해당 포스팅은 '힙'과 '우선순위 큐'에 대한 학습 자료다.
힙과 우선순위 큐를 한 포스팅에 담은 이유는 '우선순위 큐'가 바로 힙 자료구조를 이용하여 구현되기 때문이다.
자료 구조 힙(Heap)이란?
힙은 '최솟값 또는 최댓값을 빠르게 찾아내기 위해 완전이진트리 형태로 만들어진 자료구조'다.
위 문장에서 중요한 키워드 3가지가 있다. 바로 '최솟값 또는 최댓값' , '빠르게', '완전이진트리' 이다. 일단 이 키워드를 이해하기 위해서는 '완전이진트리'를 이해해야 한다.
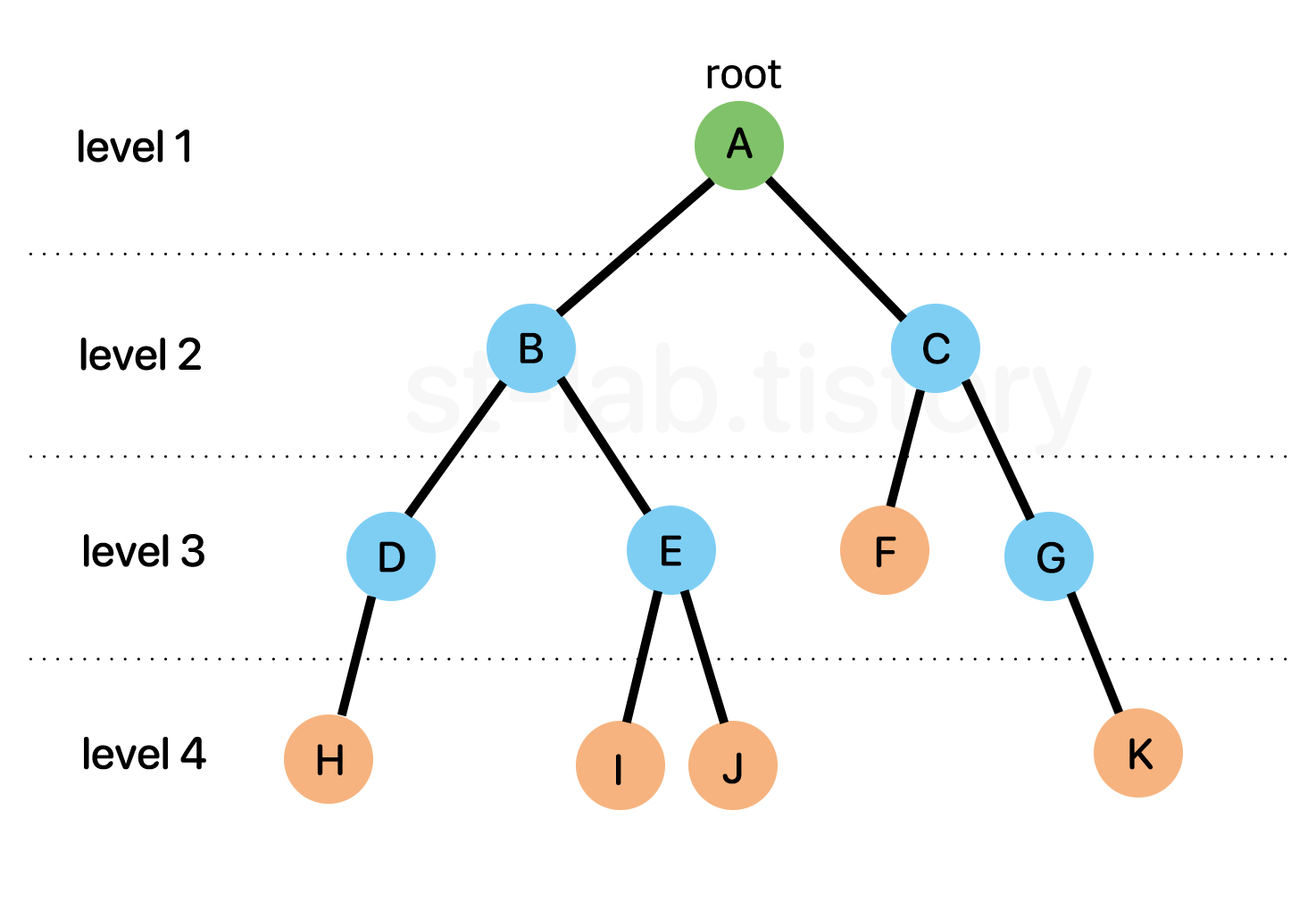
기본적으로 트리(tree)란 무엇인가?

