만 이는 반은 맞고 반은 틀린 말이다.
사실 자바는 문자열에 + 연산을 사용하면, 컴파일 전 내부적으로 StringBuilder 클래스를 만든 후 다시 문자열로 돌려준다고 한다.

즉, "hello" + "world" 문자열 연산이 있다면 이는 new StringBuilder("hello").append("world").toString() 과 같다는 말이다.
String a = "hello" + "world";
/* 는 아래와 같다. */
String a = new StringBuilder("hello").append("world").toString();
// StringBuilder를 통해 "hello" 문자열을 생성하고 "world"를 추가하고
// toString()을 통해 String 객체로 변환하여 반환이처럼 겉으로는 보기에는 문자열 리터럴로 + 연산하거나, StringBuilder 객체를 사용하거나 어차피 자동 변환해줘서 차이가 없어 보일지도 모른다.
하지만 다음과 같이 문자열을 합치는 일이 많을 경우 단순히 + 연산을 쓰면 성능과 메모리 효율이 떨어지게 된다.
String a = "";
for(int i = 0; i < 10000; i++) {
a = a + i;
}
/* 위의 문자열 + 연산 식은 결국 아래와 같다. */
/*
즉, 매번 new StringBuilder() 객체 메모리를 생성하고
다시 변수에 대입하는 멍청한 짓거리를 하고 있는 것이다.
*/
String a = "";
for(int i = 0; i < 10000; i++) {
a = new StringBuilder(b).append(i).toString();
}위의 예시 처럼 매번 new StringBuilder() 객체 메모리를 생성하고 다시 변수에 대입하는 짓을 반복하고 있으니 한눈에 봐도 문자열 값을 변경할 일이 잦을 경우 + 연산자를 사용하는 것은 좋지 못한 것을 알 수 있다.
따라서 만일 문자열 연산이 많을 경우 아예 처음부터 StringBuilder() 객체로 문자열을 생성해서 다루는게 훨씬 낫다.
StringBuilder a = new StringBuilder();
for(int i = 0; i < 10000; i++) {
a.append(i);
}
final String b = a.toString();
String.concat 과의 비교
자바 프로그래밍에서 문자열을 합치는데 있어 총 4가지 방법이 존재한다.
+ 연산자 또는 String.concat 메소드 이용 또는 StringBuffer 또는 StringBuilder 객체를 이용하는 방법이다.
String str = "hello ";
String a = str + "world"; // 앞서 + 연산은 자동으로 StringBuilder로 변환된다고 말했다.
String b = str.concat("world");
String c = new StringBuffer("hello").append("world").toString();
String d = new StringBuilder("hello").append("world").toString();이처럼 String 객체 자체에도 String.concat 메소드로 자체 메모리 영역에서 문자열 데이터를 변경이 가능하다.
그럼 이중에 어느 것이 성능이 좋을까? 당연히 StringBuffer 와 StringBuilder 객체이다.
String.concat 같은 경우, 이 메소드는 호출할 때마다 원본 문자열을 매번 배열을 재구성 하는 과정을 거치기 때문에 당연히 느릴 수밖에 없다. 반면 StringBuilder나 StringBuffer는 처음부터 배열 크기를 일정하게 잡고 시작하기 때문에 합치는 과정이 String.concat 보다 월등히 빠르다.

성능상에서 문자열 자료형 선택 결론
그렇다면 무조건 StringBuffer / StringBuilder를 사용하는 것이 좋을다고 맹신할수 있겠지만, 그건 상황에 따라 다르다.
StringBuffer나 StringBuilder을 생성할 경우 buffer의 크기를 초기에 설정해줘야하는데 이러한 동작으로 인해 무거운 편에 속한다. 그리고 StringBuffer나 StringBuilder에서 문자열 수정을 할 경우에도 마찬가지로 버퍼의 크기를 늘리고 줄이고 명칭을 변경해야하는 내부적인 연산이 필요하므로 많은 양의 문자열 수정이 아니라면 String 객체를 사용하는것이 오히려 나을 수 있다.
String 클래스는 크기가 고정되어 있으므로 단순하게 읽는 조회 연산에서는 StringBuffer나 StringBuilder 클래스보다 빠르게 읽을 수 있다.
따라서 정리하자면, 문자열 추가나 변경등의 작업이 많을 경우에는 StringBuffer를, 문자열 변경 작업이 거의 없는 경우에는 그냥 String을 사용하는 것만 기억하면 된다.
StringBuffer vs StringBuilder 차이점
StringBuffer와 StringBuilder 클래스는 둘 다 크기가 유연하게 변하는 가변적인 특성을 가지고 있으며, 제공하는 메서드도 똑같고 사용하는 방법도 동일하다.
그럼 이 둘의 차이점은 무엇일까? 사실 둘의 차이는 딱 한가지이다.
바로 멀티 쓰레드(Thread)에서 안전(safe)하냐 아니냐 이 차이 뿐이다.
쓰레드의 안정성

- StringBuffer 클래스는 쓰레드에서 안전하다. (thread safe)
- StringBuilder 클래스는 쓰레드에서 안전하지 않다.(thread unsafe)
두 클래스는 문법이나 배열구성도 모두 같지만, 동기화(Synchronization)에서의 지원의 유무가 다르다.
StringBuilder는 동기화를 지원하지 않는 반면, StringBuffer는 동기화를 지원하여 멀티 스레드 환경에서도 안전하게 동작할 수 있다.
그 이유는 StringBuffer는 메서드에서 synchronized 키워드를 사용하기 때문이다.
※ 참고
java에서 synchronized 키워드는 여러 개의 스레드가 한 개의 자원에 접근할려고 할 때, 현재 데이터를 사용하고 있는 스레드를 제외하고 나머지 스레드들이 데이터에 접근할 수 없도록 막는 역할을 수행한다.
글로만 보면 이게 정확히 어떤 현상인지 와닿지 않는다. 직접 StringBuilder와 StringBuffer를 코드로 테스트 해보자.
아래의 예제는 StringBuilder와 StringBuffer 객체를 선언하고, 두개의 멀티 쓰레드를 돌려 StringBuilder와 StringBuffer 객체에 각각 1 요소를 1만번 추가하는(append) 로직을 수행한 코드이다.
두개의 쓰레드가 있고 한개의 쓰레드에서 배열요소를 1만번 추가하니 문자열 배열의 길이는 20000이 된다고 유추할 수 있다.
import java.util.*;
public class Main extends Thread{
public static void main(String[] args) {
StringBuffer stringBuffer = new StringBuffer();
StringBuilder stringBuilder = new StringBuilder();
new Thread(() -> {
for(int i=0; i<10000; i++) {
stringBuffer.append(1);
stringBuilder.append(1);
}
}).start();
new Thread(() -> {
for(int i=0; i<10000; i++) {
stringBuffer.append(1);
stringBuilder.append(1);
}
}).start();
new Thread(() -> {
try {
Thread.sleep(2000);
// thread safe 함
System.out.println("StringBuffer.length: "+ stringBuffer.length());
// thread unsafe 함
System.out.println("StringBuilder.length: "+ stringBuilder.length());
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}StringBuffer.length: 20000
StringBuilder.length: 19628하지만 위의 결과를 보면 다른 값이 나온 것을 확인할 수 있다.
StringBuilder의 값이 더 작은 것을 볼 수 있는데, 이는 쓰레드들이 동시에 StringBuilder 클래스에 접근하여 동시에 append() 를 수행하다 제대로 수행이 안되어 일어난 결과라고 보면 된다.
StringBuilder는 Thread safe 하지 않아서 각기 다른 쓰레드가 객체에 접근해서 변경을 하면 기다려주지 않기 때문에 이러한 현상이 발생한 것이다.
이와 달리 StringBuffer는 멀티 쓰레드(multi thread)환경에서, 한 쓰레드가 append() 를 수행하고 있을경우 다른 쓰레드가 append() 를 수행을 동시에 하지못하도록 잠시 대기를 시켜주고 순차적으로 실행하게 한다. 이처럼 동시에 접근해 다른 값을 변경하지 못하도록 하므로 Thread Safe로서 정상적으로 2만개의 배열요소가 추가된 것이다.