위와같은 구조를 Tree 구조라고 한다. 위 그림을 거꾸로 보면 나무같이 생겨서 tree구조라고 한다. 여기서 Tree 구조의 각 명칭을 살펴보면 다음과 같다.
부모 노드(parent node) : 자기 자신(노드)과 연결 된 노드 중 자신보다 높은 노드를 의미 (ex. F의 부모노드 : B)
자식 노드(child node) : 자기 자신(노드)과 연결 된 노드 중 자신보다 낮은 노드를 의미 (ex. C의 자식노드 : G, H)
루트 노드 (root node) : 일명 뿌리 노드라고 하며 루트 노드는 하나의 트리에선 하나밖에 존재하지 않고, 부모노드가 없다. 위 이미지에선 녹색이 뿌리노드다.
단말 노드(leaf node) : 리프 노드라고도 불리며 자식 노드가 없는 노드를 의미한다. 위 이미지에서 주황색 노드가 단말노드다.
내부 노드(internal node) : 단말 노드를 제외한 모든 노
형제 노드(sibling node) : 부모가 같은 노드를 말한다. (ex. D, E, F는 모두 부모노드가 B이므로 D, E, F는 형제노드다.)
깊이(depth) : 특정 노드에 도달하기 위해 거쳐가야 하는 '간선의 개수'를 의미 (ex. F의 깊이 : A→B→F 이므로 깊이는 2가 됨)
레벨(level) : 특정 깊이에 있는 노드들의 집합을 말하며, 구현하는 사람에 따라 0 또는 1부터 시작한다. (ex. D, E, F, G, H)
차수(degree) : 특정 노드가 하위(자식) 노드와 연결 된 가지의 개수 (ex. B의 차수 = 3 {D, E, F} )
이 정도만 알고 있으면 된다.
그리고 위 트리 구조에서 특정한 형태로 제한을 하게 되는데, 모든 노드의 최대 차수를 2로 제한한 것이다. 조금 쉽게 말하자면 각 노드는 자식노드를 최대 2개까지 밖에 못갖는 것이다. 이를 '이진 트리(Binary Tree)'라고 한다.
위의 이미지에서는 B노드가 차수가 3이므로 이진트리가 아니다. 즉, 이진트리의 경우 다음과 같다.
그럼 이제 마지막으로 '완전 이진 트리(complete binary tree)' 에서 '완전'이라는 것은 무엇인가?
'완전 이진 트리'란 먼저 정의하자면 '마지막 레벨'을 제외한 모든 노드가 채워져있으면서 모든 노드(=사실상 마지막 레벨의 노드들)가 왼쪽부터 채워져있어야 한다.
즉, 완전 이진 트리는 이진 트리에서 두 가지 조건을 더 만족해야 하는 것이다.
- 마지막 레벨을 제외한 모든 노드가 채워져있어야함
- 모든 노드들은 왼쪽부터 채워져있어야함
그리고 완전 이진 트리에서 한 가지 조건만 더 추가하면 '포화 이진 트리(perfect binary tree)'가 된다. 바로 '마지막 레벨을 제외한 모든 노드는 두 개의 자식노드를 갖는다'라는 조건이다.

그럼 힙(Heap)은 어떻게 구현될까?
즉, 최댓값 혹은 최솟값을 어떻게 빠르게 찾아낼 수 있는가를 고민해야한다는 것이다.
예로들어보자.
어떤 리스트에 값을 넣었다가 빼낼려고 할 때, 우선순위가 높은 것 부터 빼내려고 한다면 대개 정렬을 떠올리게 된다.
쉽게 생각해서 숫자가 낮을 수록 우선순위가 높다고 가정할 때 매 번 새 원소가 들어올 때 마다 이미 리스트에 있던 원소들과 비교를 하고 정렬을 해야한다.