그래서 web이나 소켓환경과 같이 비동기로 동작하는 경우가 많을 때는 StringBuffer를 사용하는 것이 안전하다는 것을 알수가 있다.
StringBuffer
StringBuffer는 대부분의 메소드에 synchronized가 적용되어 일반적으로 멀티 스레드 환경에서 스레드 안전하게 동작한다. 한마디로 동기화를 지원하는 StringBuilder라고 생각하면 된다.
@Override
public synchronized StringBuffer append(CharSequence s) {
toStringCache = null;
super.append(s);
return this;
}다만 무식하게 모든 메소드에 대해 synchronized를 통해 blocking을 거는 것은 성능 상으로 좋지 않다. 또한 synchronized 메소드 하나를 여러 스레드가 호출하는 것은 스레드 안전한 것이 맞지만, 여러 synchronized 메소드로 이루어진 하나의 메소드를 여러 스레드가 호출할 때는 스레드 안전하지 않을 수 있다. 아래 예시를 보자.
public class StringBufferTest {
private static final StringBuffer sb = new StringBuffer();
public static void main(String[] args) throws InterruptedException {
String[] names = {"A", "B", "C", "D", "E", "F", "G", "H", "I", "J"};
String[] values = {"a", "b", "c", "d", "e", "f", "g", "h", "i", "j"};
for (int i = 0; i < 10; i++) {
final int j = i;
Thread thread = new Thread(() -> addProperty(names[j], values[j]));
thread.start();
}
new Thread(() -> System.out.println(sb.toString())).start();
}
public static void addProperty(String name, String value) {
if (value != null && value.length() > 0) {
if (sb.length() > 0) {
sb.append(',');
}
sb.append(name).append('=').append(value);
}
}
}위 코드에서 addProperty() 는 StringBuffer의 synchronized 처리 된 length() 메소드와 append() 메소드를 혼합하여 사용하고 있고, 총 10개의 스레드가 addProperty() 메소드를 호출하고 있다.
개발자가 의도한 방식은 사전 순으로 “A=a, B=b, ...”는 아니더라도, 적어도 “A=a, C=c, ...” 처럼 알파벳 간을 콤마(,)로 나누고 싶어할 것이다. (사용자의 컴퓨터 환경에 따라 동기화 문제가 발생하지 않을 수 있다는 점을 주의하라.)
C=c,J=j,A=a,H=h,G=g,,E=Be=b,F=f,D=d,I=i하지만 중간에 콤마(,)가 두 번 들어간 것을 확인할 수 있다. 이것이 발생하는 예상 시나리오는 아래와 같다.
- 1번 스레드가 sb.length() 를 호출하였고, 나머지 스레드는 모두 blocked 상태가 되었다.
- 그런데, 이미 StringBuffer에는 특정 문자가 들어가 있어서 1번 스레드는 조건문을 만족하여 sb.append() 를 호출하려고 하였으나, 그 찰나에 순간에 2번 스레드가 조건문 아래에 있는 sb.append() 를 호출하였다.
- 그러면 StringBuffer에는 콤마가 들어가기도 전에 다른 문자가 들어가게 된다.
- 2번 스레드의 작업을 마치면 1번 스레드가 sb.append() 를 호출하여 콤마를 StringBuffer에 집어 넣게 된다.
위 시나리오는 해당 예제의 결과 값에서 E=Be=b 를 나타낸 것이다. 이 결과는 심지어 대문자와 소문자 쌍까지도 맞지 않는 심각한 동기화 문제가 발생하였다.