문제는 이렇게 하면 비효율적이기 때문에 좀 더 효율이 좋게 만들기 위하여 다음과 같은 조건을 붙였다.
'부모 노드는 항상 자식 노드보다 우선순위가 높다.'
즉, 모든 요소들을 고려하여 우선순위를 정할 필요 없이 부모 노드는 자식노드보다 항상 우선순위가 앞선다는 조건만 만족시키며 완전이진트리 형태로 채워나가는 것이다.

이를 조금만 돌려서 생각해보면 루트 노드(root node)는 항상 우선순위가 높은 노드라는 것이다. 이러한 원리로 최댓값 혹은 최솟값을 빠르게 찾아낼 수 있다는 장점(시간복잡도 : O(1))과 함께 삽입 삭제 연산시에도 부모노드가 자식노드보다 우선순위만 높으면 되므로 결국 트리의 깊이만큼만 비교를 하면 되기 때문에 O(logN) 의 시간복잡도를 갖아 매우 빠르게 수행할 수 있다.
그리고 위 이미지에서도 볼 수 있지만 부모노드와 자식노드간의 관계만 신경쓰면 되기 때문에 형제 간 우선순위는 고려되지 않는다.
이러한 정렬 상태를 흔히 '반 정렬 상태' 혹은 '느슨한 정렬 상태' , '약한 힙(weak heap)'이라고도 불린다.
"왜 형제간의 대소비교가 필요 없다는 것인가?"
힙은 우선순위가 높은 순서대로 뽑는 것이 포인트다. 즉, 원소를 넣을 때도 우선순위가 높은 순서대로 나올 수 있도록 유지가 되야하고 뽑을 때 또한 우선순위가 높은 순서 차례대로 나오기만 하면 된다.
정리하자면 힙(Heap)의 특징은 다음과 같다.
ⓐ 완전 이진 트리 구조의 형태로 우선 순위 큐를 위하여 만들어진 자료구조다.
ⓑ 여러 개의 값들 중에서 최댓값이나 최솟값을 빠르게 찾아내도록 만들어진 자료구조이다.
ⓒ 일반적으로 배열로 구현한다.
ⓓ 일종의 반 정렬 상태를 유지한다.(느슨한 정렬 상태)
ⓔ 힙 트리에서는 중복된 값을 허용한다. (이진 탐색 트리에서는 중복된 값을 허용하지 않는다.)
위의 ⓐ,ⓒ,ⓓ 특징에서 알 수 있는 것은
- 완전 이진 트리 구조이므로 전체적인 시간 복잡도를 O(logn)으로 유지할 수 있으며,
- 완전 이진 트리일 경우 노드 개수가 n일 때 높이는 logn이므로 시간 복잡도 O(logn) 유지가 가능하다.
- 트리 구조를 배열로 구현했으니 0번 Index는 편의상 사용하지 않겠구나 라는 것을 알 수 있다.
- 반 정렬 상태라는 것은, 트리 구조를 배열에 저장한 것이므로 배열로만 보았을 때는 완전히 정렬된 상태로 보이지는 않는 다는 것이다.
- 큰 값이 상위 레벨에 있고 작은 값이 하위 레벨에 있다는 정도
- 간단히 말하면 부모 노드의 키 값이 자식 노드의 키 값보다 항상 큰(작은) 이진 트리를 말한다.
Heap의 종류
앞서 힙은 우선순위가 높은 순서대로 나온다고 했다. 이 말은 어떻게 우선순위를 매기냐에 따라 달라지겠지만, 기본적으로 정수, 문자, 문자열 같은 경우 언어에서 지원하는 기본 정렬 기준들이 있다.
예로들어 정수나 문자의 경우 낮은 값이 높은 값보다 우선한다.
우리가 예로 {3, 1, 6, 4} 를 정렬한다고 하면 낮은 순서대로 {1, 3, 4, 6} 이렇게 정렬하게 된다. 이렇게 정렬되는 순서, 즉 기본적으로 어떤 것을 우선순위가 높다고 할지에 따라 두 가지로 나뉜다.

최대 힙(Max Heap)
- 부모 노드의 키 값이 자식 노드의 키 값보다 크거나 같은 완전 이진 트리
- 부모 노드의 값(key 값) ≥ 자식 노드의 값(key 값)
최소 힙(Min Heap)
- 부모 노드의 키 값이 자식 노드의 키 값보다 작거나 같은 완전 이진 트리
- 부모 노드의 값(key 값) ≤ 자식 노드의 값(key 값)
이렇게 두 가지로 나뉜다.
다만, 여기서 가장 기본으로 우선순위를 뽑는다고 하면 보통 '오름차순'을 생각하기도 하고 많은 언어들도 오름차순을 기본으로 하기 때문에 오늘을 '최소 힙'을 구현해볼 것이다. (최대 힙의 경우 비교연산자만 바꿔주면 되기 때문에 어떤 것을 구현하더라도 크게 문제는 없다.)
그럼 위의 트리 구조를 어떻게 구현할 것인가?
가장 표준적으로 구현되는 방식은 '배열' 이다. 물론 연결리스트로도 구현이 가능하긴 하지만, 문제는 특정 노드의 '검색', '이동' 과정이 조금 더 번거롭기 때문이다.
배열의 경우는 특정 인덱스에 바로 접근할 수가 있기 때문에 좀 더 효율적이기도 하다.
배열로 구현하게 되면 특징 및 장점들이 있다. 일단 아래 그림을 한 번 봐보도록 하자.

[특징]
- 구현의 용이함을 위해 시작 인덱스(root)는 1 부터 시작한다.
- 각 노드와 대응되는 배열의 인덱스는 '불변한다'
위 특징을 기준으로 각 인덱스별로 채워넣으면 특이한 성질이 나오는데 이는 다음과 같다.
[성질]
- 왼쪽 자식 노드 인덱스 = 부모 노드 인덱스 × 2
- 오른쪽 자식 노드 인덱스 = 부모 노드 인덱스 × 2 + 1
- 부모 노드 인덱스 = 자식 노드 인덱스 / 2
위 세개의 법칙은 절대 변하지 않는다.
예로들어 index 3 의 왼쪽 자식 노드를 찾고 싶다면 3 × 2를 해주면 된다. 즉 index 6 이 index 3 의 자식 노드라는 것이다.
반대로 index 5의 부모 노드를 찾고 싶다면 5 / 2 를 해주면 된다.(몫만 취함) 그러면 2 이므로 index 2가 index 5의 부모노드라는 것이다.
우선순위 큐(Priority Queue)란?
우선순위 큐는 각 요소들이 각각의 우선 순위를 갖고있고, 요소들의 대기열에서'우선 순위가 높은 요소'가 '우선 순위가 낮은 요소'보다 먼저 제공되는 자료구조다.

힙과 우선 순위 큐를 공부하면서 많은 블로그에서 보이던 개념이 "우선순위 큐 = 힙" 이라는 것이다.
어찌보면 '힙'과 유사한 구조를 갖고 있으나, 엄연히 따지자면 개념 자체는 다르다.
한번 다시 복기해보자. 힙은 '최솟값 또는 최댓값을 빠르게 찾아내기 위해 완전이진트리 형태로 만들어진 자료구조'다.
힙은 기본적으로 중점이 되는 것이 '최솟값 또는 최댓값 빠르게 찾기'인 반면에, 우선순위 큐는 우선순위가 높은 순서대로 요소를 제공받는 다는 점이다.
무슨 차이인지 잘 이해가 안갈 수도 있다. 좀 더 다른 예시를 들어보겠다.
우리는 '리스트' 자료구조를 배웠었다. 리스트는 '배열'을 이용한 ArrayList와 노드간의 연결을 이용한 LinkedList로 나뉜다. 이 둘을 '리스트'라고 흔히 부른다.
즉, 리스트라는 추상적인 자료구조 모델의 개념을 배열을 이용하느냐, 노드를 링크하는 방식을 이용하느냐를 통해 구체화 된 자료구조가 ArrayList나 LinkedList 처럼 나오는 것이다.
다른 예시도 있다.
큐(Queue)라는 자료구조에서도 배열을 이용한 방식, 다른 하나는 연결리스트로 구현한 방식이있다. 즉, 큐(Queue)라는 추상적 개념을 구체화를 어떻게 하느냐에 따라 구현 형태가 달라지게 된다.
다시 우선순위 큐로 돌아가보자.