따라서 해당 addProperty() 를 스레드 안전하게 사용하려면 아래와 같이 synchronized 블럭을 사용해야 한다.
public class Main {
private static final StringBuffer sb = new StringBuffer();
public static void main(String[] args) {
String[] names = {"A", "B", "C", "D", "E", "F", "G", "H", "I", "J"};
String[] values = {"a", "b", "c", "d", "e", "f", "g", "h", "i", "j"};
for (int i = 0; i < 10; i++) {
final int j = i;
Thread thread = new Thread(() -> addProperty(names[j], values[j]));
thread.start();
}
new Thread(() -> System.out.println(sb.toString())).start();
}
public static void addProperty(String name, String value) {
synchronized (sb) {
if (value != null && value.length() > 0) {
if (sb.length() > 0) {
sb.append(',');
}
sb.append(name).append('=').append(value);
}
}
}
}위와 같이 synchronized 블럭을 사용하면 블럭 내에 있는 연산에 대해 원자성을 보장해 줄 수 있으므로 스레드 안전하게 작업을 진행할 수 있다.
정리하자면, StringBuffer는 단일 synchronized 메소드를 여러 스레드가 사용하는 것은 스레드 안전하지만, 단일 synchronized 메소드 여러 개로 구성된 일반 메소드에서 사용할 때는 스레드 안전하지 않으므로 주의하여 사용해야 한다.
이러한 이유로 Vector는 이미 레거시 클래스가 되어 Concurrent 라이브러리를 사용하는 컬렉션으로 대체가 되었지만, StringBuffer의 대체재는 찾지 못하였다.
순수 성능 비교
그럼 순수하게 이 두 클래스의 성능은 누가 우월할까?
다음은 String 객체 그리고 StringBuffer와 StringBuilder 객체를 선언하고 5만번을 루프해 별문자 * 를 추가하는 로직이다. 그리고 각 문자열 연산을 실행하는 시간을 duration1, duration2, duration3 변수에 계산해 저장한다.
final int lengths = 50000;
// ------------- (1) String의 +연산을 이용해서 50,000개의 *를 이어 붙인다.
long startTime1 = System.currentTimeMillis(); // 시작시간을 기록 (millisecond단위)
String str="";
for(int i=0;i<lengths;i++){
str=str+"*";
}
long endTime1 = System.currentTimeMillis(); // 종료시간을 기록(millisecond단위)
// ------------- (2) StringBuffer를 이용해서 50,000개의 *를 이어붙인다.
long startTime2 = System.currentTimeMillis();
StringBuffer sb = new StringBuffer();
for(int i=0;i<lengths;i++){
sb.append("*");
}
long endTime2 = System.currentTimeMillis();
// ------------- (3) StringBuilder를 이용해서 50,000개의 *를 이어붙인다.
long startTime3 = System.currentTimeMillis();
StringBuilder sb2 = new StringBuilder();
for(int i=0;i<lengths;i++){
sb2.append("*");
}
long endTime3 = System.currentTimeMillis();
// ------------- 방법(1), 방법(2), 방법(3)가 걸린 시간을 비교
long duration1 = endTime1 - startTime1;
long duration2 = endTime2 - startTime2;
long duration3 = endTime3 - startTime3;
System.out.println("String의 +연산을 이용한 경우 : "+ duration1); // 559
System.out.println("StringBuffer의 append()을 이용한 경우 : "+ duration2); // 10
System.out.println("StringBuilder의 append()을 이용한 경우 : "+ duration3); // 3String의 +연산을 이용한 경우 : 559
StringBuffer의 append()을 이용한 경우 : 10
StringBuilder의 append()을 이용한 경우 : 3문자열 연산 수행 시간 결과를 보면, 기본 성능은 StringBuilder 클래스가 우월하다는 것을 알 수 있다.
위에서 살펴보았던 String의 + 연산 시, 컴파일 전에 StringBuilder 로 변환해주는 이유가 바로 이것이다.
이는 조금만 생각해보면 당연한 결과이다.
StringBuffer와 StringBuilder 의 차이는 쓰레드 안정성에 있다고 학습했는데, 아무래도 쓰레드 안전성을 버린 StringBuilder가 좀더 덜 따지고 연산을 하니 당연히 좀 더 빠를 수 밖에 없다.