우선순위 큐는 우선순위를 갖는 요소를 우선적으로 제공받을 수 있도록 하는 자료구조다. 이는 리스트처럼 '추상적 모델' 개념에 좀 더 가깝고, 이를 구현하는 방식은 여러 방식이 있다.
그리고 우선순위 큐를 구현하는데에 있어 가장 대표적인 구현 방식이 'Heap(힙)' 자료구조를 활용하는 방식이라는 것이다.
그래 힙(Heap)을 사용한 우선순위 큐(Priority Queue)는 어떻게 구현되냐?
해당 내용은 이미 힙에서 설명을 끝냈다.
즉, 힙에서는 '최대 혹은 최소값'을 빠르게 찾기가 목표라면 이를 우선순위가 높은 요소를 빠르게 찾기 위한다고 바꾸어 생각하면 된다.
여기서 의문이 몇 가지 있을 수 있다.
① 배열에 데이터 저장을 하고 새로 삽입할 때마다 서로 비교하면서 정렬해주면?
▶ 이 방식은 그다지 효율적이지 못하다. 왜냐하면 선형으로 처음부터 비교를 하면서 해당 자료를 삽입할 위치를 찾아야 하기 때문에 O(n)의 시간이 소요되고 n이 충분히 크다면 원하는 시간 안에 해결하기 어려울 수 있다.
② 그럼 배열에 저장하되, 퀵 정렬, 이진 탐색 같은 방식을 이용하면 훨씬 빠르게 삽입 / 추출 / 탐색도 가능하지 않을까?
▶ 맞다. 우선순위 큐는 그러한 방식을 하나의 자료구조로써 구현한 것이라고 보면 된다. 그것을 힙(Heap) 이라고도 부른다. 실제로 O(logn) 수준의 시간 복잡도를 유지한다.
위의 의문들 처럼, 우선순위 큐를 구현하는 방법은 다양한데 아래의 표를 살펴보자.
| 구현 방식 | 삽입 시 시간복잡도 | 추출 시 시간복잡도 | 설명 |
| 정렬 안된 배열 | O(1) | O(n) | 삽입은 단순 삽입, 추출 시 비교하며 추출 |
| 정렬 안된 리스트 | O(1) | O(n) | 삽입은 단순 삽입, 추출 시 비교하며 추출 |
| 정렬된 배열 | O(n) | O(1) | 삽입 시 비교하며 사십, 추출은 단순 추출 |
| 정렬된 리스트 | O(n) | O(1) | 삽입 시 비교하며 사십, 추출은 단순 추출 |
| 힙(Heap) | O(logn) | O(logn) | 삽입 / 추출 시 기존 정렬 상태 유지 |
위 표를 기반으로 우선 순위 큐는 Heap을 이용하여 구현하는 것이 효율적이다.
구현하기
여기서는 최대 힙(Max Heap)을 기준으로 진행한다. 최소 힙(Min Heap)은 아래의 코드들에서 적절히 부호만 바꾸어 주면 된다.
생성자 구성
생성자에서는 전체 데이터를 배열로 구현할 것이므로 배열을 만들어준다. 크기를 직접 지정했다면 전달하고 아니라면 기본값으로 지정한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public class PriorityQueueImpl<T extends Comparable> {
private Object array[]; // 데이터 저장 배열
private static final int DEFAULT_CAPACITY = 1000001; // 기본 100만개 설정
private int capacity; // 사용자가 지정한 최대 데이터 입력 수
private int size = 0; // 현재 입력된 데이터 수
private int lastIndex = 0; // 마지막으로 입력된 데이터의 index
public PriorityQueueImpl() {
new PriorityQueue(this.DEFAULT_CAPACITY);
}
public PriorityQueueImpl(int capacity) {
this.capacity = capacity + 1; // 0번 인덱스는 사용하지 않으므로 +1
this.array = new Object[this.capacity];
}
}
|
cs |
데이터 삽입(insert)
데이터를 삽입 시에는 기존의 배열이 비어있었다면 단순히 루트 노드에 삽입하면 된다. 하지만 기존 데이터들이 이미 있는 상태에서는 위치를 바꾸어주는 작업이 필요하다.
아래의 그림을 통해 새로운 값 11을 삽입하고자 한다고 하자.
이때 새로운 값은 트리의 가장 끝 위치에 데이터 삽입한다.

만약 새롭게 넣고자 하는 값이 5이하의 숫자였다면 단순히 해당 위치에 삽입을 해도 상관없을 것이다.
만약 그랬다면 부모 노드의 Index가 5인데 좌측 자식 노드는 이미 데이터가 있으니, 우측 자식으로 단순히 삽입하면 된다.
여기서 트리 노드 인덱스에 대해 복습하자면, 0번 Index를 사용하지 않는 경우 부모와 자식 노드의 관계는 다음과 같다.
- 부모 노드 Index : n
- 좌측 자식 노드 Index : n*2
- 우측 자식 노드 Index : n*2+1
하지만 최대 힙은 숫자가 클 수록 우선순위가 높은데 11이라는 숫자는 현재 저장된 어떠한 숫자보다도 우선순위가 높다.
따라서 재정렬을 하는 Heapify 과정이 필요하다. 해당 과정이 Heap 정렬이라고도 한다.
Heapify는 힙을 고친다라는 의미로, 현재 삽입 혹은 삭제될 노드에 의해 전체 정렬 상태에 영향이 생길 경우 그 정렬을 다시 올바르게 진행하기 위한 절차를 의미한다.
현재 노드보다 상단으로 힙을 고쳐야 한다면 Above Heapify, 하단으로 힙을 고쳐야 한다면 Below Heapify라고 부른다.
삽입 시에는 가장 마지막 배열 위치에 값을 우선 넣고 진행하므로 상단으로 힙을 재정렬해야 한다. 그림으로 간단히 삽입 후 Above Heapify를 하는 과정을 이해해보자.


데이터 삽입 부분을 코드로 진행하면 다음과 같다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
public boolean insert(T data) {
// 현재 Heap이 꽉 찼다면 배열 크기를 2배로 만든다.
if (capacity - 1 == size) {
makeDouble();
}
array[++lastIndex] = data;
aboveHeapify(lastIndex); // 상단 방향으로 재정렬
size++; // 현재 전체 크기 증가
return true;
}
private void makeDouble() {
this.capacity = this.capacity * 2 + 1;
Object[] newArray = new Object[this.capacity];
// 데이터 복사
System.arraycopy(this.array, 0, newArray, 0, this.lastIndex);
this.array = newArray; // 포인터 이동
}
|
cs |
데이터 상향 재정렬(Heapify)
삽입을 할때 데이터 재정렬이 필요한 경우가 있다는 것을 확인할 수 있었다.
아래 코드와 같이 Heapify는 부모 노드와 비교하여 현재 데이터가 더 우선순위 상으로 높다면 위치를 바꾸어주는 방식이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
private void aboveHeapify(int startIndex) {
T relocateData = (T)this.array[startIndex]; // 재정렬하려는 데이터
int current = startIndex; // 삽입하려는 데이터의 현재 위치(배열 맨 마지막)
// Index가 Root에 다다르지 않고 부모 데이터보다 현재 데이터가 더 크면
while(current > 1 && relocateData.compareTo((T)this.array[current/2]) > 0){
// 부모 데이터를 현재 위치에 저장
this.array[current] = (T)this.array[current/2];
// 현재 인덱스에서 부모로 이동
current /= 2;
}
// 부모로 이동한 current에 재정렬하려는 데이터 삽입
this.array[current] = relocateData;
}
|
cs |
데이터 추출(pop)
데이터를 저장했으니 이제 우선순위에 맞게 내부의 특정 데이터를 얻을 수 있어야한다.
애초에 우선순위 큐를 사용하는 이유가 우선순위 대로 데이터를 얻기 위해서이기 때문에 현재 최우선 순위 상태가 아닌 데이터를 먼저 추출하고자 하는 경우는 거의 없다. 그러나 예외의 경우가 있을 수 있으니 그에 대한 코드도 같이 구현하도록 하겠다.
일단, 추출 시의 로직을 다음과 같다.
현재 최우선 순위의 데이터를 추출해냈다면 배열의 가장 마지막에 있는 데이터를 최우선 순위 위치로 가져다 놓는다. 그 다음 아래 방향으로 재정렬(Heapify)를 진행하면 된다.
그림으로 이해해보자.