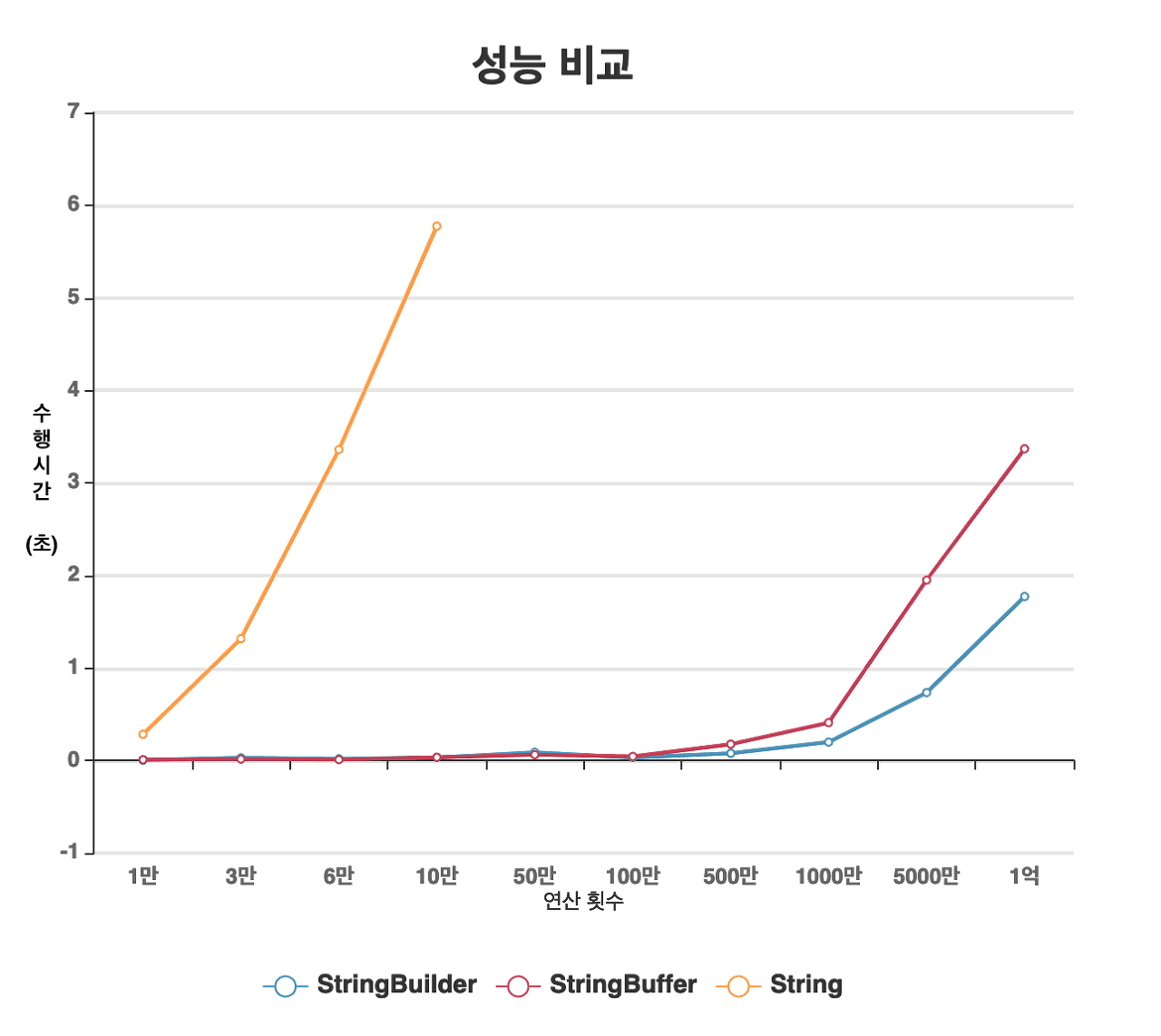
위 그래프를 보면 10만번 이상의 연산시 String 객체는 수행시간이 기하급수적으로 늘어나지만, StringBuilder와 StringBuffer는 1000만번까지 버티며, 그 이상은 StringBuilder가 우월하다는 것을 볼 수 있다.