위의 내용을 코드로써 구현하면 아래와 같다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
// 비어있는 상태인지 확인
public boolean isEmpty() {
return this.size == 0;
}
// 가장 우선 순위인 데이터 추출
public T pop(){
if(isEmpty()){
throw new NullPointerException();
}
// 1번 인덱스가 가장 우선 순위인 데이터 이므로 전달.
return pop((T)this.array[1]);
}
// 특정 데이터 추출
public T pop(T data){
if(isEmpty()){
throw new NullPointerException();
}
int targetIndex = find(data);
// 만약 그런 데이터가 없다면
if(targetIndex == -1){
throw new NullPointerException();
}
// 반환할 데이터 미리 저장
T resultData = (T)this.array[targetIndex];
// 만약 가장 마지막에 저장된 데이터를 추추랗려는 경우라면 그냥 추출
if(targetIndex == lastIndex){
this.array[this.lastIndex--] = null;
this.size--;
return resultData;
}
// 가장 마지막에 저장된 데이터를 가져온다. 마지막 index값은 수정.
T rightMostData = (T)this.array[this.lastIndex];
this.array[this.lastIndex--] = null;
// 최 우즉 데이터를 현재 제거될 위치의 데이터가 있는 자리에 넣는다.
// 가장 상위의 위치는 마지막 노드를 가져와서 삽입
this.array[targetIndex] = rightMostData;
// 루트 데이터가 추출되는 경우 or 부모 데이터보다 대체된 데이터가 더 작다면 아래로 Heapify
if(targetIndex == 1 || rightMostData.compareTo((T)this.array[targetIndex/2]) < 0){
belowHeapify(targetIndex);
}else{ // 아니라면 위로 Heapify
aboveHeapify(targetIndex);
}
this.size--;
return resultData;
}
// 특정 데이터 위치 파악.
public int find(T data){
for(int i=1; i <= this.size; i++){
if(this.array[i].equals(data)){
return i;
}
}
return -1;
}
|
cs |
데이터 하향 재정렬(Heapify)
하향 재정렬도 기본적으로 원리는 같은데, 상향 재정렬과 다른 점은 하향 재정렬은 비교 대상이 2개라는 것이다.
즉, 좌측 / 우측 자식 데이터와 비교를 해야하는데 이 때 3가지 가능성이 있다.
⑴ 좌측 / 우측 자식 데이터가 모두 없는 경우
⑵ 좌측 자식 데이터만 있는 경우
⑶ 좌측 / 우측 자식 데이터가 모두 있는 경우
완전 이진 트리이기 때문에 우측 자식 데이터만 있는 경우는 없다.
⑴ 자식 데이터가 없으면 리프(Leaf) 데이터이므로 재정렬이 불필요하다.
⑵ 좌측 자식 데이터가 있고 그 데이터가 더 크다면 상호 교환한다.
⑶ 모든 자식 데이터가 있으면 더 큰 자식 데이터와 비교하여 해당 데이터가 자신보다 크다면 교환한다.
이를 코드로 작성하면 아래와 같다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
private void belowHeapify(int startIndex) {
T relocateData = (T) this.array[startIndex];
int current = startIndex;
// 마지막 Index보다 작거나 같을 때까지 진행
while (current <= lastIndex) {
int leftIndex = current * 2;
int rightIndex = current * 2 + 1;
// 현재 Leaf 위치라면 더 이상 비교할 필요 없음.
if (leftIndex > lastIndex) {
break;
} else { // leftIndex <= lastIndex
T leftChild = (T) this.array[leftIndex];
// 오른쪽 자식 검증.
// 마지막 인덱스를 벗어났으면 오른쪽 child는 없다는 것.
T rightChild = rightIndex > this.lastIndex ? null : (T) this.array[rightIndex];
// 우측 자식이 없고 좌측 자식이 더 값이 크다면 위치를 바꾼다.
if (rightChild == null) {
if (leftChild.compareTo(relocateData) > 0) {
this.array[current] = leftChild;
this.array[leftIndex] = relocateData;
current = leftIndex;
} else {
break;
}
} else { // 우측, 좌측 둘다 자식이 있는 경우
T targetToSwap = leftChild.compareTo(rightChild) > 0 ? leftChild : rightChild;
int swapIndex = leftChild.compareTo(rightChild) > 0 ? leftIndex : rightIndex;
if (targetToSwap.compareTo(relocateData) > 0) {
this.array[current] = targetToSwap;
this.array[swapIndex] = relocateData;
}
current = swapIndex;
}
}
}
}
|
cs |
자바 Collection Framework 내의 우선 순위 큐 사용하기
이제 자바에서 어떻게 우선 순위 큐를 생성, 데이터 저장 및 추출, 정렬 방식 지정 등을 하는 법을 알아보자.
① 기본 생성, 최소/최대힙 정렬하기
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
package com.test;
import java.util.PriorityQueue;
import java.util.Collections;
public class PriorityQueueTest{
public static void main(String[] args) {
// 숫자를 저장하는 우선 순위 큐 생성
PriorityQueue<Integer> pq = new PriorityQueue<>();
pq.add(10);
pq.add(5);
pq.add(30);
pq.add(27);
pq.add(13);
// 위와 같이 저장하면 기본적으로 최소힙(최소값이 우선 순위)로 저장된다.
// 아래와 같이 출력해보자.
while(!pq.isEmpty()){
System.out.print(pq.poll() + ", "); // 5, 10, 13, 27, 30
}
System.out.println();
// 이를 최대힙으로 저장하도록 하려면 아래와 같이 진행한다.
// reverseOrder를 통해 최대힙으로 구성되도록 한다.
pq = new PriorityQueue<>(Collections.reverseOrder());
pq.add(10);
pq.add(5);
pq.add(30);
pq.add(27);
pq.add(13);
// 위와 같이 저장하면 기본적으로 최대힙(최대값이 우선 순위)로 저장된다
// 아래와 같이 출력해보자.
while(!pq.isEmpty()){
System.out.print(pq.poll() + ", "); // 5, 10, 13, 27, 30
}
}
}
|
cs |
② Comparator를 이용하여 정렬 순서 지정하기
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
package com.test;
import java.util.PriorityQueue;
import java.util.Collections;
import java.util.Comparator;
public class PriorityQueueTest{
public static void main(String[] args) {
// Test Class의 Object를 저장하는 우선 순위 큐 생성
PriorityQueue<Test> pq = new PriorityQueue();
// Test Object 저장
pq.add(new Test(10, "Banana"));
pq.add(new Test(5, "Apple"));
pq.add(new Test(8, "Kiwi"));
pq.add(new Test(30, "Lemon"));
pq.add(new Test(2, "Melon"));
// 정렬 방식은 아래 Test Class를 확인
// 출력 결과 : [2 : Melon], [5 : Apple], [8 : Kiwi], [10 : Banana], [30 : Lemon],
while(!pq.isEmpty()){
System.out.print(pq.poll() + ", ");
}
System.out.println();
// Comparator를 이용하여 별도의 방식으로 저장하기
// 각 String의 길이를 기반으로 하는 경우
pq = new PriorityQueue(new Comparator<Test>(){
@Override
public int compare(Test t1, Test t2){
return t1.s.length() - t2.s.length();
}
});
// Test Object 저장
pq.add(new Test(10, "3자리"));
pq.add(new Test(5, "5자리!~"));
pq.add(new Test(8, "4자리!"));
pq.add(new Test(30, "1"));
pq.add(new Test(2, "7자리는어떨까"));
// 아래 출력 결과
// [30 : 1], [10 : 3자리], [8 : 4자리!], [5 : 5자리!~], [2 : 7자리는어떨까],
while(!pq.isEmpty()){
System.out.print(pq.poll() + ", ");
}
}
}
// 비교 대상을 만들기 위한 Class
class Test implements Comparable<Test>{
int a;
String s;
public Test(int a, String s){
this.a=a;
this.s=s;
}
// 아래와 같이 Comparable을 구현하였기에 오름차순으로 구현된다.
// 내림차순으로 하고 싶다면 o.a - this.a 로 한다.
// 만약 String을 기반으로 오름차순으로 하는 경우는 this.s.compare(o.s);
// 만약 String을 기반으로 내림차순으로 하는 경우는 o.s.compare(this.s);
@Override
public int compareTo(Test o) {
return this.a - o.a;
}
@Override
public String toString() {
return "[" + this.a + " : " + this.s + "]";
}
}
|
cs |
참고