그래서 만약 싱글 쓰레드 환경에서나 비동기를 사용할 일이 없으면, StringBuilder를 쓰는 것이 이상적이라 할 수 있다.
하지만 현업에서는 자바 어플리케이션을 대부분 멀티 스레드 이상의 환경에서 돌아가기 때문에 왠만하면 안정적인 StringBuffer로 통일하여 코딩하는것이 좋다. (솔직히 StringBuffer 와 StringBuilder 속도 차이는 거의 미미하다)
문자열 자료형 비교 총정리
| String | StringBuffer | StringBuilder | |
| 가변 여부 | 불변 | 가변 | 가변 |
| 스레드 세이프 | O | O | X |
| 연산 속도 | 느림 | 빠름 | 아주 빠름 |
| 사용 시점 | 문자열 추가 연산이 적고, 스레드 세이프 환경에서 |
문자열 추가 연산이 많고, 스레드 세이프 환경이서 |
문자열 추가 연산이 많고, 빠른 연산이 필요한 경우 단일 스레드 환경일 경우 |
String 을 사용해야 할 때 :
- String은 불변성
- 문자열 연산이 적고 변하지 않는 문자열을 자주 사용할 경우
- 멀티쓰레드 환경일 경우
StringBuilder 를 사용 해야 할 때 :
- StringBuilder는 가변성
- 문자열의 추가, 수정, 삭제 등이 빈번히 발생하는 경우
- 동기화를 지원하지 않아, 단일 쓰레드이거나 동기화를 고려하지 않아도 되는 경우
- 속도면에선 StringBuffer 보다 성능이 좋다.
StringBuffer 를 사용해야 할 때 :
- StringBuffer는 가변성
- 문자열의 추가, 수정, 삭제 등이 빈번히 발생하는 경우
- 동기화를 지원하여, 멀티 스레드 환경에서도 안전하게 동작
예상 면접 질문 및 답변
Q. String Pool에 대해 설명하라.
String Pool은 Java Heap 영역에 존재하는 String 저장소로, String literal을 보관한다.
Q. String Pool이 있으면 무엇이 좋은가?
= 연산자로 String을 생성할 때, 같은 값이 String Pool에 있다면, 새로운 메모리 할당 없이 주소를 공유하여 사용할 수 있다. 또한, String은 불변 객체이므로 동일한 주소를 여러 객체가 참조하여도 동기화 문제가 발생하지 않으므로 안전하다.
Q. String과 StringBuilder의 차이는?
String은 불변 객체이므로 + 연산으로 문자열을 이어 붙이려고 해도 매번 새로운 객체를 할당해야 한다. 하지만, StringBuilder는 가변 객체이고 내부 char[] 배열의 사이즈를 조절하여 문자열을 이어 붙이기 때문에 새로운 객체를 최소로 할당할 수 있다.
Q. StringBuilder와 StringBuffer의 차이는?
StringBuilder는 동기화 처리가 되어 있지 않아 스레드 불안전하지만, StringBuffer는 대부분의 메소드에 대해 synchronized 처리가 되어 있으므로 일반적으로 스레드 안전하다.
Q. StringBuffer가 일반적으로 스레드 안전하다는 것은 무슨 뜻인가?
StringBuffer는 단일 synchronized 메소드를 여러 스레드가 사용하는 것은 스레드 안전하지만, 단일 synchronized 메소드 여러 개로 구성된 일반 메소드에서 사용할 때는 스레드 안전하지 않다. (자세한 예시는 본문 참조)
참고
- https://stackoverflow.com/questions/32714194/where-is-implemented-for-strings-in-the-java-source-code
- https://dejavuhyo.github.io/posts/string-stringbuffer-stringbuilder/
- https://venishjoe.net/post/java-string-concatenation-and-performance/
- https://madplay.github.io/post/difference-between-string-stringbuilder-and-stringbuffer-in-java
- https://wikidocs.net/276
- https://velog.io/@minnseong/String